Here’s Chapter 4 and also the first chapter of Part 2 of Mixed Model Arts, which covers the Building Blocks of Data Modeling. Part 2 goes from Chapter 4 to Chapter 12 and covers the things I always wish were taught in Data Modeling: The first principles you’ll need to model any type of data, whether it’s for a database, for analytics, for ML/AI, etc.
Enjoy,
Joe
November 12, 1993. Denver, Colorado. A professional boxer named Art Jimmerson walks into the octagon at UFC 1 with one boxing glove taped shut. He’s confident—he’s a ranked cruiserweight with real knockout power. Across from him stands Royce Gracie, a 170-pound Brazilian jiu-jitsu practitioner most of the crowd has never heard of. Ninety seconds later, Jimmerson taps out from the mount without a single punch being thrown. He had no idea what to do once the fight left his domain. A boxer tried to box in a grappling match, and it was over before it started.
Data takes different forms, too. And just like Jimmerson at UFC 1, the data modeler who thinks only in tables will get submitted the first time they encounter a dataset that doesn’t fit. Images aren’t tables. Audio isn’t a spreadsheet. A stream of JSON events doesn’t behave like a star schema. The forms of data—structured, semi-structured, unstructured, and ML/AI artifacts—are as distinct as striking, grappling, and submissions. Each has its own physics, its own rules, and each demands its own modeling approach.
This chapter is your first session in the gym. We’re going to walk through the major forms of data you’ll encounter as a data modeler, and I’ll explain why picking the right modeling approach for each form is foundational to everything that follows.
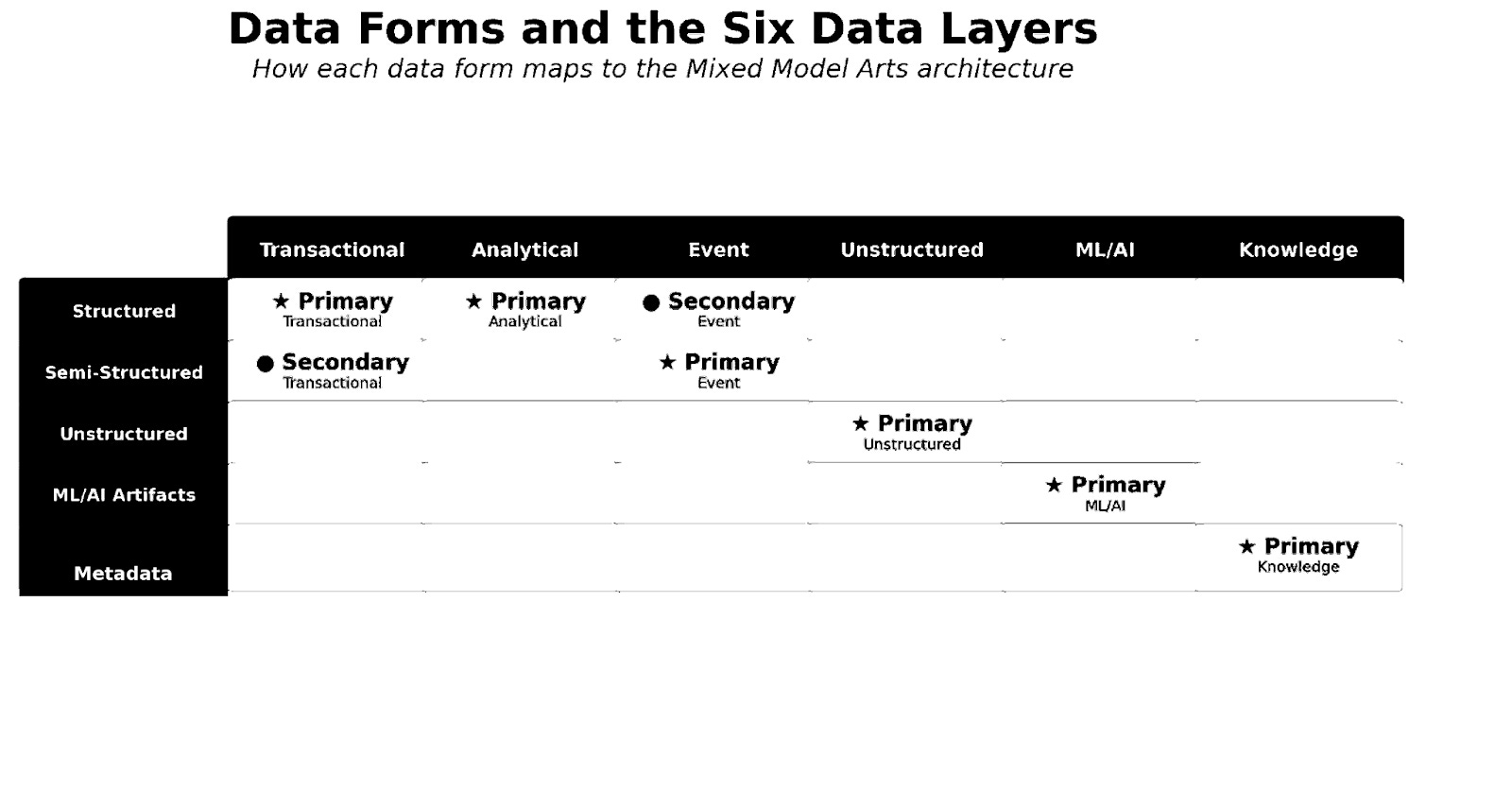
Each data form maps naturally to the architectural framework from Chapter 1. Structured data powers your Transactional and Analytical layers—the operational heartbeat and analytical engine of any organization. Semi-structured data, particularly event streams, belongs in the Event layer, capturing the temporal flow of user actions and system interactions. Unstructured data finds its home in the Unstructured layer, where raw content lives alongside its metadata references. Machine learning and AI artifacts populate the ML/AI layer, while metadata and ontologies connect everything through the Knowledge layer. Understanding these forms isn’t just an academic exercise; it’s about seeing how each layer of your data architecture demands its own modeling approach. The Mixed Model Artist recognizes these distinctions and leverages each form where it belongs.
