AI News for 2/19/2026-2/20/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (262 channels, and 12582 messages) for you. Estimated reading time saved (at 200wpm): 1242 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Congrats to the ggml + Huggingface team, note the Opus 4.6 METR debate, and read Chris Lattner’s Claude C Compiler analysis. But those aren’t the top stories.
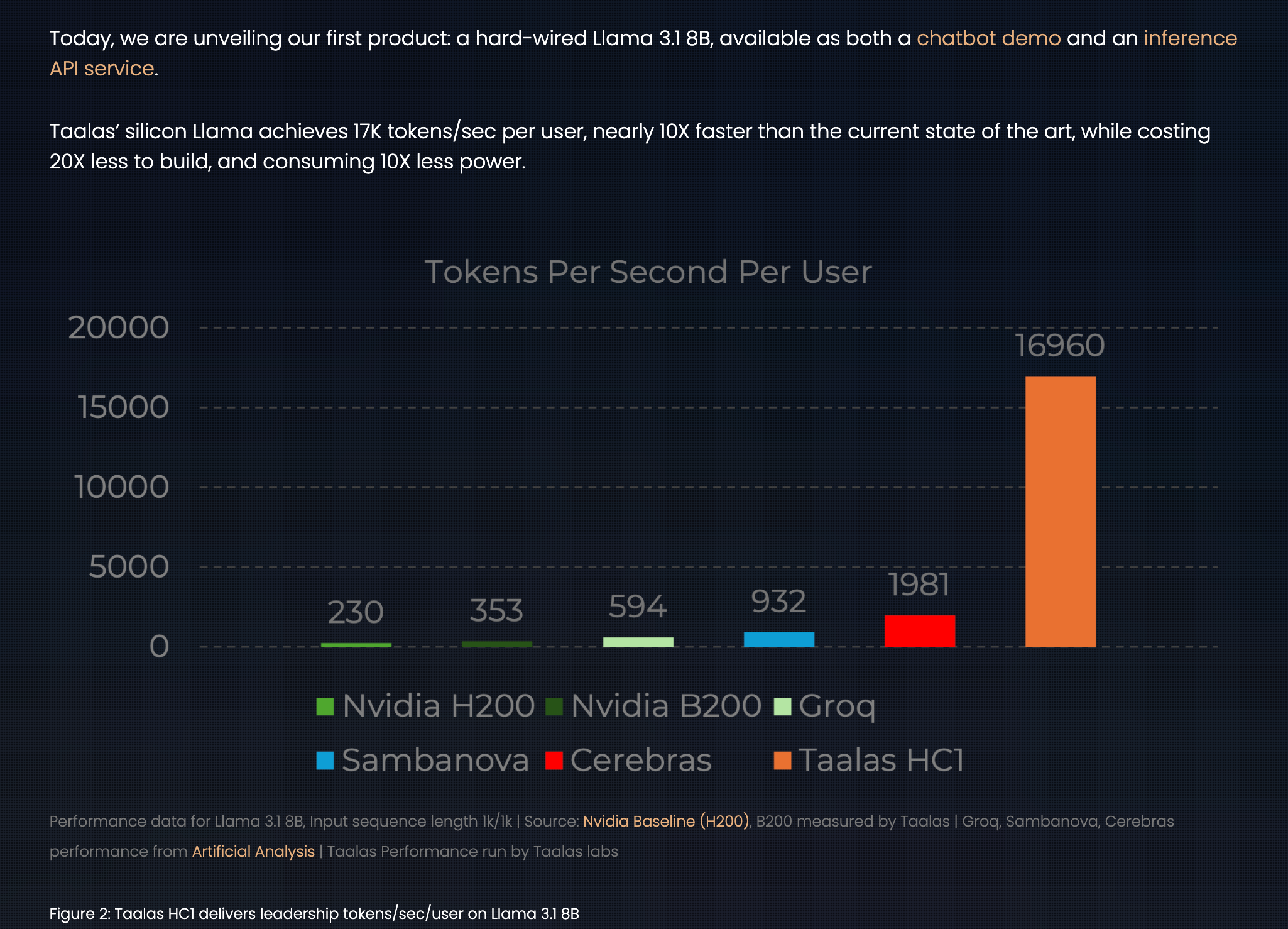
Today, 2.5 year old Taalas announced a shockingly fast 16,960 tokens per second per user production API service for the Llama 3.1 8B model (launched July 2024):
While there are some other non-speed gains (less build cost and power draw), it is also offset by some other footnotes on quantization (which they note the HC2 will resolve with standardized low precision FP4).
