The Best Image Model is back!
AI News for 2/25/2026-2/26/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (263 channels, and 12920 messages) for you. Estimated reading time saved (at 200wpm): 1283 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Congrats to Perplexity on Computer and for replacing Bixby as default AI on hundreds of millions of Samsung phones going forward, but those are more consumery news.
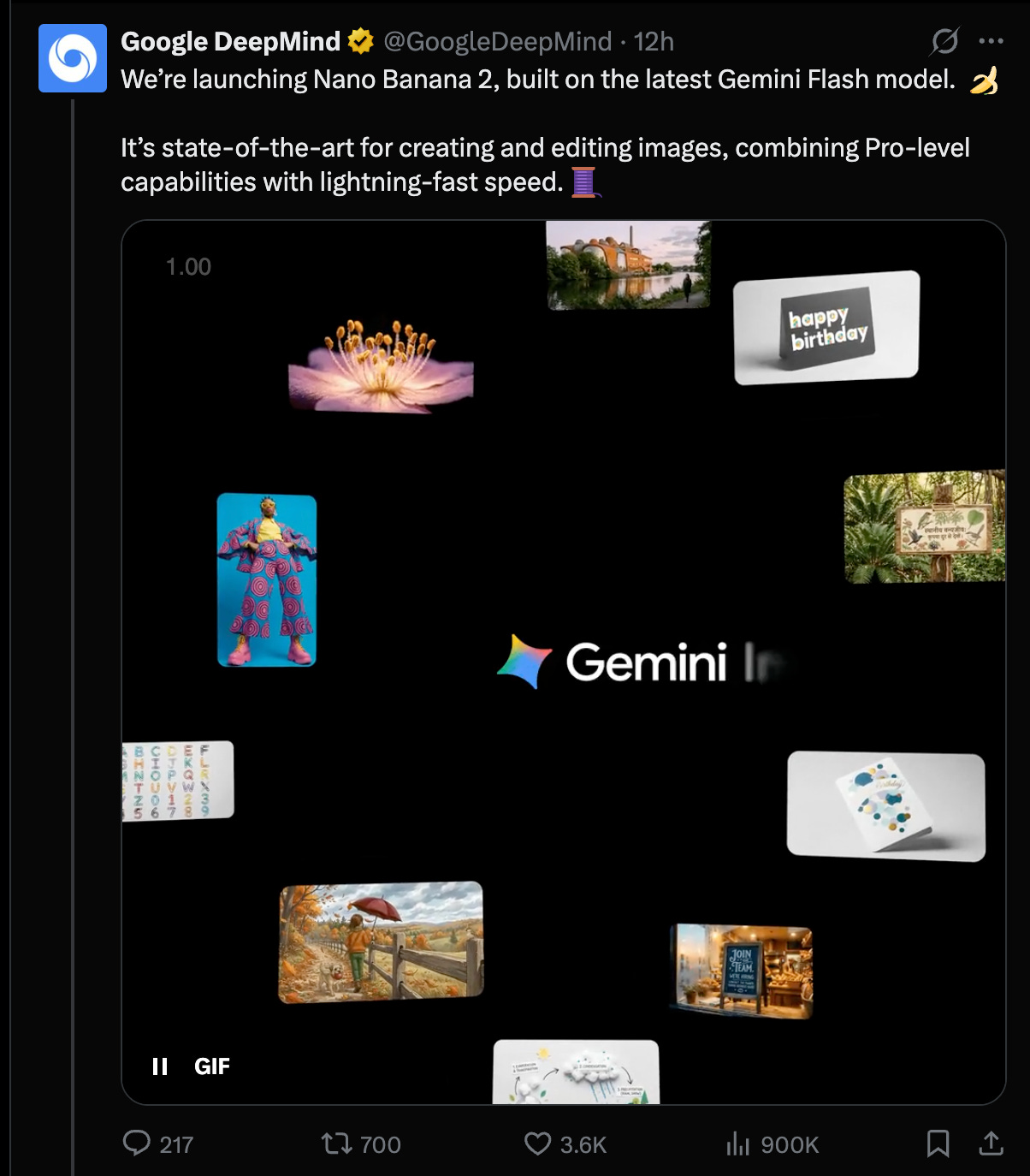
News that AI Engineers can use from today is Nano Banana 2, which is more formally called 3.1 Flash Image. The big story is the pricing: it is rated the #1 image model in the world per Arena and ArtificialAnalysis, and yet costs half the price (At $67/1k images, vs Nano Banana Pro ($134/1k) and GPT Image 1.5 ($133/1k) for generation, and FLUX.2 [max] at $140/1k images for editing).
It comes with 6 character consistency and search grounding, and great text rendering. Of course every generation is stamped by SynthID.

