Thanks for coming to AIE - full Day 1 and Day 2 streams are available, with 6 other livestreamed tracks. You can binge this weekend! Longer recap when we have slept.
Emmanuel Amiesen is lead author of “Circuit Tracing: Revealing Computational Graphs in Language Models”, which is part of a duo of MechInterp papers that Anthropic published in March (alongside On the Biology of LLMs).
We recorded the initial conversation a month ago, but then held off publishing until the open source tooling for the graph generation discussed in this work was released last week in collaboration with Neuronpedia:
This is a 2 part episode - an intro covering the open source release, then a deeper dive into the paper — with guest host Vibhu Sapra and Mochi the MechInterp Pomsky. Thanks to Vibhu for making this episode happen!
While the original blogpost contained some fantastic guided visualizations (which we discuss at the end of this pod!), with the notebook and Neuronpedia visualization released this week, you can now explore on your own with Neuronpedia, as we show you in the video version of this pod.
Full Version on YouTube
Timestamps
- 00:00 Intro & Guest Introductions
- 01:00 Anthropic's Circuit Tracing Release
- 06:11 Exploring Circuit Tracing Tools & Demos
- 13:01 Model Behaviors and User Experiments
- 17:02 Behind the Research: Team and Community
- 24:19 Main Episode Start: Mech Interp Backgrounds
- 25:56 Getting Into Mech Interp Research
- 31:52 History and Foundations of Mech Interp
- 37:05 Core Concepts: Superposition & Features
- 39:54 Applications & Interventions in Models
- 45:59 Challenges & Open Questions in Interpretability
- 57:15 Understanding Model Mechanisms: Circuits & Reasoning
- 01:04:24 Model Planning, Reasoning, and Attribution Graphs
- 01:30:52 Faithfulness, Deception, and Parallel Circuits
- 01:40:16 Publishing Risks, Open Research, and Visualization
- 01:49:33 Barriers, Vision, and Call to Action
Transcript
swyx [00:00:03]: All right, we are back in the studio with a couple of special guests. One, Vibhu, our guest co-host for a couple of times now, as well as Mochi the Distilled Husky is in the studio with us to ask some very pressing questions. As well as Emmanuel, I didn't get your last name, Amason? Yep. Is that Dutch? It's actually German. German? Yeah. You are the lead author of a fair number of the recent Macintyre work from Anthropic that I've been basically calling Transformer Circuits, because that's the name of the publication.
Emmanuel [00:00:35]: Yeah. Well, to be clear, Transformer Circuits is the whole publication. I'm the author on one of the recent papers, Circuit Tracing. Yes.
swyx [00:00:42]: And people are very excited about that. The other name for it is like Tracing the Thoughts of LLMs. There's like three different names for this work. But it's all Macintyre.
Emmanuel [00:00:49]: It's all Macintyre. There's two papers. One is Circuit Tracing. It's the methods. One is like the biology, which is kind of what we found in the model. And then Tracing the Thoughts is confusingly just the name of the blog post. Yeah.
swyx [00:01:01]: It's for different audiences. Yes. Yes. And I think when you produce the like two minute polished video that you guys did,
Emmanuel [00:01:07]: that's meant for like a very wide audience, you know? Yeah, that's right. There's sort of like very many levels of granularity at which you can go. And I think for Macintyre in particular, because it's kind of complicated going, you know, from like top to bottom, most like high level to sort of the dernali details works pretty well. Yeah.
swyx [00:01:24]: Cool. We can get started. Basically, we have two paths that you can choose, like either your personal journey into Macintyre or the, the brief history of Macintyre, just generally, and maybe that might coincide a little bit.
Emmanuel [00:01:36]: I think my, okay, I could just give you my personal journey very quickly, because then we can just do the second path. My personal journey is that I was working at Anthropic for a while. I'd been like many people just following Macintyre as sort of like an interesting field with fascinating, often beautiful papers. And I was at the time working on fine tuning. So like actually fine tuning production models for Anthropic. And eventually I got both like sort of like, like my fascination reached a sufficient level that I decided I wanted to work on it. And also I got more excited about just as our models got better and better understanding how they worked. So that's the simple journey. I've got like a background in ML, kind of like did a lot of applied ML stuff before. And now I'm doing more research stuff. Yeah.
swyx [00:02:20]: You have a book with O'Reilly. You're head of AI at Insight Data Science. Anything else to plug?
Emmanuel [00:02:25]: Yeah. I actually, I want to like plug the paper and unplug the book. Okay. I think the book, is good. I think the advice stands the test of time, but it's very much like, Hey, you're building like AI products, which do you focus on? It's like very different, I guess is all I'll say from, from the stuff that we're talking to talk about today. Today is like research. Some of, some of the sort of like deepest, weirdest things about how like models work. And this book is you want to ship a random forest to do fraud classification. Like here are the top five mistakes to avoid. Yeah.
swyx [00:02:55]: The good old days of ML. I know it was simple back then. You also transition into research. And I think you also did then, like I feel like there's this monolith of like people assume you need a PhD for research. Maybe can you give like that perspective of like, how do people get into research? How do you get into research? Maybe that gives audience insight into Vibo as well. Your background.
Vibhu [00:03:16]: Yeah. My background was in like economics, data science. I thought LLMs were pretty interesting. I started out with some basic ML stuff and then I saw LLMs were starting to be a thing. So I just went out there and did it. And same thing with AI engineering, right? You just kind of build stuff. You work on interesting, interesting things and like now it's more accessible than ever. Like back when I got into the field five, six years ago, like pre-training was still pretty new. GPT-3 hadn't really launched. So it was still very early days and it was a lot less competitive, but yeah, without any specific background, no PhD, there just weren't as many people working on it, but you made the transition a little bit more recently, right? So what's your experience been like? Yeah,
Emmanuel [00:03:55]: I think, I think it has maybe never been easier in some ways because, um, a lot of the field is like pretty empirical right now. So I think the better lesson is like this lesson that, you know, you can just sort of like a lot of times scale up compute and data and get better results than like thinking than if you sort of like thought extremely hard about a really good, like prior inspired by the human brain to, to train your model better. And so in terms of definitely like research for pre-training and fine tuning, I think it's just sort of like a lot of the bottlenecks are extremely good engineering and systems engineering. And a lot even of the research execution is just about sort of like engineering and scaling up and things like that. I think for Interp in particular, there's like another thing that makes it easier to transition to it too, which is maybe two things. One, you can just do it without huge access to compute. Like there are open source models. You can look at them. A lot of Interp papers, you know, coming out of programs like maths are on models that are open source that you can serve like dissect without having a cluster of like, you know, a hundred GPUs. You can just even, sometimes you can load them like on your CPU, on your MacBook. And it's also a relatively new field. And so, you know, there's, as I'm sure we'll talk about, there's like some conceptual burdens and concepts that you just want to like understand before you contribute, but it's not, you know, physics. It's relatively recent. And so the number of abstractions that you have to like ramp up on is just not that high compared to other fields, which I think makes that transition somewhat easier for Interp. If you understand, we'll talk about all these, I'm sure, but like what, what the features are and what dictionary learning is. You're like a long part of the way there.