This is an impressive result…. that we have no idea how to productize yet. And anytime there is a huge capability overhang opening up, AI Engineers should rush in to figure out the “capability market fit”.
As for the overall proposition of going custom ASIC, we’re still thinking about this week’s Latent Space with Martin Casado and Sarah Wang, where Martin reiterated his conviction in the math of doing custom accelerators (ASICs) PER MODEL, essentially “baking the LLM into silicon”, foreshadowing the OpenAI Broadcom deal:
Martin: It makes sense to actually do a custom ASIC if you can do it in time. The question now is timelines, but not money because rough math:
- If it’s a billion dollar training run, then the inference for that model has to be over a billion, otherwise it won’t be solvent.
- So let’s assume if you could save 20%, (which you could save much more than 20% with an ASIC), that’s $200 million.
- You can tape out a chip for $200 million.
Right? So now you can literally like justify economically, not timeline wise. That’s a different issue.
swyx: An ASIC per model, because that, that’s how much we leave on the table every single time we do generic Nvidia.
Martin Casado: Exactly. No, it, it is actually much more than that. You could probably get, you know, a factor of two, which would be 500 million. Typical MFU would be like 50.
We understand the tradeoffs that custom chips offer faster/cheaper inference in exchange for lower model quality (by being, in Taalas’ case, 1.5 years behind the frontier), but that gap is virtually certain to close as LLMs continue to standardize in architecture and, more to the point, OpenAI and others start doing fully integrated model-chip codesign as Martin predicts. It’s not even about the cost savings at this point - the potential of actual frontier quality + >20,000 tok/s inference is incomprehensible to AI Engineers of today and we should start those thought experiments and product surfaces today with an expectation that we’ll get there in under 2 years from today.
AI Twitter Recap
Frontier model evals: Gemini 3.1 Pro, SWE-bench, MRCR, and “bipolar” real‑world performance
- Gemini 3.1 Pro shows strong retrieval + mixed agentic usability: Context Arena’s MRCR update reports Gemini 3.1 Pro Preview near-ties GPT‑5.2 (thinking:xhigh) on easier retrieval (2‑needle @128k AUC 99.6% vs 99.8%) and notably stronger on harder multi‑needle retrieval (8‑needle @128k AUC 87.8%, beating GPT‑5.2 thinking tiers reported there) (DillonUzar). Separately, Artificial Analysis highlights a likely underappreciated angle: token efficiency + price; they claim their Intelligence Index suite cost $892 on Gemini 3.1 Pro Preview vs $2,304 (GPT‑5.2 xhigh) and $2,486 (Opus 4.6 max), with fewer tokens consumed than GPT‑5.2 in their runs (ArtificialAnlys).
- But engineers report “bench strength, product weakness”: multiple threads complain Gemini’s tooling/harnesses lag—e.g., model availability inconsistencies in the CLI and buggy agent behavior in “Antigravity,” plus a worrying “UI lies / model lies” confusion where the app claims Gemini but reports Claude underneath (Yuchenj_UW, Yuchenj_UW). Even enthusiastic takes (“faster horse”) are juxtaposed with frustration about actually using it day‑to‑day (theo).
- SWE-bench Verified evaluation methodology matters again: MiniMax points to an “independent look” at SWE-bench Verified results for MiniMax M2.5 under the same setup, implying earlier comparisons across labs may have been apples-to-oranges (MiniMax_AI). Epoch AI explicitly acknowledges this failure mode: they updated SWE‑bench Verified methodology because their prior runs were systematically different from others, and now see results closer to developer‑reported scores (EpochAIResearch).
- Benchmark oddities are prompting “what are we measuring?” debates: one example—frontier models “smash ARC-AGI” yet struggle with Connect 4, suggesting ARC‑style puzzles may capture only a narrow slice of spatial/game reasoning despite being designed to resist overfitting (paul_cal). Another thread expects only a few models to make progress on a “simple harness” for ARC‑AGI‑3 and flags cost as the constraint (scaling01, scaling01).