Here’s Chapter 5 about entities, instances, and identifiers. I’ve extended the traditional treatment of structured data to the five forms of data we covered in Chapter 4.
On to editing Chapter 6 (Attributes) and 7 (Relationships).
Thanks,
Joe
Step onto the mats for your first Brazilian Jiu-Jitsu class, and a live grappling exchange just looks like a chaotic tangle of bodies. As a beginner, you grab whatever is in front of you—a gi collar, a wrist, a pant leg—and just pull, hoping something works. To you, the opponent is just one big, undifferentiated mass of human anatomy.
But a Jiu-Jitsu black belt doesn’t see a tangle of limbs. They see distinct, sharply defined concepts: an underhook, a frame, a lever, a cross-collar grip. Because they can isolate and identify each specific component, they know exactly how to interact with it and control the chaos.
At one point in my career, I encountered the data engineering equivalent of a white belt flailing in the dark. It was a sprawling, business-critical spreadsheet called Master_Tracker_Final_v7.xlsx. The operations team ran the supply chain and ordered from this spreadsheet. It was a massive junk drawer, with row 10 a vendor name, row 11 a vendor invoice number, row 15 a delayed freight shipment, macros galore, and often taking 12 hours to update on Monday morning because of a Rube Goldberg of database calls and spreadsheet formula updates. Even worse, the “data model” relied on formatting: yellow highlighting meant “urgent,” and red text meant “dumpster fire.” It got the job done, but was extremely chaotic and error-prone. Since it was a shared spreadsheet among 20 people, random people would fat-finger the wrong data, run formulas that would lock the spreadsheet, and so on. It was a nightmare both operationally and cognitively.
You see the exact same anti-pattern in source systems repeatedly. It’s the CRM implementation where developers gave up and shoved everything into a single, monstrous table called CustomObject_1, or the event-streaming topic where every payload is just a giant JSON blob of random data.
Whether it’s a monster spreadsheet or a custom object, these failures share a common root cause: nobody stopped to distinctly name and identify the things they’re capturing in the data. This highlights one of the most fundamental lessons of data modeling—if you can’t distinctly name and identify something, you can’t model it.
This chapter dives into entities —“things”: a customer, a product, an order, a shipment. Get your entities right, and the rest of the data model flows naturally. Get them wrong, and you’ll waste time untangling a chaotic mess.
Naming the Things That Matter
An entity is a concrete or abstract thing. Some entities are concrete—Customer, Product, and Order. Some are abstract: Transaction, Workflow, Category. What matters is that they’re meaningful enough to show up in your model. Let’s look at entities in practice.
Say you’re new to an e-commerce company. You know they’re a digital platform that sells products to customers. That’s a start, but it’s too high-level. You need more detail. You dig a bit deeper to understand the business rules and workflows—from when a sale occurs until the customer receives their order.
Here’s what you learn:
A customer places an order for a product. The order contains detailed information about the customer, the products ordered, and shipping instructions. The order goes to a vendor, who ships the products. The shipment arrives at the customer.
Still very simple, but we have enough to work with for our purposes. Now, let’s identify the entities in this statement. When determining what an entity is, examine the workflow and consider the things or objects being represented. Think of these as nouns—the subjects or objects of actions and relationships in the workflow.
Here are the entities in this example:
- Order
- Customer
- Product
- Shipment
- Vendor
These entities represent the nouns that fulfill customer orders on the e-commerce platform. Everyone operating within fulfillment workflows should understand the meaning of each entity. These entities are tracked in some system of record.
Entity Discovery in Practice
How do you find entities in the wild?