swyx [00:05:35]: I think it's also interesting just on a careerist point of view, research seems a lot more valuable than engineering. So I wonder, and you don't have to answer this if it's like a tricky thing, but like how hard is it for a, for a research engineer in Anthropic to jump the wall into research? People seem to move around a lot and I'm like there, that cannot be so easy. Like, like in no other industry that I know of people, you can do that. Do you know what I mean? Yeah.
Emmanuel [00:06:05]: I think I'd actually like I'd push back on the sort of like research being more valuable than engineering a little bit, because I think a lot of times, like having the research idea is not the hardest part. Don't get me wrong. There's some ideas that are like brilliant and hard to find, but what's, what's hard, certainly on fine tuning and to a certain extent on Interp is executing on your research idea in terms of, like making an experiment successfully, like having your experiment run, interpreting it correctly. What that means though, is that like they're not separate skill sets. So like if you have a cool idea, there's kind of not many people in the world, I think where they can just like have a cool idea and then they have a, you know, like a little minion they'll deputize being like, here's my idea, you know, go off for three months and like run this whole day, like build this model and train it for, you know, hundreds of hours and report back on what happened. A lot of the time, like the people that are the most productive, they have an idea, but they're also extremely quick. Uh, checking their idea of finding sort of like the shortest path to, to turn it already. And a lot of like that shortest path is engineering skills essentially. It's just like getting stuff done. And so I think that's why you see sort of like people move around as like proportionate to your interest. If you're just able to quickly execute on the ideas you have and get results, then that's really the 90% of the value. And so you see a lot of transferable skills, actually, I think from, from people like I've certainly seen an anthropic that are just like really good at that, you know, they can apply it in one team and then move to a completely different domain and apply that inner loop just as well. Yeah.
swyx [00:07:35]: Very cracked is the kids say, uh, shall we move to the history of McInturk? Yeah. All I know is that everyone starts at Chris Ola's blog. Is that right? And yeah,
Emmanuel [00:07:45]: I think that's the correct answer. Chris Ola's blog. And then, you know, uh, distill.pub, uh, is the sort of natural next step. And then I would say, you know, now there's for anthropic, there's transformer circuits, which you talked about. but there's also just a lot of McInturk research out there from, you know, I think like the, yeah, like maths is a group with that, like regularly has a lot of research, but there's just like many different labs that, that put research out there. And I think that's also just like hammer home the point that's because all you need is like a model and then a willingness to kind of investigate it to be able to contribute to it. So, so now it's like, there's been a bit of a Cameron explosion of McInturk, which is cool. I guess the history of it is just, you know, computational like models that are not decision trees models that are either CNNs or let's say transformers have just this w really like strange property that they don't give you interpretable intermediate States by default. You know, again, to go back to if you were training like a decision tree on like fraud data for an old school, like bank or something, then you can just look at your decision tree and be like, oh, it's learned that like if you make a, I don't know if this transaction is more than $10,000, and it's for like perfume, then maybe it's fraud or something. You can look at it and say like, cool, like that makes sense. I'm willing to ship that model. But for, for things like, like CNNs and like transformers, we, we don't have that right. What we have at the end of training is just a massive amount of weights that are connected somehow or activations that are connected by some weights. And who knows what these weights mean or what the intermediate activations mean. And so the quest is to understand that initially it was done. A lot of it was on a vision models where you sort of have, the emergence of a lot of these ideas, like what are features, what are circuits. And then more recently it's been mostly or not most, yeah, mostly applied to NLP models, but also, you know, still there's work in vision and there's work in like a bio and other domains. Yeah.
swyx [00:09:44]: I'm on Chris Ola's blog and he has like the feature visualization stuff. I think for me, the clearest was like the vision work where you could have like this layer detects edges, this layer detects textures, whatever. That seemed very clear to me, but the transition to language models seem, like a big leap.
Emmanuel [00:10:00]: I think one, one of the bigger changes from vision to, to like language models has to do with the superposition hypothesis, which maybe is like, that's the first in like toy models post, right? Exactly. And this is sort of like, it turns out that if you look at just the neurons of a lot of vision models, you can see neurons that are curve detectors or that are edge detectors or that are high, low frequency detectors. And so you can sort of like make sense of the neurons. Mostly. But if you look at neurons in language models, most of them don't make sense. It's kind of like unclear why, or it wasn't clear why that would be. And one main like hypothesis here is the superposition hypothesis. So what does that mean? That means that like language models pack a lot more in less space than vision models. So maybe like a, a kind of like really hand wavy analogy, right? Is like, well, if you want curve detectors, like you don't need that many curve detectors, you know, if each, each curve detector is going to detect like a quarter or a 12th of a circle, like, okay, well you have all your curve detectors, but think about all of the concepts that like Claude or even GPT-2 needs to know, like just in terms of, it needs to know about like all of the different colors, all the different hours of every day, all of the different cities in the world, all of the different streets on every city. If you just enumerate all of the facts that like a model knows, you're going to get like a very, very long list. And that list is going to be way bigger than like the number, of neurons or even the like size of the residual stream, which is where like the models process information. And so there's this sense in which like, oh, there's more information than there's like dimensions to represent it. And that is much more true for language models than for vision models. And so, because of that, when you look at a part of it, it just seems like it's like, there's, it's got all this stuff crammed into it. Whereas if you look at the vision models, oftentimes you could just like, yeah, cool. This is a curve detector.
swyx [00:11:53]: Yeah. Yeah. VB, you have like some fun ways of explaining the toy models or super, superposition concept. Yeah.