Of course, there’s no research detail or paper whatsoever, so our coverage ends here.
AI Twitter Recap
Google’s Nano Banana 2 (Gemini 3.1 Flash Image Preview) and the new image-eval meta
- Nano Banana 2 launch + rollout footprint: Google and DeepMind shipped Nano Banana 2 (aka Gemini 3.1 Flash Image Preview) as a “Flash-tier” image generation/editing model rolling out across Gemini App, Search (AI Mode/Lens), Flow, Google Ads, and in preview via AI Studio / Gemini API / Vertex AI (Google, GoogleDeepMind, GeminiApp, sundarpichai, demishassabis). Product claims emphasize world knowledge, improved i18n text rendering, aspect ratio control, upscaling up to 4K, and multi-subject consistency (e.g., “up to 5 characters & 14 objects”) (Google, joshwoodward).
- Arena/Artificial Analysis results + pricing signal: Multiple evaluators report Nano Banana 2 taking #1 Text-to-Image and strong editing placements, while undercutting “Pro” pricing—e.g., $67 / 1k images cited by Artificial Analysis vs ~$133–134 for GPT Image 1.5 and Nano Banana Pro (ArtificialAnlys, arena, kimmonismus). Arena added image subcategories and highlighted largest gains in text rendering and 3D imaging/modeling (arena). This is also a reminder that leaderboards are becoming product levers: “day-0” integrations (e.g., fal) and prompt packs/templates ship alongside eval wins (GeminiApp templates, GoogleAI prompts).
- Real-time search-conditioned generation: Google repeatedly frames NB2 as powered by real-time information and images from web search (not just static pretraining), positioning it as “more accurate views from any window in the world” style demos (sundarpichai).
- Downstream availability: Nano Banana 2 quickly appeared in third-party products, including Perplexity Computer (AravSrinivas).
Agentic coding + productized “tasks”, memory, and evals (and the backlash against complexity)
-
Agents “just work” more often now, but still fail off-distribution: Several practitioners describe a step change in reliability/utility for coding agents across recent frontier models (e.g., GPT-5.2 / GPT-5.3 Codex, Opus 4.6, Gemini 3.1), shifting from “proof of concept” to something like delegating CLI work to juniors (teortaxesTex, paul_cal). Others caution that advanced ML/data engineering remains brittle off-distribution (michalwols, MParakhin).
-
“Tasks” as the new packaging layer: Microsoft’s Copilot Tasks pitches “talk less, do more” delegation with user-visible plans and control, in “research preview” (mustafasuleyman, yusuf_i_mehdi).
-
Persistent memory becomes table stakes—and introduces interoperability pain: A widely shared update claims Claude rolled out auto-memory (“remembers what it learns across sessions”) (trq212), echoed in the Claude ecosystem (omarsar0). Developers immediately hit workflow friction when memory/state lives in tool-specific hidden directories (hurting “multi-agent, multi-tool” continuity) (borisdayma).
-
Tooling ships fast: PR bug-fixing bots, code↔design loops, and editor-level improvements:
- Cursor Bugbot Autofix automates fixing issues found in PRs (cursor_ai, aye_aye_kaplan).
- OpenAI’s Codex “code → design → code” roundtrip with Figma aims to make UI iteration less lossy (OpenAIDevs, figma).
- VS Code’s long-distance Next Edit Suggestions focuses on predicting where not to edit and supporting “flow” (code, pierceboggan, alexdima123).
-
Eval inflation + benchmark gaming concerns: Threads call out that high leaderboard scores can mask token-inefficient reasoning and failures on “bullshit tests” (e.g., repeated-token “strawberry” variants), warning against over-trusting HLE/GPQA-style metrics without cost accounting (scaling01). Arena responds by adding more granular test regimes like Multi-File React for code models (arena).
-
Complexity is the real tax: A recurring engineering concern is that “10k LOC/day” bragging creates long-term complexity debt—agents make it easier to ship, not easier to maintain (Yuchenj_UW). Another angle: coding agents can create implicit lock-in if they “sloppify” your codebase such that working without them becomes painful (typedfemale).
Perplexity’s distribution + retrieval stack: Samsung integration and new embedding models
- Samsung S26 system-level Perplexity (“Hey Plex”): Perplexity says every Galaxy S26 will ship with Perplexity built in, including a wake word and deep OS integration; Bixby routes web/research/generative queries to Perplexity while handling on-device actions (perplexity_ai, perplexity_ai, AravSrinivas). This is framed as part of a broader partnership that also targets Samsung Internet and optional default search positioning (perplexity_ai).