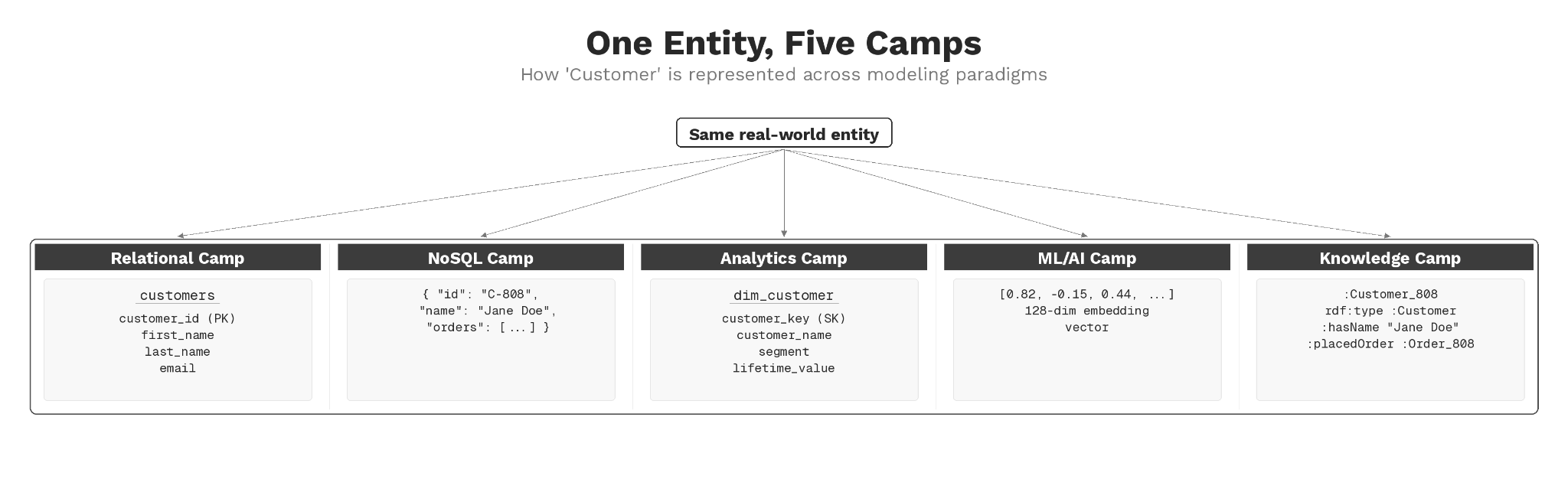
Here’s where the Mixed Model Artist perspective becomes essential. Each of the five camps we covered in Chapter 1—Relational, Analytics, Application, ML/AI, and Knowledge—has its own way of discovering and defining entities. Take the Customer entity from this example. In the Relational camp, you’ll see it as a Customer table with columns: customer_id, first_name, last_name, and email.
Now shift camps. In the Analytics camp, Customer is a dimension table—a slowly changing record joined to fact tables tracking orders, returns, and interactions.
In the Application camp, that same Customer might be a JSON document containing nested properties: a rich object with profile data, preferences, and order history embedded directly within it.
In your ML platform, Customer isn’t a table or a document anymore—it’s a feature vector, a point in space where similarity and distance tell you which customers behave alike.
And in the Knowledge camp? The customer becomes a type node connected to order, product, and company nodes through explicitly modeled relationships.
Figure: One Entity, Five Camps
The kettlebell order from Chapter 1 showed us how the same business object flows through these different systems. Here, we see how the entity concept itself transforms as it moves between paradigms. A Mixed Model Artist knows that customers look different across camps because each camp is optimized for different access patterns and needs. The mastery is recognizing that beneath the syntactic differences lies a unified entity concept, and moving fluidly between representations as the work demands.
Most books cover entities for structured data. This is well-trodden territory, and we alluded to this above, where entities are tables. But here’s what most books gloss over: entities don’t stay in one form. They appear differently depending on the form of data. Let’s have a look.
Entities in Semi-Structured Data
Entities in semi-structured data don’t have the same rigid restrictions or predefined schema as structured data. Consider how we’d model the order and customer entities in JSON:
Order entity:
{
“orderId”: 98765,
“customerId”: 12345,
“orderDate”: “2023-09-03”,
“orderItems”: [
{
“productId”: 54321,
“productName”: “Widget A”,
“quantity”: 2,
“price”: 19.99
},
{
“productId”: 67890,
“productName”: “Gadget B”,
“quantity”: 1,
“price”: 49.95
}
],
“totalAmount”: 89.93
}
Customer entity:
{
“customerId”: 12345,
“firstName”: “John”,
“lastName”: “Doe”,
“email”: “john.doe@example.com”,
“address”: {
“street”: “123 Main St”,
“city”: “Anytown”,
“state”: “CA”,
“zipCode”: “12345”
},
“phoneNumber”: “555-555-5555”
}
Like structured data treats each entity as a table, here each entity is a JSON object. Notice that the order entity references the customer entity via the customerId key. Joining semi-structured data requires more care than in relational databases, but it’s possible—especially using dataframes or parsing using native JSON path extensions (like Snowflake’s VARIANT querying or Postgres’s ->> operators).