Vibhu [00:11:59]: I mean, basically like, you know, if you have two neurons and they can represent five features, like a lot of the early Mechinterp work says that, you know, there are more features than we have neurons. Right. So I guess my kind of question on this is for those interested in getting into the field, what are like the key terms that they should know? What are like the few pieces that they should follow? Right. Like from the anthropic side, we had a toy transformer model. We had sparse, we first had auto encoders. That was the second paper.
swyx [00:12:25]: Um,
Vibhu [00:12:25]: right. Yeah. Monosyntheticity. Yeah. What is sparsity in auto encoders? What are trans coders? Like what is linear probing? What are these kind of like key points that we had in Mechinterp? And just kind of, how would people get a quick, you know, zero to like 80% of the field? Okay.
Emmanuel [00:12:42]: So zero to 80%. And I realized I really like set myself up for, for failure. So I was like, yeah, it's easy. There's not that much to know. So, okay. So then, then we should be able to cover it all. Um, so superposition is the first thing you should know, right? This idea that like there's a bunch of stuff crammed in a few dimensions, as you said, maybe you have like two neurons and you want to represent five things. So if that's true, and if you want to understand how the model represents, you know, I don't know the concept of red, let's say then you need some way to like find out essentially in which direction the model stores it. So after the, the server, like superposition hypothesis, you can think of like, ah, we also think that like basically the model represents these like individual concepts, we're going to call them features as like directions. So if you have two neurons, you can think of it as like, it's like the two D plane. And it's like, ah, you can have like five directions and maybe you would like arrange them like the spokes of a wheel. So they're sort of like maximally separate. It could mean that like you have one concept that this way and one concept that's like not fully perpendicular to it, but like pretty, pretty like far from it. And then that would like allow the model to represent more concepts and it has dimensions. And so if that's true, then what you want is you want like a model that can extract these independent concepts. And ideally you want to do this like automatically. Like, can we just, you know, have a model that tells us like, oh, like this direction is red. If you go that way, actually it's like, I don't know, chicken. And if you go that way, it's like the declaration of independence, you know? Um, and so that's what sparse auto encoders are.
swyx [00:14:09]: It's almost like the, the self supervised learning insight version, like in, in pre-training itself, supervised learning and here and now it's so self supervised interpretability. Yeah,
Emmanuel [00:14:18]: exactly. Exactly. It's like an unsupervised method. Yeah. And so unsupervised methods often still have like labels in the end or so.
swyx [00:14:25]: So sometimes I feel like the term labels by masking. Yeah.
Emmanuel [00:14:29]: Like for, for pre-training, right? It's like the next token. So in that sense, you have a supervision signal and here the supervision signal is simply, you take the like neurons and then you learn a model. That's going to like expand them into like the actual number of concepts that you think there are in the model. So you have two neurons, you think there's five concepts. So you expand it to like, I think of dimension five. And then you contract, it back to what it was. That's like the model you're training. And then you're training it to incentivize it to be sparse. So that there's only like a few features active at a time. And once you do that, if it works, you have this sort of like nice dictionary, which you can think as like a way to decode deactivate the neurons where you're saying like, ah, cool. I don't know what this, what this direction means, but I've like used my model into telling me that the model is writing in the red direction. And so that's, that's sort of like, I think maybe the biggest thing to understand is, is this, this combination of things of like, ah, we have too few dimensions. We pack a lot into it. So we're going to learn an unsupervised way to like unpack it and then analyze what each of those dimensions that we've unpacked are.
Vibhu [00:15:31]: Any follow-ups? Yeah. I mean, the follow-ups of this are also kind of like some of the work that you did is in clamping, right? What is the applicable side of MechInterp, right? So we saw that you guys have like great visualizations. Golden Gate Cloud was a cool example. I was going to say that. Yeah. It's my favorite. What can we do once we find these features? Finding features is cool. But what can we do about it? Yeah.
Emmanuel [00:15:53]: I think there's kind of like two big aspects of this. Like one is, yeah. Okay. So we go from a state where, as I said, the model is like a mess of weights. We have no idea what's going on to, okay. We found features. We found a feature for red, a feature for Golden Gate Cloud or for the Golden Gate Bridge, I should say. Like, what do we do with them? And well, if these are true features, that means that like they, in some sense are, are important for the model or it wouldn't be like representing it. Like if the model is like bothering to, to like write, you know, in the Golden Gate Bridge direction, it's usually because it's going to like talk about the Golden Gate Bridge. And so that means that like, if that's true, then you can like set that feature to zero or artificially set to a hundred and you'll change the model behavior. That's what we did when we did Golden Gate Cloud in which we found a feature that represents the direction for the Golden Gate Bridge. And then we just like set it to always be on. And then you could talk to Claude and be like, Hey, like, Oh, what's on your mind? You know, like, what are you thinking about today? Be like the Golden Gate Bridge. You'd be like, Hey Claude, like what's two plus two, it'd be like four Golden Gate Bridges, uh, et cetera. Right. And it was always thinking about this,
swyx [00:16:55]: like write a poem and it just starts talking about how it's like red, like the Golden Gate plot. That's right. Golden Gate Bridge. Yeah,
Emmanuel [00:17:00]: that's right. Amazing. I think what made it even better is like, we realized later on that it wasn't really like a Golden Gate Bridge feature. It was like being in awe at the beauty of the majestic Golden Gate Bridge. Right. So I'll tell you, I would like really ham it up. You'd be like, Oh, I'm just thinking about the beautiful international orange color of the Golden Gate Bridge. That was just like an example that I think was like really striking, but of, of sort of like, Oh, if you found like a space where that represents some computation or some representation of the model, that means that you can like artificially suppress or promote it. And that means that like you're starting to understand at a very high level, a very gross level, like how some of them all works. Right. We've gone from like, I don't know anything about it to like, Oh, I know that this like combination of neurons, neurons is this, and I'm going to prove it to you. The next step, which is what this, this works on is like, that's kind of like thinking of if maybe you take the analogy of like, um, I don't know, like, like let's take the energy of like an MRI or something like a brain scan. It tells you like, Oh, like this as Claude was answering at some point, it thought about this thing, but it's a sort of like vague, like maybe, basically maybe it's like a, like a bag of words, kind of like a bag of features. You just have like, here are all the random things that thought about, but what you might want to know is like, what's this thing like sometimes to get to the golden gate bridge, it had to realize that you were talking about San Francisco and about like the best way to go to Sonoma or something. And so that's how it got to golden gate bridge. So there's like an algorithm that leads to it at some point, thinking about the golden gate bridge. And basically like, there's like a way to connect features to say like, Oh, from this input went to these few features and then these few features and then these few features and that one influenced this one. And then you got to the output. And so that's the second part. And the part we worked on is like you have the features now connect them in what we call a, or what's called, circuits, which is sort of like explaining the, the like algorithm. Yeah.