- pplx-embed / pplx-embed-context released (MIT): Perplexity launched two embedding model families at 0.6B and 4B, including a “context” variant intended for doc chunk embeddings in RAG; both are MIT licensed and available via HF + Perplexity API, with a paper (arXiv:2602.11151) (perplexity_ai, perplexity_ai, alvarobartt). They also disclose internal benchmarks like PPLXQuery2Query / PPLXQuery2Doc with 115k real queries over 30M docs from 1B+ pages (perplexity_ai). Arav claims the embedding models are “industry leading” (AravSrinivas).
- Strategic read: The pair of moves—OS distribution + retrieval primitives—suggests Perplexity is trying to own both front door (assistant entry point) and core search stack (embeddings + evals), rather than depending on third-party platforms.
Inference, kernels, and infra: MoE support, heterogeneous hardware, and KV movement
- MoE becomes “first-class” in 🤗 Transformers: Hugging Face shipped deeper MoE plumbing (loading, expert backends, expert parallelism, hub support) and highlights collaboration on faster MoE training (including with Unsloth) (ariG23498, mervenoyann).
- DeepSeek and multi-hardware inference seriousness: Early in the batch, DeepSeek is called out as “serious about inference support on diverse hardware” (teortaxesTex). Separately, a DeepSeek DualPath detail describes staging KV cache in decode-server DRAM then moving it to prefill GPUs via GDRDMA to avoid local PCIe bottlenecks (JordanNanos). This reflects a broader shift: inference is increasingly a systems architecture problem, not just kernel-level optimization.
- Kernel coverage and GPU generations: vikhyatk describes building inference kernels across NVIDIA architectures (sm80→sm110) and notes edge-device ISA issues like Orin CPU lacking SVE (vikhyatk, vikhyatk).
- Quantization isn’t uniformly safe: Evaluations show MiniMax M2.5 GGUF quantizations degrade much more than expected vs Qwen3.5, arguing “just take Q4” doesn’t generalize across model families (bnjmn_marie).
World models, agents in simulators, and “multiplayer” environments
- Solaris: multiplayer Minecraft world modeling stack: A major research drop proposes that world modeling should focus on shared global state rather than pixel rendering, releasing (1) a multiplayer data collection engine, (2) a multiplayer DiT with a “memory efficient self forcing design” trained on 12.6M frames, and (3) a VLM-judge evaluation suite for multi-agent consistency (sainingxie, georgysavva). The pitch: multi-agent capability requires a shared representation beneath individual views.
- LLMs as embodied controllers (toy but telling): A CARLA→OpenEnv port shows a small Qwen 0.6B learning to brake/swerve to avoid pedestrians in ~50 steps using TRL + HF Spaces (SergioPaniego). This exemplifies a trend toward “LLM+env” loops where reversibility is limited and mistakes persist.
Governance flashpoint: Anthropic vs the Pentagon on surveillance and autonomous weapons
- Pentagon pressure campaign reported, then Anthropic responds publicly: A widely shared claim says the DoD issued a “final offer” to Anthropic, including threats to label it a “supply chain risk” and demands for unrestricted military use (KobeissiLetter). Anthropic then published a CEO statement drawing explicit red lines: no mass domestic surveillance and no fully autonomous weapons (given current reliability), also alleging threats involving the Defense Production Act (AnthropicAI). A widely quoted excerpt is reposted with detail (AndrewCurran_).
- Industry reaction + solidarity mechanics: The stance triggered strong support from prominent researchers/engineers, framing it as values-under-pressure rather than “policy theater” (fchollet, TrentonBricken, awnihannun). A petition aiming to coordinate “shared understanding” reportedly gathered signatures from OpenAI/Google staff (jasminewsun, sammcallister, maxsloef). This is notable as an explicit attempt to prevent a race-to-the-bottom dynamic via transparency about where each lab stands.
- Why this matters technically: The core dispute is about capability vs. reliability and “lawful use” language being misaligned with what frontier models can safely do today. Reliability concerns show up elsewhere in the dataset too (e.g., minimal security test cases where models leak confidential info even when instructed not to) (jonasgeiping, random_walker).
Top tweets (by engagement)
- Anthropic CEO statement on DoD demands (surveillance + autonomous weapons red lines) — @AnthropicAI
- Google launches Nano Banana 2 / Gemini 3.1 Flash Image Preview (broad rollout + “pro at flash speed”) — @GeminiApp, @sundarpichai, @GoogleDeepMind
- Perplexity + Samsung S26 system-level integration (“Hey Plex”) — @perplexity_ai
- Claude connectors available on free plan (150+ connectors) — @claudeai
- Pentagon vs Anthropic “final offer” reporting thread — @KobeissiLetter
- Claude Code auto-memory is huge (developer reaction) — @trq212