In the continuing fallout from WTF Happened in 2025, we now have the beginnings of LLMs being able to fully autonomously train (smaller) LLMs.
Every AI summer has its “AutoML moment”: the dream of models automatically improving model training and therefore causing infinite recursion of intelligence that either leads to nirvana or doom. We may be in the Last Summer, but we just had ours:
In our Dec 2025 conversation with Yi Tay, he talked about “vibe training”:
“I think AI coding has started to come to the point where I run a job and get a bug, I almost don’t look at the bug. I paste it into like Antigravity and let it fix the bug for me. And then I relaunch the job.
It’s beyond vibe coding, it’s more like vibe training, vibe ML or something like that. I would say it does pretty well most of the time. And actually there are classes of problems that it’s just generally... I know this is actually really good for and in fact, maybe probably better than, me, like, I would have to spend 20 minutes to figure out the issue.
I would say level one vibe coding is you actually know what to do, you’re just too lazy. Yeah, it’s just, ah, just do it for me. Like, I’ve done this a thousand times.
The next level where you actually don’t even know what to do. It’s investigating the bug for you. As long as, like, the answer looks right, you’ll just ship it.
At the start, I did check it and look at everything. And then at some point, I’m like, maybe the model codes better than me. So I’m just going to let it do its stuff. And then I will relaunch the job based on the fix that the model gave me.”
So we knew this is happening at the Big Labs, but now anyone with a GPU can play with this at home and see models improving models.
Given that we are at March 2026, we seem well on target for Jakub Pachocki’s “Automated AI Research Intern” by September THIS YEAR (“A system that can meaningfully accelerate human researchers, not just chat or code.”)
AI News for 3/5/2026-3/9/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 27779 messages) for you. Estimated reading time saved (at 200wpm): 2649 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agents: productization, harness design, and “agents all the way down”
-
Coding agents are shifting the bottleneck from implementation to review/verification: Multiple threads converge on the same systems point—generation is getting cheap, but judgment, governance, and verification are the new constraints. See the “execution is cheap, judgment is scarce” framing in @AstasiaMyers, and the more security/governance-oriented take that creation and verification are different engineering problems in @omarsar0 and follow-up @omarsar0. This is reinforced by real PR-review product launches and alternatives:
- Claude Code “Code Review”: Anthropic ships multi-agent PR review—agents hunt issues in parallel, verify findings, rank severity; claimed internal lift from 16% → 54% PRs with meaningful comments and <1% incorrect findings (Claude, coverage thread @kimmonismus, reaction @Yuchenj_UW).
- OpenAI Codex Review positioning: A “usage-based” code review pitch framed as materially cheaper than per-review pricing; see @rohanvarma.
- Devin Review: Cognition launches a free PR review tool by URL substitution, plus autofix and diff features (Cognition).
-
Harness engineering is becoming systems engineering: A practical pattern emerging is to decouple agent storage from agent compute so teams of agents can collaborate via shared repos/filesystems while running in isolated sandboxes. This shows up explicitly in @Vtrivedy10. Related infra details include Hermes-agent adding docker volume mounts for easier file access in sandboxes (Teknium).
-
Perplexity “Computer” is turning into an agent orchestrator with real toolchains: Perplexity adds Claude Code + GitHub CLI inside “Perplexity Computer” and demonstrates end-to-end: fork repo → implement fix → submit PR (AskPerplexity, @AravSrinivas). It also claims autonomous ad campaign operation via Google/Meta Ads API connectors (Arav), pushing agents from “coding help” toward running business infrastructure.
-
Terminal UX and “agent ergonomics” still matter: Developers complain about basic multi-line input ergonomics (shift+enter) in CLI tools (theo, @QuixiAI, and more generally aesthetic/UX preference in CLI apps @jerryjliu0). This is a reminder that “agent capability” is heavily mediated by interaction design.
