
This is the last in our GPT-5 coverage of the vibes, bootstrapping, vision, and Router.
ICYMI, we are back with the AI Engineer CODE Summit, Nov 19-22 in NYC! Summits are usually >10x oversubscribed, with the most high signal content & attendees. If you are keen on developer productivity and what’s new in SWE agents, apply today.
The new GPT-5-Codex launches today, capping off perhaps the most intense month of vibe shifts in Coding Agents in recent memory (click to expand):
For a little over a year now, starting with Claude 3.5 Sonnet in June, 3.7 Sonnet and Claude Code in Feb, and Claude 4 in May, Anthropic has enjoyed an uncontested dominance in coding usecases, leading to an epic runup to $5B in revenue (10% of which is Claude Code) and a $183B valuation1, adding $122B in market cap.
That seems to have ignited a fire in OpenAI, which of course shipped the original 2021 Codex that kicked off GitHub Copilot, the original AI coding tool with 182 creators and counting2, and whose GPT3 inspired Debuild which presaged all the vibe coding startups, and of course started to reprioritize coding abilities in o1 and GPT 4.1.
GPT-5-codex’s 74.5% on SWE-bench (full 500) is kind of a wash vs the (infamously memed to pieces) GPT-5 thinking’s performance of 74.9% (477 task subset), so what is the cause of this major shift in GPT5 sentiment?
Well, for one, the Codex team has been COOKING.
Factor 1: Many Faces, One Agent
As Greg says in today’s podcast, MANY people pitched in:
“At the beginning of the year, we set a company goal of an agentic software engineer by the end of the year. And figuring out exactly what that means and how to substantiate that and how to bring together all the opportunity and all the kind of compute that we have to bear on this problem. That has been a great undertaking for many, many people at OpenAI.”
The original A-SWE agentic harness was called 10X, and did live in the terminal, but since launching the new Codex CLI and then “ChatGPT Codex” (now Codex Cloud) and then the IDE extension (now at 800k installs after 2.5 weeks) and GitHub code review bot, there is now a complete set of interfaces to match all needs:
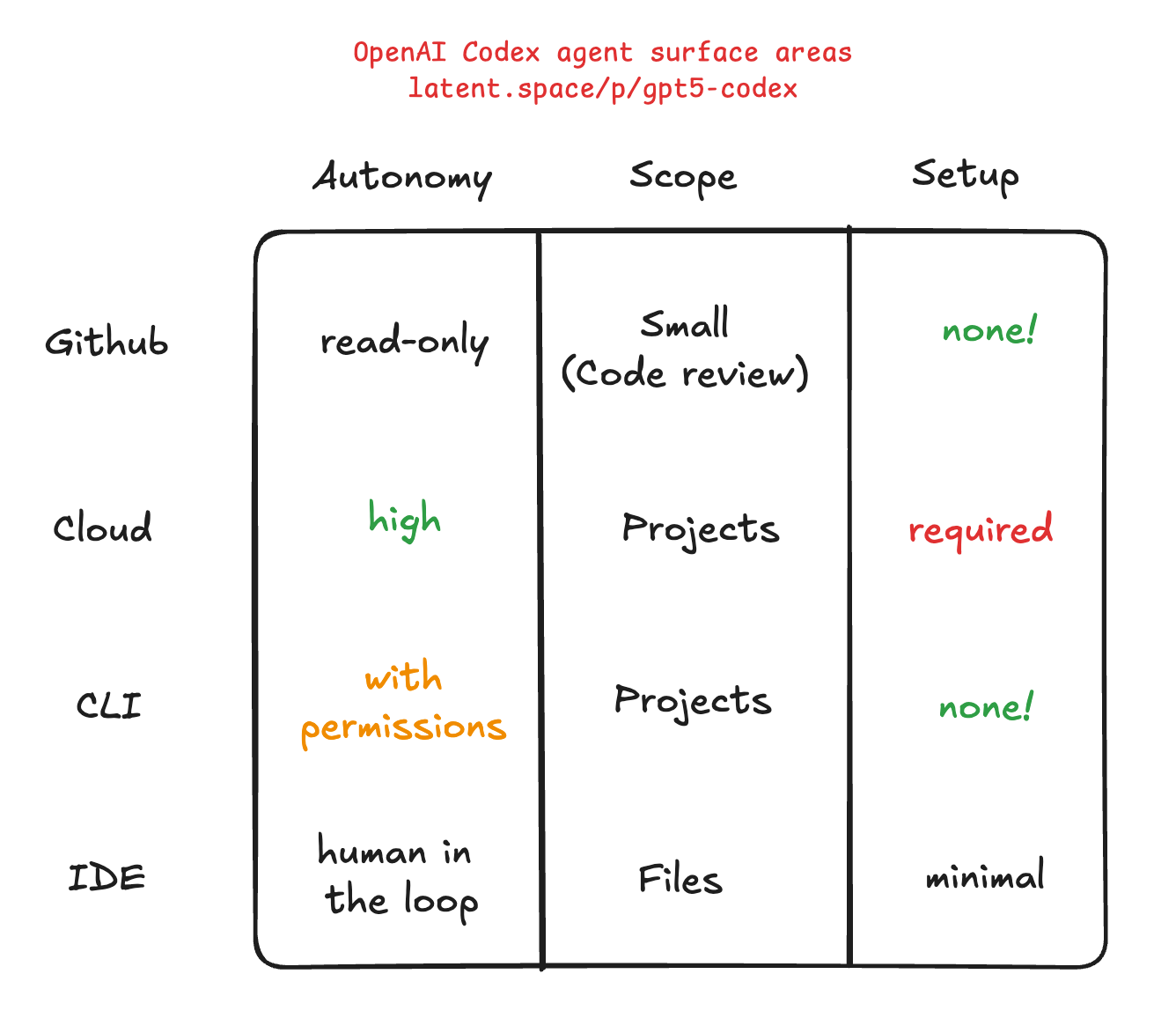
Here’s our rough illustration of the various tradeoffs in the Codex universe:
Although perhaps causing the least fanfare, the @codex code review bot might have the highest utility because of it’s very tight scoping:
“We started to notice that the big bottleneck for us was with increased amounts of code needing to be reviewed is like the amount of review simply that people had to do on the teams.
We decided to really focus on a very high signal Codex mode where it's able to review a PR and really think deeply about the contract and the intention that you were meaning to implement and then look at the code and validate whether that intention is matched and found in that code.
And it's able to go layers deep, look at all the dependencies, think about the contract and really raise things that some of our best employees, some of our best reviewers wouldn't have been able to find unless they were spending hours really deeply thinking about that PR.
