Here’s Chapter 8 of Mixed Model Arts, which covers grain. It’s an important topic, and this is a relatively short chapter that overlaps a lot with the material in the upcoming chapter on aggregations, and the detailed application of grain in book two. I tried to keep this as useful as possible, while also not stealing the thunder from other material in this book series.
Lots of edits happening, so stay tuned as more chapters drop. Getting closer to the finish line!
Thanks,
Joe
Wrestling day. The coach has you drilling level changes—standing to a shot, shot to a finish, over and over. “Levels,” she keeps saying. “The whole game is levels.” She’s talking about wrestling, but the word sticks with you.
Between drills, one of the wrestlers tells you a story. A fighter he knew lost a title shot because his coaches only looked at the other guy’s career stats. Career stats said the opponent couldn’t wrestle. But if you watched the last three fights round by round, the guy had completely overhauled his takedown defense. “They were looking at the wrong level,” he says.
In data modeling, that level has a name: Grain.
What Is Grain?
Grain represents the fundamental level of detail captured in a dataset. The core question for any data modeler is always: what, precisely, does one row or record represent? A customer table’s grain is one row per customer. A transaction table’s grain is one row per transaction. A daily summary’s grain is one row per day.
Grain is one of the most critical decisions when designing any dataset, whether you’re dealing with relational databases, streaming events, unstructured text, machine-learning features, or anything else. Get it right, and your data makes sense and is useful. Get it wrong, and things break in often mysterious and painful ways.
Sometimes the best way to understand something is to see it break.
Wrong Grains in Practice
Let’s look at two common ways grain goes wrong: incompatible grains and fan-out.
Incompatible Grains
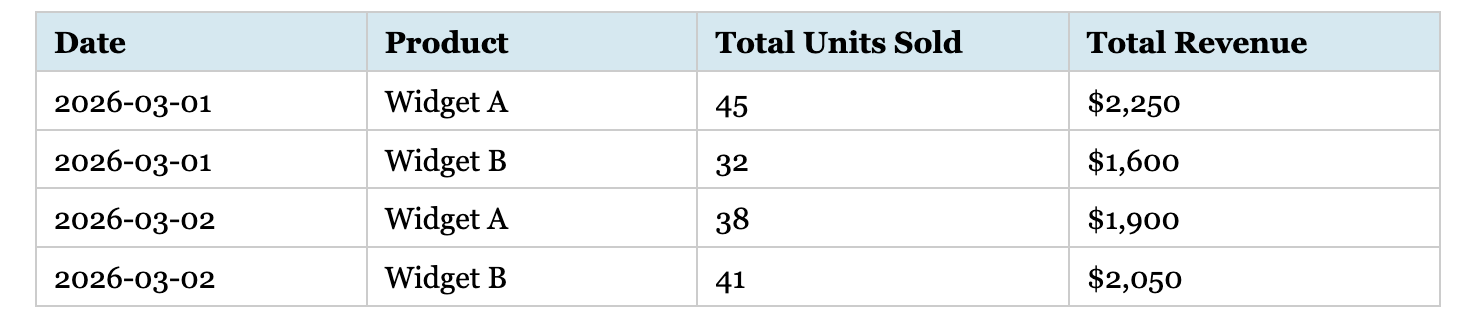
Consider two datasets without a common granularity. Dataset A shows daily sales by product. Here’s the aggregated grain where each row summarizes all transactions for a product on a given day.
Dataset A: daily sales by product
Dataset B details individual customer purchases—a transaction-level grain where each row represents a single purchase.
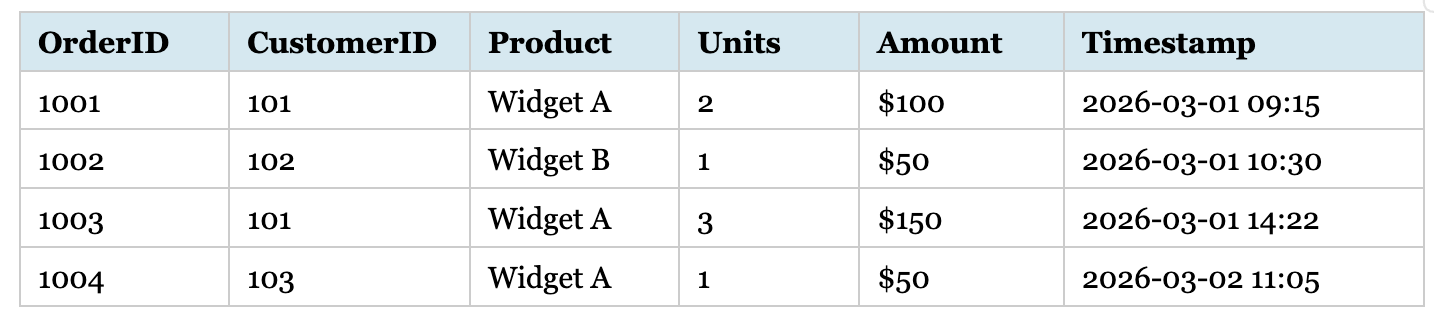
Dataset B: individual customer purchases
These datasets have incompatible grains. Dataset A aggregates sales; Dataset B is at the transaction level. Combining them directly creates no meaningful join—Dataset B could be rolled up to Dataset A’s granularity, but not vice versa. Though this seems obvious, I’ve watched many people struggle to combine datasets that don’t align at the same grain level.