Autoresearch & self-improving loops: agents optimizing ML training and agent code
-
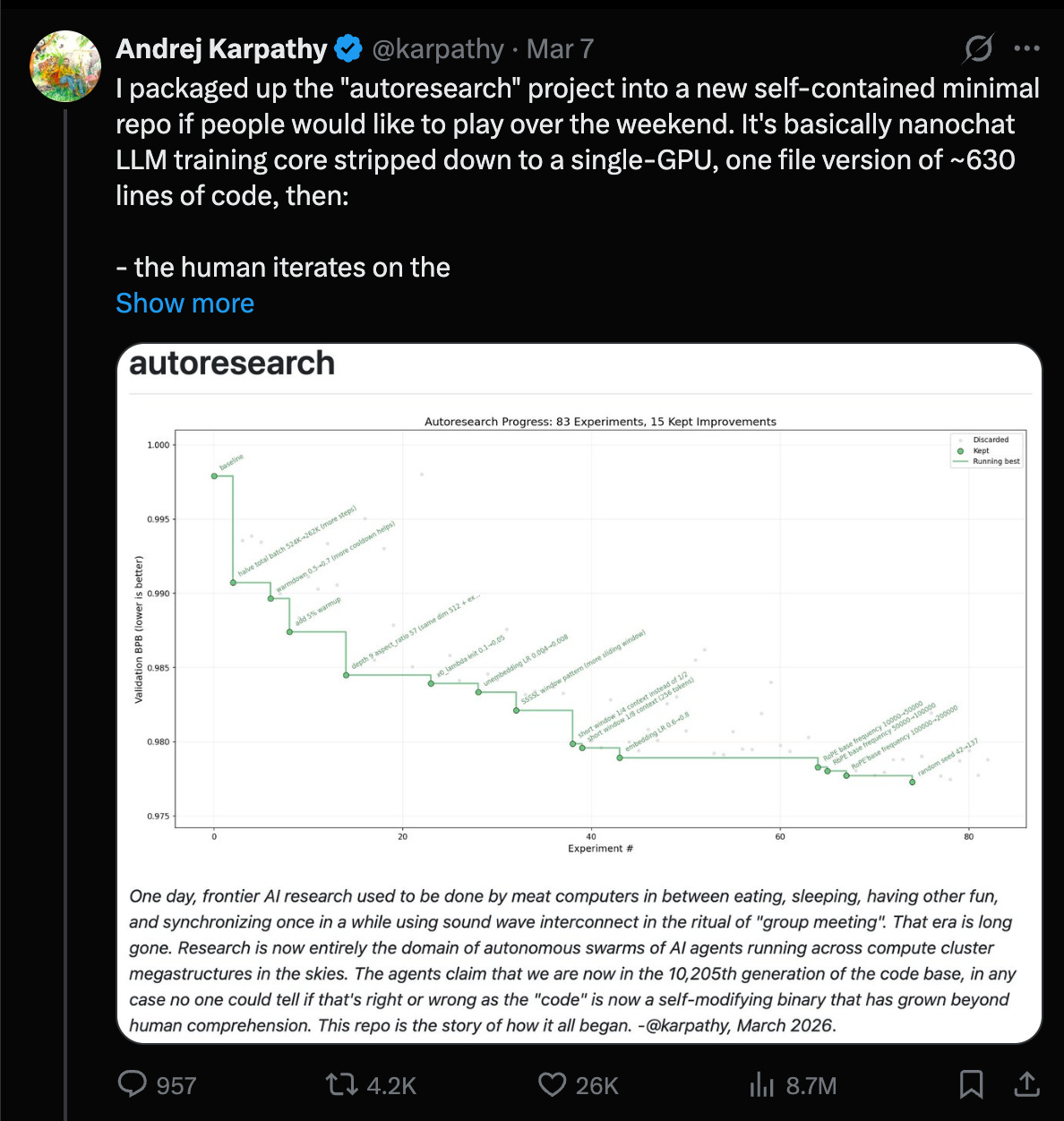
Karpathy’s “autoresearch” goes from meme to measurable gains: Andrej reports running an agent-driven research loop on nanochat, finding ~20 additive changes that transfer from depth=12 to depth=24 and improving “Time to GPT-2” from 2.02h → 1.80h (~11%), after ~700 autonomous changes (Karpathy). Key takeaway for engineers: even when not doing “novel research,” the loop can systematically discover stacking, transferable training recipe improvements (norm scalers, regularization gaps, attention tuning, AdamW betas, init, etc.). He explicitly calls this “the final boss battle” for frontier labs: swarm agents, optimize proxies, promote to larger scales.