swyx [00:18:46]: Before we move directly onto your work, I just want to give a shout out to Neil Nanda. He did neuron Pedia and released a bunch of essays for,
Emmanuel [00:18:54]: I think the llama models and the Gemma models and the Gemma models. Yeah.
swyx [00:18:57]: So I actually made golden gate Gemma just up the weights for proper nouns and names of places of people and references to the term golden likely relating to awards, honors, or special names. And that together made golden gate. That's amazing. So you can make golden gate Gemma. And like, I think that's a, that's a fun way to experiment with this. Uh, but yeah, we can move on to, I'm curious.
Vibhu [00:19:19]: I'm curious. What's the background behind why you ship golden gate claw? Like you had so many features, just any fun story behind why that's the one that made it.
Emmanuel [00:19:28]: You know, it's funny if you look at the paper, there's just a bunch of like, yeah, like really interesting features, right? There's like one of my favorite ones was the psychophantic praise, which I guess is very topical right now.
swyx [00:19:40]: Topical.
Emmanuel [00:19:40]: Um, but you know, it's like you could dial that up and like Claude would just really praise you. You'd be like, Oh, you know, like I wrote this poem, like roses are red, violets are blue, whatever. And it'd be like, that's the best poem I've ever seen. Um, and so we could have shipped that. That could have been funny. Uh, golden gate. Claude, it was like a pure, as far as I remember, at least like a pure, just like weird random thing where like somebody found it initially with an internal demo of it. Everybody thought it was hilarious. And then that's sort of how it came on. There was, there was no, nobody had a list of top 10 features we should consider shipping. And we picked that one. There was just kind of like a very organic moment. No,
swyx [00:20:18]: like the, the marketing team really leaned into it. Like they mailed out pieces of the golden gate for people in Europe, I think, or ICML. Yeah, it was, it was fantastic marketing. Yeah. The question obviously is like if open AI had invested more interpretability, would they have caught, uh, the GPT for all update? Uh, but we don't know that for sure. Cause they have interp teams. They just,
Emmanuel [00:20:39]: yeah. I think also like for that one, I don't know that you need interp. Like it was pretty clear cut to the model. I was like, oh, that model is really gassing me up.
swyx [00:20:46]: And then the other thing is, um, can you just like up, write good code, don't write bad code and make Sonda 3.5. And like, it feels too, too easy to free. Is that steering that powerful?
Vibhu [00:20:59]: You can just like up and down features with no trade-offs. There was quite a, there was like a phase where people were basically saying, you know, 3.5 and 3.7 are just now because they came out right.
swyx [00:21:09]: And for the record, like that's been debunked.
Vibhu [00:21:11]: But it has been debunked, but you know, it had people convinced that what people did is they basically just steered up and steered down features. And now we have a better model. And this kind of goes back to that original question of, right? Like, why do we do this? What can we do? Some people are like, I want tracing from a sense of, you know, legality. Like what did the model think when it came to this output? Some people want to turn hallucination down. Some people want to turn coding up. So like, what are some, like whether it's internal, what are you exploring that? Like what are the applications of this, whether it's open, ended of what people can do about this or just like, yeah. Why, why do McInturpp, you know? Yeah.
Emmanuel [00:21:46]: There's like a few things here. So, so like, first of all, obviously this is, I would say on the scale of the most short term to the most long term, like pretty long term research. So in terms of like applications compared to, you know, like the research work we do on like fine tuning or whatever interp is much more, you know, sort of like a high risk, high reward kind of approach. With that being said, like, I think there's just a fundamental sense in which, which Michael Nielsen had had a post recently about how like knowledge is dual use or something, but just like, just like knowing how the model works at all feels useful. And you know, it's hard to argue that if we know how the model works and understand all of the components that won't help us like make models that hallucinate less, for example, or they're like less biased, that seems, you know, if, if like at the limit, yeah, that totally seems like something you would do using basically like your understanding of the model to improve it. I think for now, as we can talk about a little bit with like circuits, there's like, we're still pretty early on in the game, right? And so right now the main way that we're using interp really is like to investigate specific behaviors and understand them and gain a sense for what's causing them. So like one example that we, we can talk about later, we can talk about now, but is this like in the paper, we investigate jailbreaks and we try to see like, why does a jailbreak work? And then we realize as we're looking at this jailbreak, that part of the reason why Claude is telling you how to make a bomb in this case, is that it's like already started to tell you how to make a bomb. And it would really love to stop telling you how to make a bomb, but it has to first finish its sentence. Like it really wants to make correct grammatical sentences. And so it turns out that like seeing that circuit, we were like, ah, then does that mean if I prevent it from finishing a sentence, the jailbreak works even better? And sure enough, it does. And so I think like the level of sort of practical application right now is of that shape. So like understanding either like quirks of a current model, or like, or like how it does tasks that maybe we don't, we don't even know how it does it. Like, you know, we have like some planning examples where we had no idea it was planning and we're like, oh God, it is. That's sort of like the current state we're at.