The flexibility of semi-structured data is both a blessing and a curse. You can do whatever you want, but you need to think carefully about complexity. When modeling semi-structured entities, consider whether you’re embedding different entities together. Will it remain understandable to others? What happens when several entities are nested in the same structure?
Entities in Unstructured Data
With businesses rapidly incorporating LLMs and AI agents into workflows, you’ll increasingly work with unstructured data—integrating it into multimodal models that may include structured and semi-structured data as well. Unlike structured and semi-structured data, where entities map to tables or objects, unstructured data entities have explicit and implicit layers.
Suppose our e-commerce company has millions of customer reviews in plain text. You want to categorize them by topic and sentiment. The customer review itself—expressed as text—is an entity. But there’s nuance here. Text data often contains multiple layers of entities. You might also care about other entities in the text, such as the customer who wrote it, the product reviewed, or the review date. These are all distinct objects within the text data.
Here’s an example of using Named Entity Recognition (NER) to detect entities in a customer review. NER can pull structured representations from text content: when a customer writes “I bought this jacket in Chicago last Tuesday and the zipper broke,” there are at least four entities embedded in that sentence—a customer (implied), a product (jacket), a location (Chicago), and a time (last Tuesday).
Entities in other unstructured forms—images, video, audio—work similarly. You might consider the file itself an entity. Or you might run object recognition on an image to identify distinct entities within it (e.g, images containing cats). You’d process many files through an object recognition system to tag them accordingly. The same principle applies to video and audio data.
Entities in Metadata
Mechanically, metadata is usually just structured tables, semi-structured JSON, and occasional text, meaning the exact same entity discovery approaches apply as above. But there is a subtle and foundational conceptual shift when dealing with metadata.
With the other use cases—whether operational (such as transactional system records), analytical (such as data-warehouse aggregations), or event-driven (such as streaming logs)—you are fundamentally modeling the business. Your primary objective is to extract and define entities representing the organization’s real-world operations, such as Customer, Product, Order, and Shipment. These entities are the conceptual underpinnings of many businesses.
With metadata, however, you are turning the lens inward to model the data system itself. This represents a profound shift in focus. Instead of describing what the business sells or does, you are describing how the data architecture functions and behaves. Your entities suddenly become abstract concepts related to the infrastructure and governance of data, such as a PipelineRun, which tracks the execution history of a data transformation job; a DataQualityScore, which quantifies the reliability of a dataset; a TableSchema, which defines the structural layout of a table; a UserAccessLog, which records who accessed what data and when; or a LineageEdge, which maps the flow of data between systems.
Crucially, they are still entities. They are concrete, identifiable concepts within the data system’s domain. They still need robust, stable, and unique identifiers to be managed, tracked, and related to one another. For example, a PipelineRun needs a unique ID (perhaps a UUID or a timestamped sequence) to distinguish it from the previous and next run of the same pipeline. A TableSchema needs an identifier to link it back to the specific physical table it describes at a given point in time.
The key difference is in their purpose. Instead of tracking and modeling what the business is doing in the external world (e.g., how many products were sold), these metadata entities track and model what your data architecture is doing internally (e.g., how many pipelines successfully ran, what is the quality score of the sales table, or which data sources feed the customer table). Modeling metadata enables essential capabilities such as data governance, system observability, automated quality enforcement, and sophisticated data discovery.
No matter the form of data, what stays constant is that an entity is a concept. A Customer is a Customer whether it lives in a relational table, a JSON document, a feature vector, latent within a block of unstructured text, or metadata. With that foundation in place, let’s look at how we can tell one entity instance from another.
Instances & Identifiers
How do you know which entities are which? Every entity must be distinguishable from others. Let’s explore ways to tell entities apart and identify them. We’ll start with instances, then move to identifiers.
Instances
An instance of an entity is a specific, unique occurrence of that entity. Consider a simple example: a Person entity. You’re an instance of the Person entity. So are your friends, family, and the billions of people on this planet. Each person is slightly different, and no two people are exactly alike.
Zooming out, here’s a conceptual example of an entity and two distinct instances:
An entity with two distinct instances