We released this internally first at OpenAI. It was quite successful and people were upset actually when it broke because they felt like they were losing that safety net, and it accelerated teams and including the Codex team tremendously.”
Factor 2: Better Post-Training Qualities
We can’t see the datasets of course, but the other thing that OpenAI always emphasizes about their work is the tight integration of research and product. In today’s podcast we also heard a few references towards some of the desired qualities:
Variable Grit
Thibault Sottiaux:
“One of the things that this model exhibits is an ability to go on for much longer and to really have that grit that you need on these complex refactoring tasks.
But at the same time, for simple tasks, it actually comes way faster at you and is able to reply without much thinking. And so it's like this great collaborative where you can ask questions about your code, find where this piece of code is that you need to change or better understand, plan. But at the same time, once you let it go onto something, it will work for a very, very long period of time.
We've seen it work internally up to seven hours for very complex refactorings. We haven't seen other models do that before. And we also have really worked tremendously on code quality. And it's just really optimized for what people are using GPT-5 within Codex for.
This tenacity judiciously applied is what makes GPT-5-Codex a much more useful agentic coding model all-round, not just optimizing for the most difficult problems only and then requiring a model switcher for dumber models (interestingly, it also doesn’t use ChatGPT’s GPT-5 Router we wrote about):
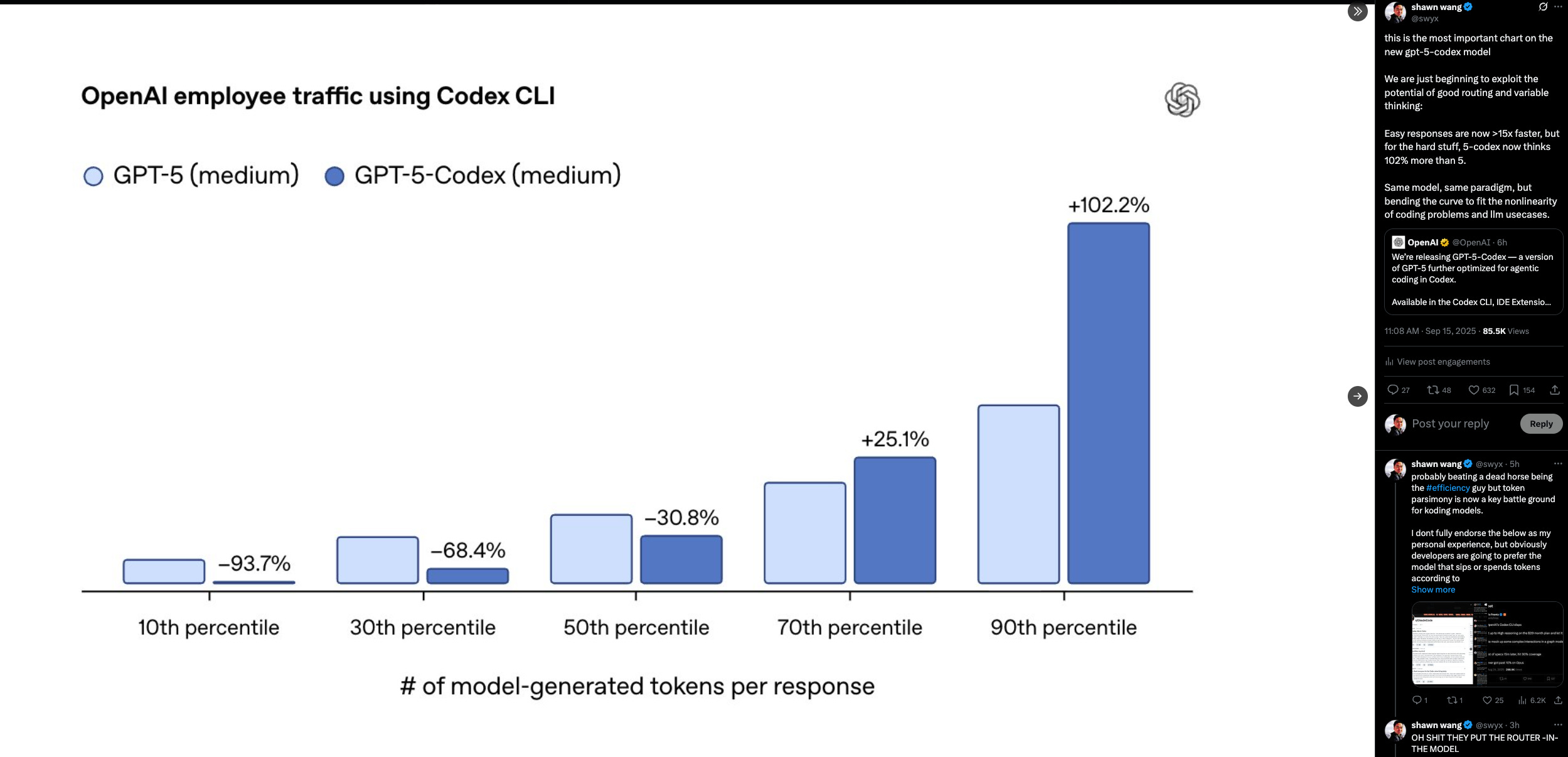
https://x.com/swyx/status/1967651870018838765/photo/1
Getting out of Ruts and pushing back
Greg:
“I remember for GPT-3 and for GPT-4 really focusing on the doubling down problem. Do you remember if the AI would say something wrong and you'd point out the mistake? It would try to convince you that it was right. We're so far past that being the core problem.
It's really amazing to see that we're at a level where even when it's not quite zeroed in on the right thing, it's highlighting stuff that matters. It has pretty reasonable thoughts. Greg Brockman: And I always walk away from these code reviews thinking like, huh, OK, yeah, that's a good point.”