Figure 4-1: Data Forms and the Six Data Layers
Picture a data modeler sitting down with SQL queries ready to analyze a dataset of medical images. They craft a query: “SELECT lesion_size WHERE severity > 5 ORDER BY patient_id.” The query fails. Of course it does—images aren’t tables1. Rows and columns don’t exist inside a JPG file. This is the central challenge of modern data modeling: we now work with images, audio, video, text, and countless other forms that don’t fit the table-centric thinking that dominated the field for decades.
For decades, data modeling meant table design. That worked fine when data modeling was essentially database design. But the world has moved on. Today, we deal with structured, semi-structured, unstructured, metadata, and ML/AI artifacts—and not all of it fits neatly into rows and columns.
This is where the five camps from Chapter 1 reveal their true nature. The Relational camp privileges structured data and builds beautiful, normalized schemas around it. The Application camp loves semi-structured data—JSON, XML, nested hierarchies—and celebrates flexibility. The ML/AI camp works almost exclusively with tensors, embeddings, model artifacts, and feature vectors. The Analytics/Data Warehouse camp denormalizes structured data for analytical speed. The Knowledge Graph camp connects everything relationally through graphs, semantic networks, and ontologies. Each camp optimizes for its chosen form and perspective on what matters most: consistency, flexibility, pattern recognition, analytical speed, or semantic meaning.
A quick note on form vs. format. It is crucial to distinguish the form of the data from its physical format. A relational table is a logical form. Parquet is a physical file format that stores that form in a columnar layout. You model the form, but your engineering constraints—compression, read-heavy vs. write-heavy workloads—dictate the format.
Let’s examine the most common forms of data you’ll encounter when modeling: structured, semi-structured, unstructured, ML/AI artifacts, and metadata.
Structured Data
Structured data—sometimes called tabular data—is the form most data professionals know best. It’s highly organized information stored in a predefined format with a strict schema: rows and columns, where each column has a defined data type (string, integer, date, etc.) and each row represents one record. Think of a well-organized spreadsheet or a relational database table.
Historically, data modeling discussions have centered on structured data. If you’ve taken a data modeling class or read a book on the subject, you’ve most likely learned to model structured data. This legacy traces back to computing’s early days, when data was often stored in rigid structures. The rise of relational databases in the 1970s and 1980s solidified structured data as the de facto form for most business use cases. Codd’s relational data model remains the standard for modeling transactional databases. Other variations in analytics include Ralph Kimball’s dimensional model and Dan Linstedt’s Data Vault.
Structured data has a lot going for it: widespread adoption, computational efficiency, and human readability. SQL is one of the most common languages in computing, and relational databases power the vast majority of business applications. The constraints that structured data enforces—fixed schemas, defined types, referential integrity—are features, not limitations. They catch errors before they propagate.
Databases dominate discussions of structured data, yet if you look around, spreadsheets and, to a lesser extent, data frames, are everywhere. I often call spreadsheets the “dark matter of the data universe.” They’re by far the most common way to interact with structured data, with estimates ranging to as many as one billion people regularly using spreadsheets2. The nuance is that while spreadsheets and data frames are structured as tables, they don’t enforce rigidly defined schemas like databases do. Nothing stops you from inserting any values into any row or column, nor are there consequences for doing so.
Modeling Implications for Structured Data
Structured data is the home turf of data modeling, which is why most modeling literature focuses almost exclusively on it. The modeling playbook is well-established: normalize for integrity, denormalize for performance, use foreign keys to enforce relationships, and lean on the type system to constrain values.