Welcome to Chapter 3!
Does data modeling even matter anymore? I often hear that data modeling is irrelevant and antiquated, especially in the age of AI. There are definitely some strong arguments why this might be true. But I often feel like these arguments are incomplete and miss the bigger picture. Here, I dissect the arguments about why data modeling doesn’t matter, and also why it matters more than ever.
Note: This used to be Chapter 2 of the book, but now it’s moved up by one.
In the middle of editing Part 2 (Chapters 4-12), covering the building blocks of data modeling. Starting next week, you’ll start seeing these chapters dropping, starting with Chapter 4 - The Forms of Data.
Thanks,
Joe
In Brazilian Jiu-Jitsu, there is a universal phenomenon known as the “white belt spaz.” When a brand new student steps onto the mat to spar for the first time, they don’t know the techniques, so they compensate with pure, chaotic exertion. They thrash around, try to muscle their way out of bad positions, and move at a million miles an hour. For exactly one minute, they feel incredibly dangerous. Then, their grips give out, their lungs burn, and they get effortlessly choked out by a smaller, calmer opponent who is barely breathing hard. I’ve been on the receiving end of the “white belt spaz,” and it’s definitely a tornado of energy.
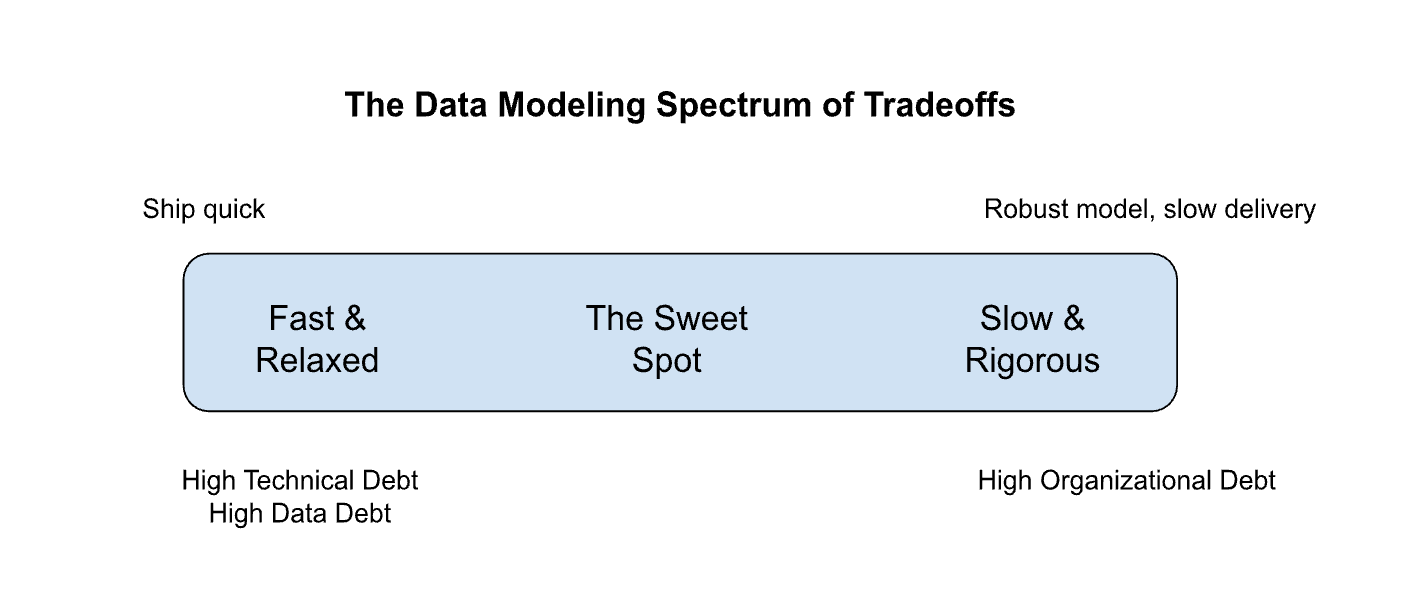
I hear the data engineering equivalent of the white belt spaz all the time. It usually sounds like “agile development” or “moving too fast to model.” True agile development actually requires stricter foundational discipline, not less. Throwing data into a database and figuring it out later isn’t agile; it’s just reckless. True agility comes from having a solid model that allows you to pivot safely.
True agile development actually requires stricter foundational discipline, not less.
At a conference last year, I gave a talk on Mixed Model Arts and why data modeling matters more than ever. During the Q&A, a data engineer stood up and said, “Honestly, data modeling feels like something from the ’90s. We just throw data into the lake and figure it out later. And now with AI, why do we need to know about data modeling?” Half the audience nodded. The other half looked uncomfortable but didn’t push back. I’ve heard versions of this argument countless times—from startups to Fortune 500 companies, from junior software and data engineers to CTOs. So let’s confront it directly.
Is Data Modeling a Waste of Time?
You might ask yourself, why bother with data modeling? This is a fair question. In this case, I’m talking about intentional data modeling. As you’ll learn, data is always modeled—intentionally or unintentionally—with varying degrees of outcomes. The question isn’t whether you’ll have a data model. It’s whether you’ll have a good one.
Here are some arguments I hear about why data modeling is a waste of time.
“Data modeling is too much work.”
“Data modeling takes too much time.”