We have no idea how they achieved this level of groundedness, but it is very likely correlated with the measurable drops in hallucination in GPT-5:
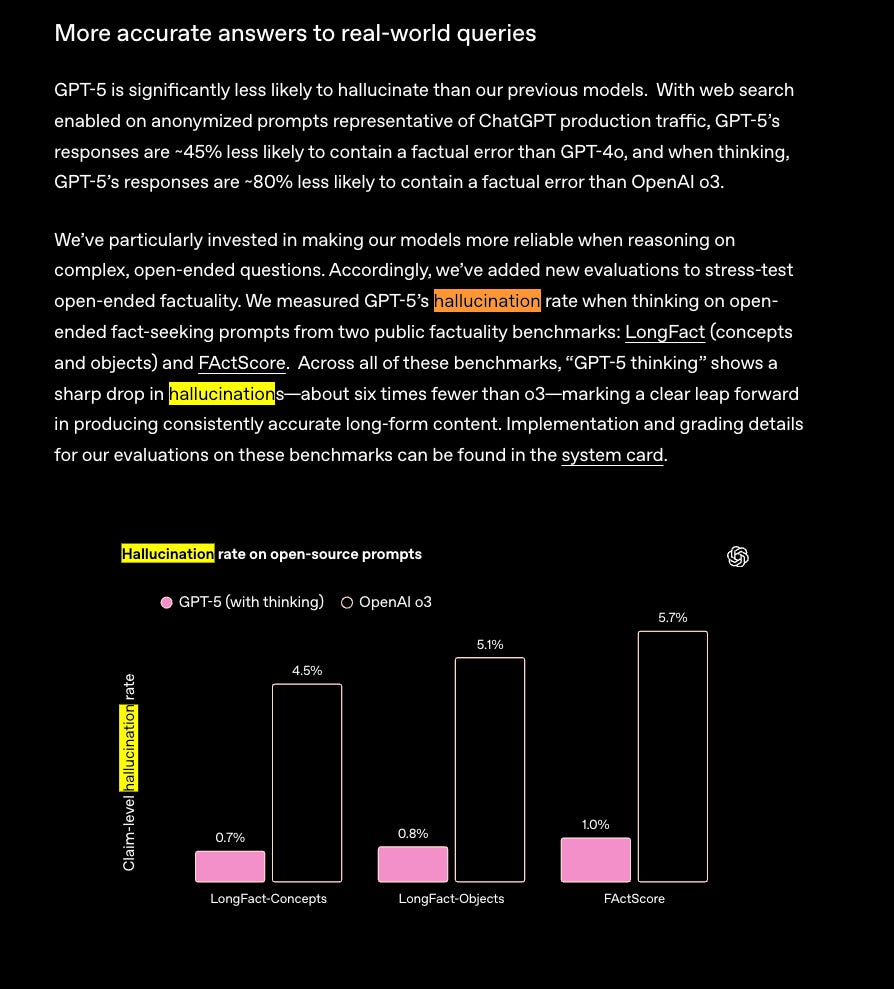
Token Efficiency
One of the dirtiest secrets in the industry is that “price per token” is less and less of a a relevant metric, because reasoning models can often use >10x more tokens to answer questions, especially if they are opaque from you:
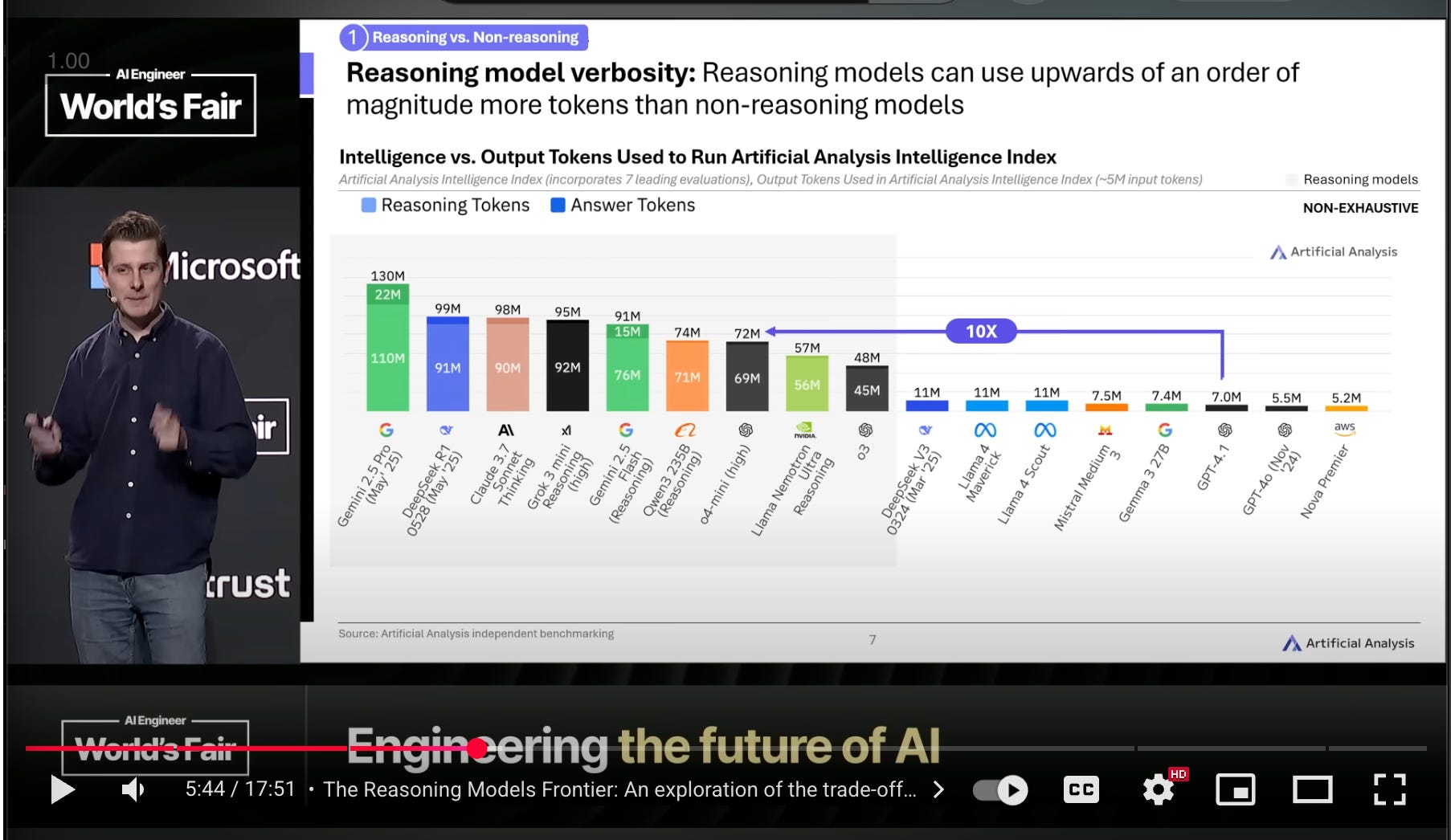
from Artificial Analysis AIE talk
Codex is also particularly tuned for token efficiency here.