Vibhu [00:23:51]: I'm curious internally how this kind of feeds back into like the research, the architecture, the pre-training teams, the post-training, like, is there a good feedback loop there? Like right now there's a lot of external people interested, right? Like we'll train an SAE on one layer of LAMA and probe around. But then people are like, okay, how does this have much impact? People like clamp down, clamping. But yeah, as you said, you know, once you start to understand these models have this early planning and stuff, how does this kind of feed back?
Emmanuel [00:24:16]: I don't know that there's, there's like much to say here other than like, I think we're definitely interested in conversely, like making models for which it's like easier to interpret them. So that's also something that you can imagine sort of like working on, which is like making models where you have to work less hard to try to understand what they're doing. So like the architecture? Okay.
swyx [00:24:35]: Yeah. So I think there was a, there was a less wrong post about this of like, there's a non-zero model, which is like,
Emmanuel [00:24:47]: there's this sort of sense in which like right now we take the model and then the model is a model. And then we post hoc do these replacement layers to try to understand it. But of course, when we do that, we don't like fully capture everything that's happening inside the model. We're capturing like a subset. And so maybe some of it is like, you could train a model that's sort of like easier to interpret naively. And it's possible that like, you don't even have that much of, you know, like a tax in that sense. And so maybe some of it is like, you can just sort of like, either like train your model differently or do like a little post hoc step to like, sort of like untangle some of the mess that you've made when you trained your model. Right. Make it easier to interpret. Yeah.
swyx [00:25:19]: The hope was pruning would do some of that, but I feel like that area of research has just died. What kind of pruning are you thinking of here? Just pruning your network. Ah, yeah. Pruning layers, pruning connections, whatever. Yeah.
Emmanuel [00:25:34]: I feel like maybe this is something where like superposition makes me less hopeful or something.
swyx [00:25:40]: I don't know. Like that, that like seventh bit might hold something. Well,
Emmanuel [00:25:44]: right. And it's like on, on each example, maybe this neuron is like at the bottom of like what matters, but actually it's participating like 5% to like understanding English, like doing integrals and you know, like whatever, like cracking codes or something. And it's like, because that was just like distributed over it, you, you, you kind of like when you naively prune, you might miss that.
swyx [00:26:05]: I don't know. Okay. So, and then this area of research in terms of creating models that are easier to interpret from the, from the start, is there a name for this field of research?
Emmanuel [00:26:14]: I don't think so. And I think this is like very early. Okay. And it's, it's mostly like a dream. Just in case there's a, there's a thing people want to double click on. Yeah, yeah, yeah.
swyx [00:26:20]: I haven't come across it.
Vibhu [00:26:22]: I think the higher level is like Dario recently put out a post about this, right? Why McInterpre is so interpret important. You know, we don't want to fall behind. We want to be able to interpret models and understand what's going on, even though capabilities are getting so good. It kind of ties into this topic, right?
Vibhu [00:26:40]: It's slightly easier to interpret so we don't fall behind so far. Well,
Emmanuel [00:26:43]: yeah. And I think here, like, just to talk about the elephant in the room or something like, like one big concern here is, is like safety, right? And so like, as models get better, they are going to be used more and more places. You know, it's like, you're not going to have your, you know, we're vibe coding right now. Maybe at some point, well, that, that'll just be coding. It's like, Claude's going to write your code for you. And that's it. And Claude's going to review the code that Claude wrote. And then Claude's going to deploy it to production. And at some point, like, as these models get integrated deeper and deeper into more and more workflows, it gets just scarier and scarier to know nothing about them. And so you kind of want your ability to understand the model, to scale with like how good the model is doing, which that itself kind of like tends to scale with like how widely deployed it is. So as we like deploy them everywhere, we want to like understand them better.
swyx [00:27:28]: The version that I liked from the old super alignment team was, weak to strong generalization or weak to strong alignment, which that's what super alignment to me was. And that was my first aha moment of like, oh yeah, some, at some point these things will be smarter than us. And in many ways they already are smarter than us. And we rely on them more and more. We need to figure out how to control them. And this, this is not a, like an Eliezer Yudkowsky, like, ah, thing. It's just more like, we don't know what, how these things work. Like, how can we use them? Yeah.
Emmanuel [00:27:56]: And like, you can think of it as, there's many ways to solve a problem. And some of them, if the model is solving it in like a dumb way or in like memorized one approach to do it, then you shouldn't deploy it to do like a general thing. Like it, like you could look at how it does math and based on your understanding of how it does math, you're like, okay, I feel comfortable using this as a calculator or like, no, it should always use a calculator tool because it's doing math in a stupid way and extend that to any behavior. Right. Where it's just a matter of like, think about it. If, if like you're like in the 1500s and I give you a car or something, and I'm just like, cool, like this thing, when you press on this, like it accelerates when you press on that, like it stops, you know, this steering wheel seems to be doing stuff, but you knew nothing about it. I don't know if it was like a, a super faulty car and it's like, oh yeah, but if you ever get, went above 60 miles an hour, like it explodes or something like you probably would be sort of like, you'd want to understand the nature of the object before like jumping in, in it. And so that's why we like understand how cars work very well because we make them. LLMs are sort of like ML models in general are like this very rare artifact where we like make them, but we don't, we don't know how they work.
swyx [00:28:58]: We evolve them. We create conditions for them to evolve and then they evolve. And we're like, cool. Like, you know, maybe you got a good run. Maybe we didn't. Yeah. Don't really know.
Emmanuel [00:29:07]: Yeah. The extent to which you know how it works is you have your like eval and you're like, oh, well seems to be doing well on this eval. And then you're like, is this because this wasn't a training set or is it like actually generalizing? I don't know.
swyx [00:29:16]: My favorite example was somehow C4, the, the common, the colossal clean corpus did much better than a common crawl, even though it filtered out most of this, like it was very prudish. So it like filters out anything that could be considered obscene, including the word gay, but like somehow it just like when you add it into the data mix, it just does super well. And it's just like this magic incantation of like this, this recipe works. Just trust us. We've tried everything. This one works. So just go with it. Yeah. That's not very satisfying.