“We don’t have the resources or personnel for data modeling.”
“We’re a small company, and our business is too small to model.”
“We’re a startup moving too fast for a model to matter.” “
Our company is too big and complicated to model.”
“Data modeling is old and antiquated.”
“AI can just do it all.”
Most of these are understandable concerns, and I can’t say they’re wrong. Over the years, data modeling has earned a reputation for being slow, cumbersome, and laborious. But let’s look more carefully at the underlying arguments. I find they fall into three categories: the claim that data modeling is antiquated and irrelevant, the argument about complexity, and the reality of resource constraints.
Antiquated and Irrelevant
This is the most provocative argument, and the one I hear most often from people who should know better. Data modeling might be seen as antiquated and irrelevant for different reasons depending on which camp you’re in—and if you recognize these arguments, it’s because they map directly to the camps we identified in Chapter 1, each dismissing data modeling from their own vantage point.
- For software and application developers, data modeling is often associated with rigid methodologies such as relational data modeling and waterfall development—both of which are slow and inflexible compared to NoSQL and agile approaches. This perception leads people to believe data modeling is unsuitable for the fast-paced nature of modern software development.
- In analytics, the emphasis is on rapid insights and quick decision-making. Traditional approaches like dimensional modeling emphasize upfront planning and detailed star schema design, which some consider cumbersome and tedious. Analysts and data engineers might throw their data into One Big Table (OBT), which has a lower upfront cost for intentional data modeling. While OBT can be a useful output layer for consumption, using it as an excuse to avoid understanding the underlying relationships is a recipe for silent errors.
- In machine learning and AI, some argue that algorithms can automatically discover patterns and relationships with little to no data preparation, making explicit data models obsolete. And modern large language models (LLMs) can magically create a data model for you. Why model your data or understand what’s in it? Just throw it into deep learning or LLM and move on.
Each of these camps confuses a particular approach to data modeling with data modeling itself. That’s like saying cooking is a waste of time because you don’t like one recipe. As you’ll discover in this book, choosing the right data modeling approach for your situation—whether simple or complex—greatly benefits software development, analytics, and ML/AI. You might opt for simplicity. You might opt for rigor. As long as you’re intentional, that’s what matters.
Complexity: Big and Small
Those working in large, global companies often argue that their business is “too complex to model.” This argument presents data modeling as a binary choice—either you spend excessive time and resources on it, or you don’t do it at all. This is a false dichotomy.
While capturing every minute detail of a vast organization might be impractical, focusing on specific business domains can yield significant benefits. A marketing department could create a data model to understand customer behavior and campaign effectiveness. A finance team could model their financial transactions to analyze spending patterns. Targeted modeling provides valuable insights for decision-making and impactful AI models, even within highly complex businesses.
What if you don’t work at a giant mega-corporation? Data modeling is arguably more important—and easier—if you’re at a smaller company. Your business processes and data structures are relatively simple in the early stages. This provides an ideal opportunity to establish data models that can scale as the business grows. Ignore data modeling until you become a big enterprise, and you’ll get to untangle a gigantic (and preventable) mess, if it’s even possible at that point.
The complexity of a business shouldn’t deter data modeling efforts. That’s a dangerous red herring. Complexity should encourage a more targeted, strategic approach, regardless of your business’s size.
Resource Constraints
In today’s pressure-cooker business environment, people are expected to do more with less—often a lot less. There’s a perception that investing in data modeling isn’t worth the effort. And people aren’t usually incentivized to model data. Often, people are handed a pile of data and told to “Do something with this data. ASAP.”
In a 2026 survey I conducted with 1,100 data practitioners, 59% said time pressure was their pain point in data modeling. There’s no doubt that time is a significant constraint. It forces teams to adopt “agile” methodologies in which tasks—no matter their nature—are broken into short sprints. This may not allow sufficient time to develop well-thought-out data models, leading to rushed decisions and potential oversights. In an upcoming chapter, I’ll dive deeper into why I think “agile” is done wrong and how to improve it to better support faster data model delivery.
Another constraint is people. Layoffs or hiring freezes can leave teams understaffed. Human resources are often strained by a lack of data modeling expertise, leading teams to choose inappropriate modeling techniques or to ignore data modeling altogether.
Financial constraints are another factor. Cheap computing may encourage bypassing data modeling—“Just throw more compute at a query”—but it’s an expensive, short-term shortcut. The popularity of generative AI might seem like another shortcut. Just throw an all-knowing AI at your data. But this comes at the cost of deep understanding—the very thing that makes data useful.
These resource constraints are real, and I empathize. But they often lead to trade-offs that result in a ticking time bomb of half-baked models and deferred consequences. Let’s look at what those consequences actually are.
Why Data Modeling Matters
We just looked at arguments against data modeling. Now let me tell you why it matters anyway. And I’ll try to go beyond platitudes, because I know you’ve heard “data quality is important” a thousand times. Let me ground this in what I’ve actually seen.
Aligning Data with “The Business”
“The Business” loosely refers to any organization—a company, an academic institution, a non-profit, or any other place you work. Every organization has its way of using data. Data modeling aligns data with business processes, vocabulary, rules, information flows, and workflows. Without this alignment, you get the kind of chaos I described at the start of Chapter 2: six databases, no shared definitions, and $400K in monthly refunds.