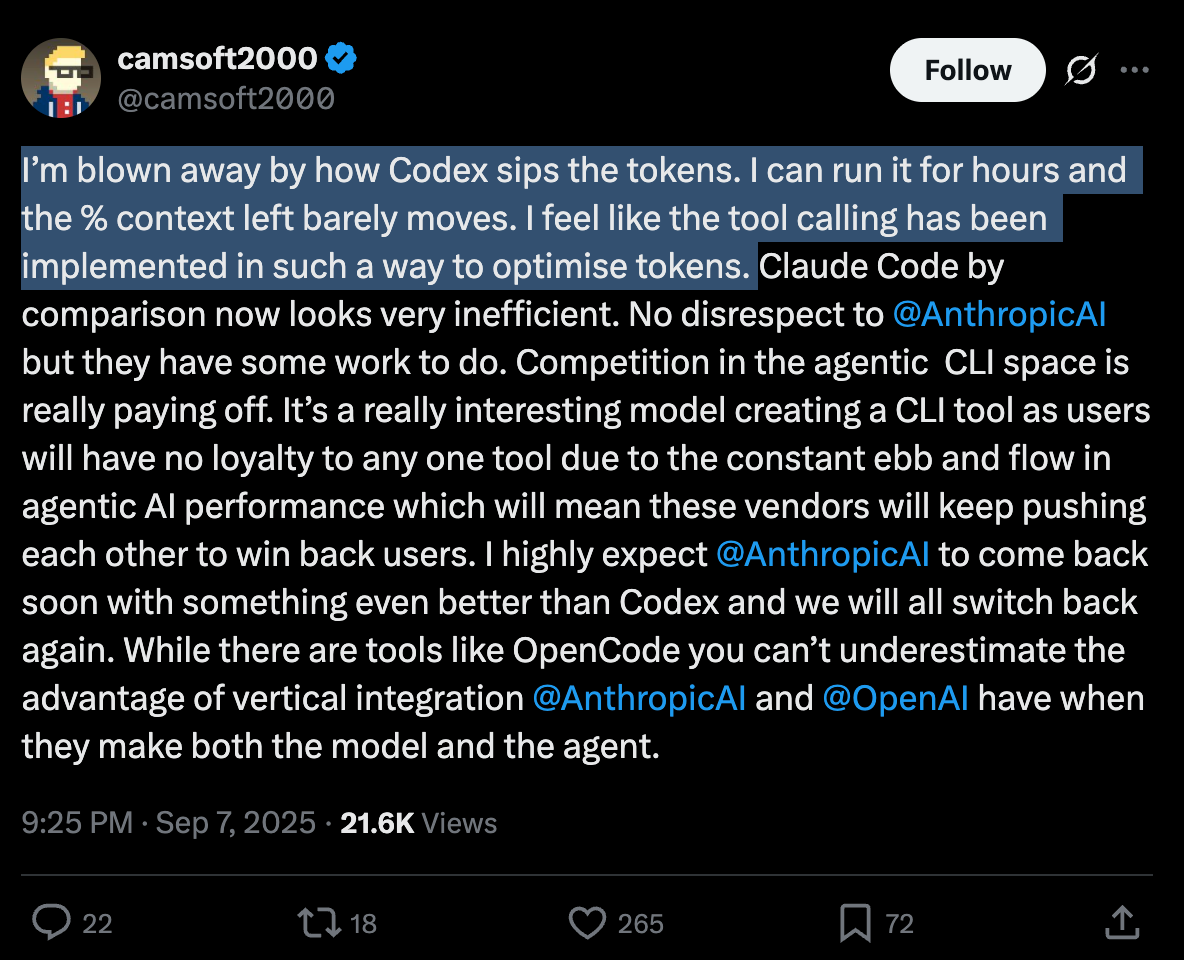
https://x.com/camsoft2000/status/1964787205571772511?s=46
All of these hard-to-articulate qualities add up to one thing: requiring new evals.
Factor 3: New Evals for Agentic Coding
The problem with the negative first reactions around the GPT-5 launch is that most people had not actually used the model in anything real and just reacting to headlines and chart crimes. Those of us who had, myself included, had already gone through the adjustment and sentiment shift, and the GPT-5 Sentiment Flip predictably happened on schedule, just like it did with the o1 release.
The first idea I got immediately after the shooting the GPT-5 for Developers video was “we’re gonna need better vibe checks”. Everyone carries around their favorite spot checks - in our video, Theo did the Hexagon ball thing (and changed tune post release), Simon did PelicanBench, Ben of course tested writing and came back for his Latent Space hat trick.
But the thing I mentioned on the Dev video about GPT-5’s agentic coding abilities is very real: here’s the codebase I actually tried live in the video when we got access:
I had very nice Cursor logs to prep for this blogpost but… they seem to have evaporated from my chat history logs, sorry :/
This was extra impressive because I had been stuck for literal months throwing dozens of hours of Claude Code at it to no avail, whereas GPT-5 “thought with tools” - instrumented the code, had me read back the logs to it, then found the solution.
That’s the problem with the social media pressure for the loudest most confident takes on new models the moment they release - you can’t just run simple one-turn, minimal-tool-call tests to gauge the vibes of the model (my quip is “you can vibecode any website you want, so long as it has blue and purple gradients”).
Even Aider’s polyglot benchmarks aren’t really testing agentic coding, by which I mean multi-turn, multi-step, thinking-with-tools coding agents on real codebases.
The solution was obvious: make a blind taste test of models on real live open source codebases on real tasks and have maintainers rate their performance!
So that is exactly what we did:

We will update this post later with the results of these tests.
In any case, as with all things Koding, Greg Brockman was the frontman driving this shift in OpenAI’s coding capabilities. I had the privilege of interviewing him for the World’s Fair, and in this newsletter issue we are recapping the OpenAI podcast released today and his Latent Space pod released last month - all collected in one place for those just catching up on the great OpenAI coding comeback.
Enjoy!
Greg and Thibault on OpenAI Podcast
Greg Brockman on Latent Space
this episode was recorded and aired last month.