Emmanuel [00:29:49]: No, it's not. The side that you're talking about, which is like, okay, like how do you make these? And it's kind of unsatisfying that you just kind of make the soup. And you're like, oh, well, you know what? My grandpa made the soup with these ingredients. I don't know why, but I just make the soup the way my grandpa said. And then like one day somebody added, you know, cilantro. And since then we've been adding cilantro for generations. And you're like, this is kind of crazy.
swyx [00:30:07]: That's exactly how we train models though. Yeah. Yeah.
Emmanuel [00:30:10]: So I think there's, there's like a part where it's like, okay, like let's try to unpack what's happening. You know, like the mechanisms of learning,
Emmanuel [00:30:21]: you know, like understanding what induction heads are, which are attention heads that allow you to look at in your context, the last time that something was mentioned and then repeat it is like something that happens. It seems to happen in every model. And it's like, oh, okay, that makes sense. That's how the model like is able to like repeat text without dedicating too much capacity to it.
Vibhu [00:30:39]: Let's get it on screen. So if you can see. The visuals of the work you guys put out is amazing. Oh yeah.
swyx [00:30:44]: We should talk a little bit about the back behind the scenes of that kind of stuff, but let's, let's finish this off first. Totally.
Emmanuel [00:30:49]: But just really quickly, I think it's just like, if you're interested in mech interp, we talked about superposition and I think we skipped over induction heads and that's like, you know, kind of like a really neat, basically pattern that emerges in many, many transformers where essentially they just learn. Like one of the things that you need to do to like predict text well is that if there's repeated texts at some point, somebody said, Emmanuel Mason, and then you're like on the next line and they say, Emmanuel, very good chance. It's the same last name. And so one of the first things that models learn is just like, okay, I'm just gonna like look at what was said before. And I'm gonna say the same thing. And that's induction heads, which is like a pair of attention heads that just basically look at the last time something was said, look at what happened after, move that over. And that's an example of a mechanism where it's like, cool. Now we understand that pretty well. There's been a lot of followup research on understanding better, like, okay, like in which context do they turn on? Like, you know, there's like different like levels of abstraction. There's like induction heads that like literally copy the word. And there's some that copy like the sentiment and other aspects. But I think it's just like an example of slowly unpacking, you know, or like peeling back the layers of the onion of like, what's going on inside this model. Okay. This is a component. It's doing this.
swyx [00:31:51]: So induction headers was like the first major finding.
Emmanuel [00:31:53]: It was a big finding for NLP models for sure.
swyx [00:31:56]: I often think about the edit models. So Claude has a fast edit mode. I forget what it's called. OpenAI has one as well. And you need very good copying, every area that needs copying. And then you need it to switch out of copy mode when you need to start generating. Right. And that is basically the productionized version of this. Yeah.
Emmanuel [00:32:15]: Yeah. Yeah. And it turns out that, you know, you, you need to switch out of copy mode when you need to start generating. It's also like a model that's like smart enough to know when it needs to get out of copy mode, right? Which is like, it's fascinating.
swyx [00:32:22]: It's faster. It's cheaper. You know, as bullish as I am on canvas, basically every AI product needs to iterate on a central artifact. And like, if it's code, if it's a piece of writing, it doesn't really matter, but you need that copy capability. That's smart enough to know when to turn it off.
Emmanuel [00:32:40]: That's why it's cool that induction heads are at different levels of abstraction. Like sometimes you need to editing some code, you need to copy like the general structure. Yeah. It's like, oh, like the last, like this other function that's similar, it's first takes like, you know, I don't know, like abstract class and then it takes like an int. So I need to like copy the general idea, but it's going to be a different abstract class and a different int or something. Yeah. Cool.
swyx [00:32:59]: Yeah. So tracing?
Emmanuel [00:33:01]: Oh yeah. Should we jump to circuit tracing? Sure.
swyx [00:33:03]: I don't know if there's anything else you want to cover. No,
Emmanuel [00:33:05]: no, no. We have space for it. Maybe. Okay. I'll do like a really quick TLDR of these two recent papers. Okay. Insanely quick.
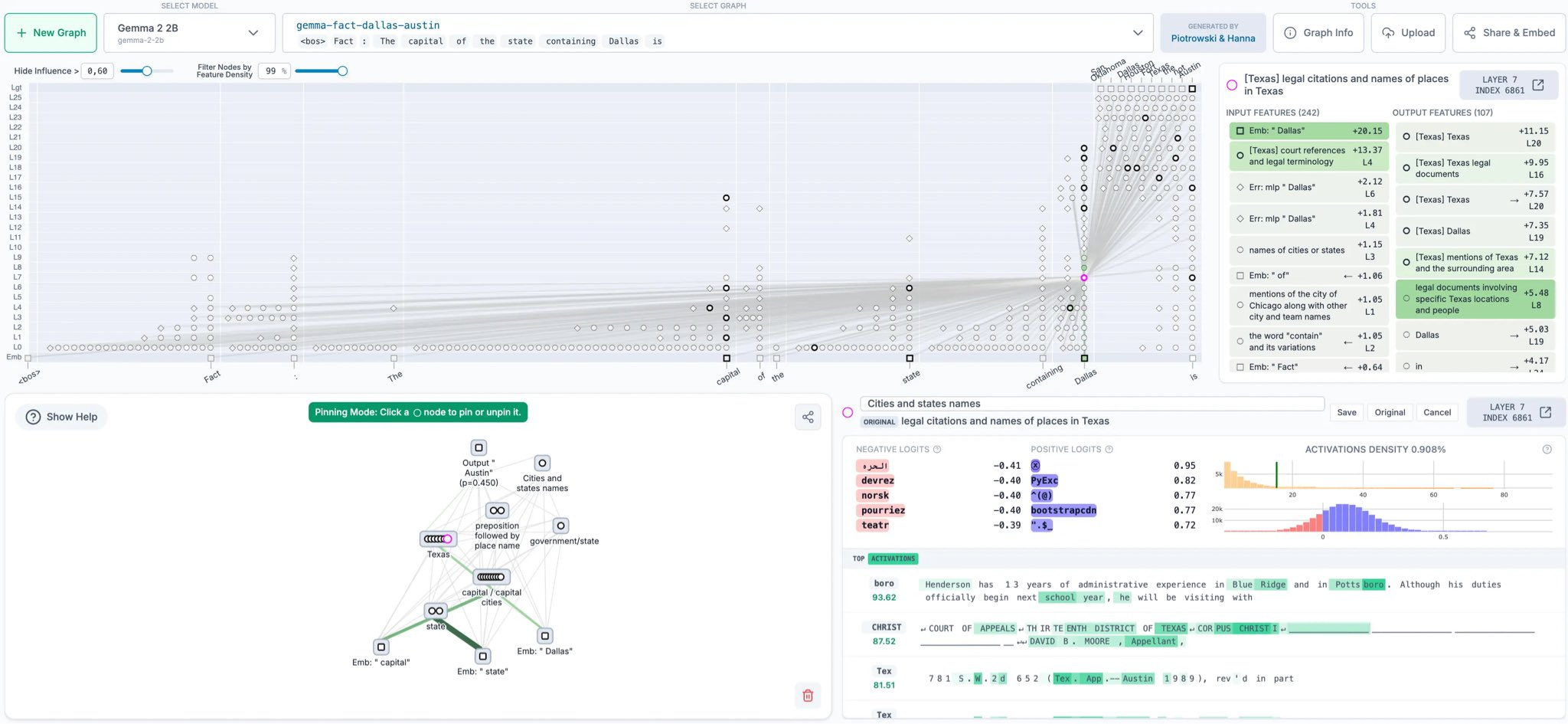
Emmanuel [00:33:18]: Okay. But we'd like to connect the features to understand like the inputs to every features and the opposite features and basically draw a graph. And this is like, if I'm still sharing my screen, uh, the thing on the right here where like, that's the dream we want, like for a given prompt, what were all of the things, like all of the important things happen in the model. And here it's like, okay, it took in these four tokens. Those activated these features, these features, activate these other features. And then these features like to be the other features. And then all of these like promoted the output. And that's the story. And basically we're, we're like, the work is to sort of use dictionary learning and these replacement models to provide a explanation of like sets of features that explain behavior. So this is super abstract. So I think immediately maybe we can like, just look at one example. I can show you one, which is this one, the reasoning one. Yep. Yeah. Two step reasoning. I think this is already, this is like the introduction example, but it's already like kind of fun. So, so the question is you ask the model something that requires it to take a step of reasoning in its head. So let's say, you know, fact, the capital of the state containing Dallas is. So to answer that, you need one intermediate step, right? You need to say, wait, where's Dallas? Isn't Texas. Okay, cool. Capital of Texas, Austin. And this is like in one token, right? It's going to, after is, it's going to say Austin. And so like in that one forward pass, the model needs to extract, to realize that you're asking it for like the capital of a state to like look up the state for Dallas, which is Texas. And then to say Austin. And sure enough, this is like what we see is we see like in this forward pass, there's a rich sort of like inner set of representations where there's like, it gets capital state in Dallas and then boom, it has an inner representation for Texas. And then that plus capital leads it to like say Austin.