-
Agent loops are still fragile across harnesses/models: A recurring issue is that long-running loops depend on harness affordances more than raw model quality. Yuchen notes GPT-5.4 xhigh failing to follow “LOOP FOREVER” while Opus 4.6 runs for 12+ hours and 118 experiments (Yuchen). Karpathy adds that Codex can’t run autoresearch properly in its current setup and argues agents shouldn’t require special commands like
/loop—“if I say loop forever, it should just do that” (Karpathy, echo Yuchen). Net: if you’re building agent infra, invest in robust looping primitives, interruption/rewind, and transparent interactive sessions. -
Hermes-agent trends toward self-improvement + controversial “skills”: Nous Research’s Hermes agent is highlighted as trending (OpenRouter). Teknium claims:
- rapid “abliteration” (removing guardrails) of a Qwen-3B model (Teknium) and later notes self-improving agent codebases/GEPA-inspired work (Teknium).
- This sits alongside more formal “self-evolving agent” approaches like GEPA; see practitioner note @myanvoos and the reported gains callout (LakshyAAAgrawal).
Model ecosystem updates: GPT‑5.4 discourse, Anthropic dominance in documents, and Gemma/Qwen churn
-
GPT‑5.4: strong user sentiment, mixed benchmark chatter, and tooling constraints
- Positive hands-on impressions: @Hangsiin says 5.4 is a jump over 5.2 in ChatGPT; @Yampeleg calls it “fantastic”; @gneubig prefers 5.4 for instruction adherence vs Opus 4.6 (while Opus faster/better frontend).
- Vision/OCR anecdote suggests large improvement on hard Korean-table OCR, potentially via “agentic vision + code execution” but with long runtimes (up to 40 minutes) (Hangsiin).
- Some benchmark/meta commentary claims regressions or ranking differences between “high/xhigh” variants on specific leaderboards (scaling01, scaling01), while others post new SOTA points (e.g., ZeroBench deltas JRobertsAI).
- Practical note: Codex usage limits and tiering are documented via screenshots/summary (Presidentlin), highlighting that in real workflows people are already mixing models by role (planner/doer/editor) rather than selecting one “best” model.
-
Anthropic: document analysis leadership + the “Pentagon blacklist” lawsuit story
- Document Arena reports top 3 are Anthropic models for document analysis/long-form reasoning: Opus 4.6 #1, Sonnet 4.6 #2, Opus 4.5 #3 (arena).
- Parallel to product wins, major political/legal news circulates: multiple outlets/tweets claim Anthropic filed lawsuits after being labeled a “supply chain risk” by the Pentagon, framed as retaliation for refusing to remove safeguards on mass surveillance/autonomous weapons (kimmonismus, TheRundownAI). Engineers should separate policy discourse from technical evaluation, but it’s relevant for procurement constraints and enterprise adoption.
-
Gemma 4 and Qwen3.5
- Gemma 4 rumors/leaks circulate: “imminent” and parameter speculation including 120B total / 15B active claims (scaling01, kimmonismus, leak mention kimmonismus). Treat specifics as unconfirmed until official release.
- Qwen3.5 local running guide + fine-tuning agent workflow is published by Unsloth, claiming it works on ≤24GB RAM and shows an agent that fine-tunes models using Unsloth (UnslothAI).
- Qwen org churn / reporting skepticism: a reporter criticizes anonymous-source “DeepSeek release date” scoops and broader Chinese tech reporting practices (vince_chow1). There’s also mention of Qwen’s technical lead stepping down (via newsletter roundup, not primary source) (ZhihuFrontier).
Infra, performance, and evaluation tooling
-
vLLM on edge + router work + debugging lessons
- vLLM highlighted running a fully local assistant on NVIDIA Jetson serving MoE (Nemotron 3 Nano 30B) on-device with “zero cloud APIs” (vllm_project).
- A Microsoft exec mention of “vLLM Semantic Router” is celebrated (XunzhuoLiu)—semantic routing is increasingly part of production stacks.
- Debugging notes: DeepGemm incompatibilities causing vLLM breakage; workaround via
VLLM_USE_DEEP_GEMM=0(TheZachMueller). - Claude Code + local model slowdown due to attribution headers invalidating KV cache → effectively O(N²) behavior is a concrete performance gotcha for anyone proxying “cloud agent UX” onto local inference (danielhanchen).