Show Notes
Timestamps
- [00:00:04] Introductions
- [00:01:04] The Evolution of Reasoning at OpenAI
- [00:04:01] Online vs Offline Learning in Language Models
- [00:06:44] Sample Efficiency and Human Curation in Reinforcement Learning
- [00:08:16] Scaling Compute and Supercritical Learning
- [00:13:21] Wall clock time limitations in RL and real-world interactions
- [00:16:34] Experience with ARC Institute and DNA neural networks
- [00:19:33] Defining the GPT-5 Era
- [00:22:46] Evaluating Model Intelligence and Task Difficulty
- [00:25:06] Practical Advice for Developers Using GPT-5
- [00:31:48] Model Specs
- [00:37:21] Challenges in RL Preferences (e.g., try/catch)
- [00:39:13] Model Routing and Hybrid Architectures in GPT-5
- [00:43:58] GPT-5 pricing and compute efficiency improvements
- [00:46:04] Self-Improving Coding Agents and Tool Usage
- [00:49:11] On-Device Models and Local vs Remote Agent Systems
- [00:51:34] Engineering at OpenAI and Leveraging LLMs
- [00:54:16] Structuring Codebases and Teams for AI Optimization
- [00:55:27] The Value of Engineers in the Age of AGI
- [00:58:42] Current state of AI research and lab diversity
- [01:01:11] OpenAI’s Prioritization and Focus Areas
- [01:03:05] Advice for Founders: It's Not Too Late
- [01:04:20] Future outlook and closing thoughts
- [01:04:33] Time Capsule to 2045: Future of Compute and Abundance
- [01:07:07] Time Capsule to 2005: More Problems Will Emerge
Transcript
Introductions
Alessio [00:00:04]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, founder of Kernel Labs, and I'm joined by Swyx, founder of Small AI.
Swyx [00:00:10]: Hello, hello. And we are so excited to have Greg Brockman join us. Welcome. Thank you for having us. Excited to be here. You need no introduction. So I was like mentally going to introduce you. I just get right to it. Congrats on GPT-5, GPT-OSS, like all the stuff that's going on in opening islands. Where are you going to get to all of that? It's really good to have you here. How does it feel? Last week was like a whole maelstrom of releases.
Greg [00:00:33]: releases. Wild. It was absolutely wild to get so many things out in one week. But yeah, so we've released our open source models, which are models that we've been working on for some time. I think really pack in a bunch of the advances that we've been making at OpenAI into a very small form factor, very accessible, now being used by, you know, there's been millions of downloads of that just over the past couple of days. We also released GPT-5, again, something we've been working on for a very long time. And so just having these out in the world and really having done that release process is something that I'm just really excited about. I'm just really proud of the team for doing.
The Evolution of Reasoning at OpenAI
Alessio [00:01:04]: And GPT-5 is the first hybrid model, so most people don't get to choose one model. And that's a whole other drama we will not cover. A whole other thing. But you started originally the reasoning team with Ilya at OpenAI. So maybe can you just give a quick history of reasoning at OpenAI? So you started with just, you know, next token prediction. And then at some point you thought reasoning was something important to build. What was the path from there to GPT-5 where now it's like kind of hidden from the user?
Greg [00:01:31]: Well, I'd say that. After we trained GPT-4, we had a model that you could talk to. And I remember doing the very first. We did the post-training. We actually did a instruction following post-train on it. So it was really just a data set that was, here's a query. Here's what the model completion should be. And I remember that we were like, well, what happens if you just follow up with another query? And it actually was able to then have a response that took into context the whole previous chain of question and answer. And you realize this thing can do chat, right? It can actually talk to you. It can actually use, leverage all of this information, even though it wasn't trained to do it. And I remember we had this question. We had a research meeting with a bunch of people, you know, Jakob, Ilya, Wojciech, others. And the question was, why is this not AGI? Right? This model clearly is not AGI, but it's really hard to describe why, right? It's like able to answer any question you put in front of it. And okay, it's not quite reliable. It makes mistakes. It falls off the rails. Okay. That's a real gap. And so what do we need to do to close that gap? And the most obvious thing you need to do is actually have it test out its ideas in the world, right? Actually do reinforcement learning, like try out some hypotheses, get some feedback and from there become reliable. And this is not a new idea to us, right? If you rewind to even 2017, we were working on Dota, which was all reinforcement learning, no behavioral cloning from human demonstrations or anything. It was just from a randomly initialized neural net. You'd get these amazingly complicated, very sophisticated, very correct behaviors. And it's like. That's the reliability we wanted for our language models. So really the moment we trained GPT-4, we knew that we needed to get to the reasoning paradigm. And it was just a question of how. So we had like 10 ideas, a bunch of different hypotheses about what might work. And people really set out to go and try to make it be reality. And so it was really the labor of many people at OpenAI across many years. And I think the way that this, the progress in this field works is you need to have conviction on a direction. Right. And the first 10 things you try will fail. And most of the things on that list of 10 did not succeed, but we made one of them work. And I think that that's the real key is that we just keep pushing and pushing and that you get little signs of life and you keep growing from there. And so now Jerry runs our reinforcement learning team and has made really great strides there. There's really amazing infrastructure work. People like Wenda, people from the inference side, people like Felipe, there's many people across OpenAI that all come together. And I think it's really important for us to be able to work together to really make this work.
Online vs Offline Learning in Language Models
Swyx [00:04:01]: Amazing. I was going over, you know, when you, when you were with me on the engineer conference, you talked about the Turing paper, which you love and got you started in some ways on your machine learning journey. And I think actually he kind of anticipated the learning machine would be partially online. You know, and I think like, that's one of the questions I always had when reflecting on this journey from like three, four to five, like is learning, like learning started all offline and like all pre-trained. And now it's slowly coming back. It's coming online. Do you think that's accurate?
Greg [00:04:31]: Yeah. I think it's a very interesting question, right? Where does the learning happen? And I think we're still not at the full kind of learning loop that humans do. Yeah. Right. Which it's also not really clear. Are humans fully online? Because it's like, you know, you go to sleep, like there's a lot of, of, you know, sort of back propagation, so to speak, that happens into your long-term memory. So I think that exactly how humans work is not necessarily mapped, you know, represented by how our machines work. But we are moving from a world where it's just, you go and build a machine, you build a machine, train once, and then you're inferencing a ton to a world where there's actually this loop of you inference and you train on those inferencings. And one thing that Ilya used to say a lot that I think is, is, is very, very astute is that when the models are not very capable, right, that the value of a token that they generate is very low. When the models are extremely capable, the value of a token they generate is extremely high. Right. It's something that's like very thoughtful. It's something that's, that's, you know, that's important. And reinforcement learning has this property, right, that you're generating a bunch of data because the model's trying stuff and then you train on that data. And so somehow the model's observations, you know, also normalized by contact with reality or, you know, somehow selected by, by contact with reality, get fed back into the machine. And that is, I think, something that we're starting to get very good at learning from. And the scale required is very different, right? That if you look at pre-training, your, your 10 examples of something doesn't go anywhere, right? You're talking hundreds of thousands of any little type of, of behavior. And then that's what you learn from, which is totally, totally unlike how humans learn. Again, I think, right, if you're, if you think about, recapitulate all of evolution and also think about your 20 years worth of developmental history, there's a lot of just observing the world that happens. There are lots of bits of information that kind of flow through, through your, your senses. But with the reinforcement learning paradigm, if you have 10 examples or a hundred examples of something, right, 10 paths that you're supposed to do, and the model tries a bunch of times that it's actually able to learn from that. And so you really get this leverage. And then you can leverage out of the human curator, creating those tasks and are able to actually get very sophisticated behaviors from the models. And now there's the next step of just having a model that as it goes, it's learning online. We're not quite doing that yet, but the future is not yet written.