Vibhu [00:34:59]: I guess one of the things here is like, we can see this internal like thinking step, right? But a lot of what people say is like, is this just memorized fact, right? Like I'm sure a lot of the pre-training that this model is trained on is this sentence shows up pretty often. Right? So this shows that no, actually internally throughout, we do see that there is this middle step, right? It's not just memorized. You can prove that it generalized.
Emmanuel [00:35:22]: Yeah. So, so, so that's exactly right. And I think like you, you, you hit the nail on the head, which is like, this is what this example is about. It's like, ah, if this was just memorized, you wouldn't need to have an intermediate step at all. You'd just be like, well, I've seen the sentence, like, I know what comes next. Right. But here there is an intermediate step. And so you could say like, okay, well maybe it just has the step, but it's memorized it anyways. And then the way to like verify that is kind of like what, what we do later in the paper. And for all of our examples is like, okay, we claim that this is like the Texas representation. Let's get another one and replace it. And we just changed like that feature in the middle of the model. And we change it to like California. And if you change it to California, sure enough, it says Sacramento. And so it's like, this is not just the like byproduct, like it's memorized something. And on the side, it's thinking about Texas. It's like, no, no, no, this is like a step in the reasoning. If you change that intermediate step, it changes the answer.
Vibhu [00:36:12]: Very, very cool work. Underappreciated.
Emmanuel [00:36:15]: Yeah. Okay.
Vibhu [00:36:16]: Sure.
swyx [00:36:17]: I have never really doubted. I think there's a lot of people that are always criticizing LMS, stochastic parrots. This pretty much disproves it already. Like we can move on. Yeah.
Emmanuel [00:36:28]: I mean, I, I think, I think there's a lot of examples that I will say we can go through like a few of them. And like show an amount of depth in the intermediate states of the model that makes you think like, oh gosh, like it's doing a lot. I think maybe like the poems, well, definitely the poems, but even for this one, I'm going to like scroll in this very short paper. So like medical diagnoses,
swyx [00:36:50]: I don't even know the word count because there's so many like embedded things in there. Yeah.
Emmanuel [00:36:54]: It's too dangerous. We can't look it up. It overflows. It's so beautiful. Look at this. This is like a medical example that I think shows you again, this is in one forward pass. The model is like given a bunch of symptoms and then it's asked not like, Hey, what does, what is the like disease that this person has? It's asked like if you could run one more test to determine it, what would it be? So it's even hard, right? It means like you need to take all the symptoms. Then you need to like have a few hypotheses about what the disease could be. And then based on your hypothesis, say like, well, the thing that would like be the right test to do is X. And here you can see these three layers, right? Where it's like, again, in one forward pass, it has a bunch of like, oh, it has the most likely diagnosis here, then like an alternate one. And then based on the diagnosis, it like gives you basically a bunch of things that you could ask. And again, we do the same experiments where you can like kill this feature here, like suppress it. And then it asks you a question about the second, the sort of like second option it had. The reason I show it is like, man, that's like a lot of stuff going on. Like for, for one forward pass, right? It's like specifically if you, if you expected it to like, oh, what it's going to do is it's just like seeing similar cases in the training. It's going to kind of like vibe and be like, oh, I guess like there's that word and it's going to say something that's related to like, I don't know, headache, you know what I kind of like really have. It's like, no, no, no. It's like activating many different distributed representations, like combining them and sort of like doing something pretty complicated. And so, yeah, I think, I think it's funny because in my opinion, that's like, yeah, like, oh God, stochastic parrots is not something that I think is, is like appropriate here. And I think there's just like a lot of different things going on and there's like pretty complex behavior. At the same time, I think it's in the eye of the beholder. I think like I've talked to folks that have like read this paper and I've been like, oh yeah, this is just like a bunch of kind of like heuristics that are like mashed together, right? Like the model is just doing like a bunch of kind of like, oh, if high blood pressure than this or that. And so I think there's, there's sort of like an underlying question that's interesting, which is like, okay, now we know a little bit of how it works. This is how it works. Like now you tell me if you think that's like impressive, if you think that like, if you trust it, if you think that's sort of like something that is, that is sufficient to like ask it for medical questions or whatever.