Joining incompatible grains is usually bad. Unless explicitly designed as an OLAP rollup table with a strict grain_level indicator column, storing them in the same table is worse. Occasionally, you’ll find a single table where most rows are individual transactions, but some represent daily totals. This is the mixed-grain trap, a cousin of the incompatible-grains problem. If an unsuspecting analyst runs a simple SUM() on that column, you’ve instantly double-counted your revenue.
Fan-Out
One of the most common sources of incorrect analytics is fan-out—the unintended multiplication of rows that occurs when joining tables with mismatched grains. Fan-out often remains invisible until someone notices the numbers don’t match reality, making it particularly dangerous.
Consider these tables:
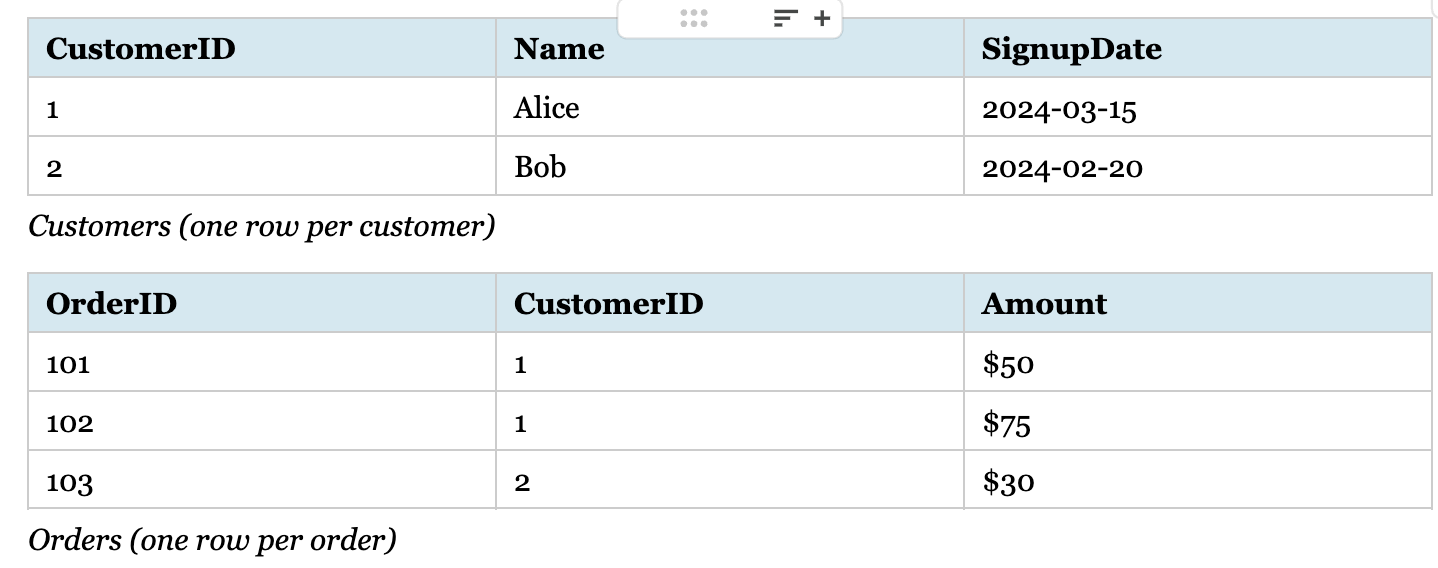

Join result: Alice appears twice (fan-out)
The Customers table has one row per customer; the Orders table has one row per order. When you join on CustomerID, Alice (who has two orders) appears twice—the fan-out effect. Her customer attributes are now duplicated across two rows. Count customers from this result, and you get 3 instead of 2. Sum a customer-level metric like “signup bonus” and you double-count Alice’s. The result grain is now “one row per order,” not “one row per customer.”
This join is perfectly correct if your goal is order-level analysis. The danger isn’t the join itself, but forgetting that the result’s grain has changed. The moment someone counts customers or sums a customer-level metric from this result without accounting for the new grain, the numbers lie.