Sample Efficiency and Human Curation in Reinforcement Learning
Alessio [00:06:44]: We had this discussion with Noam Brown about simple efficiency. Do you feel like today the bottleneck is still the human data curator that creates these like great tasks for RL to work? Or do you feel like it's still the simple efficiency of the model?
Greg [00:06:57]: Well, the bottleneck is always computing. Right. And, and, and I mean that in a real way, right? It's just like, it's very clear that if you give us a lot of compute that we will find ways to iterate that actually make the most of that, that compute. We are in a world where right now we now have much more sample efficient algorithms, right? With, with the RL paradigm, but it does take a lot of compute still, right? It's like that you have like one task a human created or 10 tasks or a hundred tasks or some small number of those. And then you have a model that tries a bunch of times. Yeah. And then you have a model that tries a bunch of times, not just 10 times, but 10,000 times to try to accomplish one task and you select from those and you learn from, from that. And again, it's like the amount of human leverage you get as a human designer, there's extremely high, but the amount of compute that you have to pour in in order to make it work grows proportionally.
Swyx [00:07:45]: I would say like one way to expend more compute in the learning process, Alan Turing actually like foresaw a lot of this. He had this concept of super critical learning instead of sub-critical learning, meaning we present learnings to machines or teach things to machines. They learn just the immediate thing that we just taught. But super critical means you also think through the second and third and fourth order effects of whatever you just learned, like to update the rest of everything else that you know. So like what are the creative ways in which we spend more compute, right? Like if we had 10x more compute or a thousand x more compute, where does it go?
Scaling Compute and Supercritical Learning
Greg [00:08:16]: I'll just say we will find ways to realize that. Please give us. But I mean it kind of seriously, right? The way that this works. Like if you rewind to something like Dota. We set out to develop new reinforcement learning algorithms because it was very clear to everyone that reinforcement learning, the algorithms that existed at the time, did not scale. Everyone knew it. And I remember Jacob and Shimon saying, why do we believe that? Has anyone actually tested it? And no one had actually really tried to scale up just plain old-fashioned PPO and say, well, that's the baseline. We got to do it. And I remember you come back to the office every week, they doubled the number of cores. It's only the agent. True skill was going up. It's up and to the right. And it's like, okay, you just got to keep pushing it until you hit the wall. And clearly we'll hit the wall and then we can go and do the actual interesting stuff. And we never hit the wall. And you realize that actually the journey of that scaling, that is the interesting stuff, right? Of really doing the engineering. And of course you have bugs and those bugs cause a wall, but you fix the bug, right? You have different issues with how your neural nets initialized or the scaling variance or whatever the issues are. But those are not the fundamentals of the algorithm of the science. And so I think that's kind of the world that we're in. Is one where it's like. We will push on every dimension and maybe we hit a wall. Most of the time, those walls are like just bugs and silly things. And so you can keep going. Sometimes the ROI for fixing those is really hard, right? So it's like, it's not really worth it because you have a different dimension, right? Do you want to push the model to be larger and do more pre-training compute, or do you want to do more RL? And so push more compute to the actual test time. And there's all sorts of dimensions that you can put compute into. And in some ways I think of compute as this, like, you know, we're doing this refining process. Ultimately start with energy. It turns into compute, turns into intelligence, and it's almost crystallizing that compute into the potential energy that can be converted into the model doing something useful. It's a really beautiful thing, right? It's like the compute as this like fundamental driver, this fundamental fuel of intelligence and sort of shapes a neural net, sort of outputs a program. And you know, of course the nice thing about that program is you can run it many, many times even though you put all this compute in that you actually have this amortization that you're going to use it far more times than the amount of effort you put into creating it once. And so it's just like a, it's a beautiful paradigm.
Alessio [00:10:27]: Yeah. You're kind of turning kinetic energy into potential energy in the model. And do you feel like the energy that it's already in this models, we can then turn back into kinetic to do our all in every other domain because we got the IMO gold. I mean, we in the, you, you guys, everybody, do you feel like those same techniques and the same base models can then get us to the goal? IMO gold equivalent. Yeah. I mean, if we just scale the compute or do you feel like there's still some work to do?
Greg [00:10:57]: Well, we have pretty good evidence on things like the IMO models actually also getting us a gold in IOI, which is just the same. Yeah. I mean, I think we did like, I think we talked about some of the details. There's a little bit of difference in the harness, but like the harness is not the gold literally. Right. It's like the actual underlying models and there's no training there that we did specifically. This ended up being just a side project of a few people are like, oh, we may as well do IOI. Right. And it's just a wild fact to me because that used to be something that would be a total grand challenge. You know, many, many people working on and I'm the core IMO team at OpenAI was actually three people. Right. Wasn't this massive effort. And so you realize that there's maybe some specialization required for some of these domains, right? Maybe some amount of additional work, some amount of go gather data set. But fundamentally we have this general purpose learning technology and that learning to solve hard problems is actually a very transferable skill. Learning how to solve hard math problems and write proofs turns out to actually transfer to writing program and competition problems. Now if you've never run a physics experiment, right, if you've never actually gone and tried to mix together some chemicals or something, you're probably not going to be magically good at those things. And so that there is something about the limitations of generalization, right, that you do need to actually have some real world experience and try it out. But these models, they go almost unreasonably far already. And we see this all the time. Where we have wet lab scientists. We have lab scientists who took models like O3, ask it for some hypotheses of here's an experimental setup. What should I do? They have five ideas. They tried these five ideas out, four of them don't work, but one of them does. And the kind of feedback we were getting on O3 was resulting work is something that could be published in a mid-tier journal, not the top tier journal, but a mid-tier journal. It'd be kind of the work you'd expect from some sort of third year, fourth year PhD student. And again, it's just a wild fact. That's where we are with O3. And we see exactly how to improve O3 on all dimensions. And it requires compute. It requires a lot of work. It requires getting the task. It requires a lot of human's intellectual love and labor and time and really pouring our heart and soul into it. But the result, to your point, it's like we produce the thing that has all this potential energy within it. And then the amazing thing is that you don't release that potential energy once, right? It's a checkpoint that you can use many, many times across all of these tasks. And that is something that I think really can uplift all of humanity. That's so inspiring.