swyx [00:38:59]: I think it's a way to adversarially improve the model quality. Yeah. Because once you can do this, you can reverse engineer what would be a sequence of words that to a human makes no sense or lets you arrive at the complete opposite conclusion, but the model still gets tripped up by. Yeah. And then you can just improve it from there. Exactly.
Emmanuel [00:39:19]: And this gives you a hypothesis about like, you like specifically imagine if like one of those was actually the wrong symptom or something, you'd be like, oh, like the liver condition, like, you know, upweighs this other example. That doesn't make sense. Okay. Let's like fix that in particular. Exactly. You sort of have like a bit of insight into like how the model is getting to its conclusion. And so you can see both like, is it making errors, but also is it using the kind of reasoning that will lead it to errors?
swyx [00:39:45]: There's a thesis. I mean, now it's very prominent with the reasoning models about model death. So like you're doing all this in one pass. Yeah. But maybe you don't need to, because you can do more passes. Sure. And so people want shallow models for speed, but you need model death for this kind of thinking. Yeah. So what's the, is there a Pareto frontier? Is there a direct trade off? Yeah. I mean, would you prefer if you had to make a model and like, you know, shallow versus deep?
Emmanuel [00:40:15]: There's a chain of thought faithfulness example. Before I show it, I'm just going to go back to the top here. So when the model is sampling many tokens, if you want that to be your model, you need to be able to trust every token it samples. So like the problem with, with models being autoregressive is that like, if they like at some point sample a mistake, then they kind of keep going condition on that mistake. Right. And so sometimes like you need backspace tokens or whatever. Yeah. An error correction is like notably hard, right? If you have like a deeper model, maybe you have like fewer COT steps, but like your, your steps are more likely to be like robust or, or correct or something. And so I think that that's one way to look at the trade off. To be clear, I don't have an answer. I don't know if I want a wide or a, or a shallow or a deep model, but I think, I think the trade off is that like,
swyx [00:41:00]: You definitely want shallow for inference speed. Sure,
Emmanuel [00:41:02]: sure, sure, sure. But you're trading that off for, for something else, right? Cause you also want like a one B model for inference speed, but that also comes at a cost, right? It's, it's less smart.
Vibhu [00:41:10]: There's a cool quick paper to plug that we just covered on the paper club. It's a survey paper around when to use reasoning models versus dense models. What's the trade off. I think it's the economy of reasoning economy, reasoning, the reasoning economy. So they just go over a bunch of, you know, ways to measure this benchmarks around when to use each because yeah. Yeah. Like, you know, we don't want to also like consumers are now paying the cost of this. Right. But little, little side note. Yeah.
swyx [00:41:34]: For those on YouTube, we have a secondary channel called Latent Space TV, where we cover that stuff. Nice. That's our paper club. We covered your paper.
Emmanuel [00:41:41]: Cool. Yeah. I think you brought up the like planning thing. Maybe it's worth. Let's do it. Yeah. If you think about, okay. So you're, you're going into the chain of thought faithfulness one. Let's get this one. Let's just do planning. So if you think about like, you know, common questions you have about models, the first one we kind of asked was like, okay, like is it just doing this like vibe based one shot pattern matching based on existing data? Or does it have like kind of rich in representations? It seems to have like these like intermediate representations that make sense as the abstractions that you would reason through. Okay. So that's one thing. And there's a bunch of examples. We talked about the medical diagnoses. There's like the multilingual circuits is another one that I think is cool where it's like, oh, it's sharing representations across languages. Another thing that you'll hear people mention about language models, which is that they're like a next token predictors.
Vibhu [00:42:25]: Also for, for a quick note for people that won't dive into this super long blog post, I know you highlighted like 10 to 12. So for like a quick 15, 30 second, what do you mean by they're sharing thoughts throughout? Just like, what's the really quick high level just for people though? Yeah.
Emmanuel [00:42:39]: They're really quick. High level. High level is that what we find is that here, I'm just like show you a really quick inside the model. If you look at like the inner representations for concepts, you can ask like the same question, which I think in the paper, the original one we asked is like the opposite of hot is cold, but you can, you can do this over a larger dataset and ask the same question in many different languages. And then look at these representations in the middle of the model and ask yourself like, well, when you ask it, the opposite of hot is, and which is the same sentence in French, show off. Is it, is it using the same features or is it learning independently for each language? It kind of would be bad news if it learned independently for each language, because then that means that like, as you're pre-training or fine tuning, you have to relearn everything from scratch. So you would expect a better model to kind of like share some concepts between the languages it's learning. Right. And you hear, we do it for like language languages, but I think you could argue that you'd expect the same thing for like programming languages where it's like, oh, if you learn what an if statement is in Python, maybe it'd be nice if you could generalize that to Java or whatever. And here we find that basically you see exactly that. Here we show like, if you look inside the model, if you look at the middle of the model, which is the middle of this plot here, models share more features. They share more of these representations in the middle of the model and bigger models share even more. And so the like, the sort of like smarter models use more shared representations than the dumber models, which might explain part of the reason why they're smarter. And so this, this was like sort of this, this other finding of like, oh, not only is it like having these rich representations in the middle. Right. It like learns to not have redundant representations. Like if you've learned the concept of heat, you don't need to learn the concept of like French heat and Japanese heat and Colombian, like you just, that's just the concept of heat. And you can share that among different languages.
... [Content truncated due to size limits]