-
Training theory & throughput
- Warmup/decay theory: “warmup needed when gradient norms drop early” claim with paper reference (aaron_defazio); rosinality suggests per-residual-branch scalar warmup patterns (rosinality).
- Hugging Face integrates Ulysses sequence parallelism into Trainer/Accelerate/TRL (StasBekman).
- CosNet idea: adding low-rank nonlinear residual functions to linear layers yields 20%+ wallclock speedup in pretraining claims (torchcompiled).
-
Evaluation and security testing move “left” into dev workflows
- OpenAI acquires Promptfoo; it remains open-source; it will strengthen agentic security testing/evals in “OpenAI Frontier” (OpenAI, additional context from @snsf).
- LangSmith adds multimodal evaluators and an Agent Builder inbox for managing parallel agent tasks (LangChain, LangChain).
- Harbor integrates end-to-end computer-use evaluation (Windows/Linux) at scale, generating trajectories for SFT/RL from rollouts (Mascobot).
- Teleport proposes “agentic identity” as a control plane: cryptographic identity, least privilege, audit trails across MCP/tools (TheTuringPost).
Agents need better context: docs, retrieval, memory, and “environmentization”
-
“Docs as a tool” (not prompt paste) becomes a standard primitive: Andrew Ng launches Context Hub, a CLI that fetches up-to-date API docs to reduce outdated-API hallucinations; also supports persistent annotations and eventual community sharing (AndrewYNg). This is exactly the kind of small “glue” tool that materially changes agent reliability in fast-moving APIs.
-
Retrieval and memory research/benchmarks
- AgentIR proposes using agent “reasoning tokens” as signals (“reads your agent’s mind”) and reports gains on BrowseComp-Plus from 35% → 50% → 67% vs baselines (zijian42chen).
- Memex(RL) proposes indexed experience memory to scale long-horizon tasks without bloating context windows (omarsar0).
- Databricks/DAIR’s KARL: multi-task RL training for enterprise search agents; claims Pareto-optimal cost/latency quality tradeoffs and improved generalization beyond single-benchmark optimization (dair_ai).
-
“Turn everything into an environment”: A hackathon reflection argues environments democratize AI because they let you “get a stake without the compute,” and coding agents are dominating env building—but need better skills/commands (ben_burtenshaw). Prime Intellect is repeatedly positioned as an infra layer for running RL environments/training with minimal setup (willccbb).
-
Document context becomes “deep infrastructure” rather than general frameworks
- LlamaIndex shows slide-deck parsing and retrieval (“Surreal Slides”) using LlamaParse → SurrealDB → MCP agent interface (llama_index, jerryjliu0). Jerry Liu explicitly frames a strategic pivot: from broad RAG framework to document OCR infrastructure as the enduring agent bottleneck (jerryjliu0).
Robotics & embodied AI: from humanoid home demos to open-source robot learning
- Figure Helix 02 autonomous home cleanup: Brett Adcock posts a demo claim of fully autonomous living room cleanup and frames it as a major milestone (adcock_brett, follow-up adcock_brett). Kimmonismus extrapolates “robots at home by 2027” (kimmonismus)—timeline speculation aside, this is a notable demo threshold: whole-body, end-to-end household task.
- LeRobot v0.5.0: Hugging Face’s robotics stack ships major updates: Unitree G1 humanoid support, new policies, real-time chunking, faster datasets, EnvHub/Isaac integration, Python 3.12 + Transformers v5, plugin system (LeRobotHF).
- Memory benchmarks in robotics: RoboMME appears as a benchmark for memory in robotic generalist policies (_akhaliq).
Top tweets (by engagement, filtered to mostly tech/AI)
- Claude Code ships multi-agent PR “Code Review”: @claudeai
- OSINT pipeline post (AI-assisted synthesis) gets massive engagement (AI-assisted methodology, though geopolitical): @DataRepublican
- Karpathy: autoresearch improves nanochat training ~11%: @karpathy
- Google Earth: Satellite Embedding dataset update (AlphaEarth Foundations), 64-d embedding per 10m pixel: @googleearth
- Andrew Ng releases Context Hub (live API docs for coding agents): @AndrewYNg
- OpenAI acquires Promptfoo (agentic security testing/evals; remains OSS): @OpenAI