Wall clock time limitations in RL and real-world interactions
Swyx [00:13:21]: I wanted to backtrack on two things. One about the wall. One thing I was trying to get into this debate with Noam on was I think there is a wall in terms of wall clock time because time has to pass. Like the problem with RL interacting with environments and simulation is sure you can speed up the simulations faster than real time. At some point you have to match wall clock time. So like, you know, you can see us converging towards like the pace of iterations towards wall clock time in terms of getting closer and closer to real time. And so I think that's a really interesting thing to think about. modeling the real world. I don't know if you have any thoughts on tackling that. Obviously, we're not there yet, so we don't have to worry about it.
Greg [00:13:57]: Yeah, I think this is a pretty fundamental barrier, right? And of course, the models have very non-human affordances, right? You can run many copies of them. And so you can scale out even if you can't decrease the latency. And it's also very interesting to think about where the compute goes, right? Because we're going to move from a world where most of the compute is training the model, as we've deployed these models more. You know, more of the compute goes to inferencing them and actually using them. But then if you think about, well, you're going to have these models that are going to be interacting with the real world a lot. And so they should probably think a lot about every single action, right? So you might end up with tons of compute spent per real world interaction. And so it really shifts around where you'd expect the compute to actually be expended. And I think that really having good harnesses that are very efficient, right? Do you think about things like, if I have been taking a bunch of steps in some rollout in the real world, how do I checkpoint that, right? And if you have a system that you need to restart it and it's going to forget all of its current state, like that's probably pretty bad. And so I think that there's just something very different about the digital world where everything can be perfectly observed and checkpointed and preserved, as opposed to reality that's much more messy and complicated. And I think it's not a bad thing, right? I think that we've seen agents with things like Dota that are able to operate in very complicated, very messy environments. So the algorithms are capable of it. And by the way, Dota was like a 300 million parameter neural net. Tiny, tiny little insect brain, right? Now we're starting to scale up to things that are much more comparable to human scale in terms of number parameters, maybe in terms of number of compute. We're not necessarily quite there. I think you could look at the math in different ways. But fundamentally, we are making progress towards the real goal. And if you think about what an AGI should be, it should be something that is capable of interacting with the real world in ways that are very productive. Yeah.
Swyx [00:15:51]: Back off the envelope. I think that the numbers I have in my head, you can correct me if I'm orders of magnitude off, but it's something like humans have 100 trillion neurons. We're in the multiple low double digit to high single digit range for GPT-4, 4.5, and 5, but we're not confirming that.
Greg [00:16:08]: But we're scaling there. Yeah. I'd say 100T synapses, which kind of corresponds to the weights of the neural net. Yeah. And so there's some sort of equivalence there. Yeah. And so we're starting to get to the right numbers. Let me just say that.
Swyx [00:16:20]: And then just on a biological basis, this is an opportunity I didn't even get to ask you last time on what you learned from ARC Institute. You had a sabbatical there. I'm curious if that informs anything that you do at OpenAI now.
Experience with ARC Institute and DNA neural networks
Greg [00:16:34]: Well, the thing I found most remarkable about working on DNA neural nets is that they're exactly the same. Yeah. Right? It's just you replace human language. It's even like a simpler vocab. It is. Yeah. Yeah. You've got four letters.
Swyx [00:16:47]: But don't you tokenize at a higher level? Yeah.
Greg [00:16:49]: I mean, so you can. But actually, the way that we approach it, we just did- Character level? Character level.
Swyx [00:16:54]: No way. Yeah. Why not? Well, I guess there's no reason. I don't know.
Greg [00:17:00]: There's only four. Right. Right. Right. And this to me is, I think, the core. Like, one of the interesting things about human language is we understand the semantics, right? We kind of understand what it means, what the structure is. It's very easy for us to observe. We kind of have a sense of when you look at a tokenization scheme, you have a sense of did you capture, like, all of the words in a reasonable way and all this stuff. Biology, it's an alien language. And the thing that's very interesting is that, you know, for humans, it's an alien language. But if you look at a neural net, why should human language be any more natural to a neural net than biological language? And the answer is they're not. Right? That actually these things are both- Literally the same hardware. Exactly. And so, one of the amazing hypotheses is that it's like, well, these neural networks are neural nets. They can learn human language just fine. And so, they ought to be able to learn biological language just fine. And we really see the same kinds of results. Right? It's like, I'd say that maybe the neural net we produced, you know, it's a 40B neural net trained on, you know, like 13 trillion base pairs or something like that. The results, to me, felt like GPT-1, maybe starting to be GPT-2 level. Right? It's like accessible and applicable to downstream tasks across a wide range of biological applications. Not yet adjustable. Not a GPT-3 or GPT-4, not a GPT-5 for sure. Right? We're not able to solve super hard problems in these domains just yet. But we've got compute. We've got the right techniques and algorithms. Now we need to scale. We need to think about long context. There's different ways that the biological systems stress the models relative to language sequences. Like language sequence of a billion tokens doesn't really exist, but it does in your DNA. Right? You've got like 4 billion base pairs or something like that. So, you know, you kind of have some sort of different emphasis. But fundamentally, it's the same problem you need to solve.
Swyx [00:18:49]: Is there an application that you're most excited about, like drug discovery or obviously I think everyone goes to drug discovery, but maybe some intermediate thing before that that is reachable and very impactful?
Greg [00:18:59]: Well, I mean, at a personal level. So my wife, we've talked about this, you know, I've talked about this publicly before, has a genetic condition called Ehlers-Danlos syndrome. It's something that until very recently, I think we're starting to see. You know, genetic markers for it, but it's been kind of unknown exactly what causes it, where it comes from. And that is something where if you have better tools for understanding biology, you should be able to identify the markers for lots of different diseases. And so that's just like one example of the kinds of applications, the promise that exists within these neural nets.
Defining the GPT-5 Era
Alessio [00:19:33]: How would you characterize the beginning of the GPT-5 era? If I think about 3, 4, 5 as the major versions, I think 3 is very text-based, kind of like, like RLHF really getting started, 4 is multi-modality and all these different low latency, long thinking with O3. What's going to be the 5 flagship thing? Obviously the year of agents, right? That's the meme. Yes. But is there something else that comes to mind that people should think about? Okay, with 5, now we unlock X. Yeah.
Greg [00:19:59]: I think it's smart. I think that the intelligence of these models is starting to be just almost undescribable, right? It's like, there's still limitations, there's still ways in which they fail. But it really is the case that for extremely hard domains, like look at the IMO results, right? So you can take a model that's been trained on this reasoning paradigm, and it's able to write proofs that is at the level of the best humans, right? And it's like, in this specific domain, there's limitations, et cetera, et cetera. We haven't proven like an unproven theorem, any of that stuff, but it's real. It's like, it's undeniable at this point that these models are able to perform great intellectual feats. And I think that's new, right? GPT-4, I think, was like much more, it was kind of capable and commercially useful across a wide range of applications. But the ideas that it produced were not very deep, right? The problems it would solve, it was not very reliable at. And I remember with GPT-3 actually trying to teach it how to do even basic stuff, right? That like, we kind of realized, hey, you could do this few-shot prompting, so you would kind of show it a few examples of something, and then it'll basically kind of do that task. And so I was like, okay, can you just teach this thing to sort a list? And I gave it like seven numbers to sort. It didn't sort it. I was like, okay. Then I tried to write a whole script of like, I'm a teacher teaching you how to sort numbers. Here's an example of sorting two numbers and then three numbers and whatever. And I'd be like, okay, now here's five numbers in total flop. If you ask GPT-5 that, and I've not even tried, by the way, asking GPT-5 to sort a list of five arbitrary numbers, but I am certain it will do a perfect job of it out of the box, no problem. By the way, it does have access to Python tool as well, so you don't have to do that. Are you going to say that?
Greg [00:21:40]: Well, I'm going to say that the thing that these models are capable of assisting humans in is something that we're just starting to see. We started to see it with O3, and you can see that professional mathematicians starting to kick the tires on GPT-5. We've seen physicists starting to kick the tires in GPT-5 and say that like, hey, this thing was able to get, this model was able to re-derive an insight that took me many months worth of research to produce. And that's the kind of thing where it's like, you realize this will speed you up. So fast, right? I remember doing my own math research back in high school and at the beginning of college, and I'd spend just like so long just trying to manipulate these objects in my head and think about connections between things. And if I had a partner that I could actually talk to about this, who would actually spend the time to deeply understand what I'm thinking about and produce new insights off of what I'm suggesting, that would have just sped me up so much. It would have been so much more fun, right? Because you don't just like kind of get caught in this loop of just sort of thinking about it off on your own and thinking, you're like, wait, I already thought this thought. You know, two weeks ago. And so I think that there's just something new about pushing forward the intellectual
Evaluating Model Intelligence and Task Difficulty
Alessio [00:22:46]: frontier together as a partner with GPT-5. Do you think people are limited by the difficulty of the problems that they work on? I think like, you know, for me in Cursor and in Codex, it feels clear that the model is better when I give it hard tasks. I feel like a lot of people put screenshots on X and it's like, oh, GPT-5 is not that much better. It's like, well, the question is not that hard. Yeah. You know? It's about confidence. When you call it the best coding model in the world, obviously you're one of the best coders in the world. So the game recognizes the game. But for people, how should they really think about evaluating these models?
Greg [00:23:21]: Yeah. So there definitely is a saturation on certain tasks, right? If you're just going to chit chat and say, hello, how are you, there's only so many things you can say. If you're going to say, here's the rematter hypothesis solution, please. Okay. Yeah. There's like a broad range of intelligence that will be desirable there. Yeah. And I think that's what we've observed is that we've seen GPT-5 be able to solve intellectual problems, you know, sort of tasks that require deep intelligence much better than any other model that we've tested. The second thing we did was we really spent a long time seeing how are people using it in interactive coding applications and just taking a ton of feedback and feeding that back into our training. And that was something we didn't try as hard in the past, right? For something like O3, we really trained it with tasks that we'd set up once and the model, we'd see it go up into the right on all of our metrics. It'd be great at code forces, you know, competitive programming competitions, which is, again, very exciting, but it's not reflective of how you actually program. You actually program in a much more messy way, right? That you have some sort of repo that has some sort of local state and that it has different abstractions and, you know, that just like different versions of different libraries. And that sort of diversity. Yeah. Isn't something that magically arises from a very structured, here's this one specific task, 10 specific tasks you need to accomplish. And so a lot of what we've been focusing on is saying not just how do we push the intelligence, although that is always going to be the core, but also how do we connect the intelligence to real world applications? And so that it really got to experience being pushed out of its comfort zone, out of its ivory tower, and actually be able to see the messy reality and diversity of the real world. Yeah.
Practical Advice for Developers Using GPT-5
Alessio [00:25:06]: What are suggestions on a more practical level that you have on getting the potential energy out of these models? So part of it is adding, you know, the linter, the type checker, the task to like have it self-loop. Any other meta that developers should think about? How do you use the models? Yeah.
Greg [00:25:21]: Well, the number one thing that I've observed is that there is a real skill in extracting the most from these models. And it requires this tenacity, right, of really trying to like almost understand the shape of the model skills and weaknesses. And so you test it, right? You test it with something small, you get a little feedback, you test a little bit higher, try to give it some bigger tasks, try to see if it can work in a certain way. And I think that people usually have their library of different prompts, right? So I definitely have my library of prompts that I've built up since, you know, the GPT-4 days. Like I remember in advance of GPT-4, starting to gather up a couple of like, okay, I wonder if I'll be able to do this. You know, you have some sort of, you know, query that, importantly, you want queries that could have a range of different answers that don't have any one. One specific right thing. And so for example, on creative writing, I've liked to ask for like a mashup of Lord of the Rings and startups, right? Just like try to push together two different topics and see what you get. In terms of actually testing the model and pushing it, I think that I do a lot of trying to think about, okay, like how do you, first of all, break up tasks and have something that's self-contained that you can let the model run with? Because you don't want to just have one instance of the model operating. You want to have multiple, right? You want to be a manager of not an agent, but of agents, right? And so that you need to, first of all, think about how your code base is structured, but then actually go and try to push the model to say, can you actually operate it on, you know, these multiple different pieces of your code base? I think that people love doing front-end five testing. GP5 is very good at front-end, it turns out, but of course that's not what most developers spend their time doing. And so it's important not to overfit to that, but I think that maybe just getting a feel for the model and kind of starting to become in tune with its strengths and weaknesses, and viewing it almost as a tool. Also, an extension of yourself and know, you know, like often, another thing I'll do is just be kicking off tasks to the model that are sort of not on the critical path, while I'm thinking about some super hard thing that the model, for whatever reason, I don't want it operating on. And so I'm just constantly getting information back on just like, okay, was it able to do a thing? Or just like low risk if it like makes a mistake, because I don't feel like I had to sit around waiting for five minutes and then, you know, sort of get no, no return.
Swyx [00:27:30]: You've always mentioned that I think that there, the roadmap for Codex and opening as coding capabilities. Since we're there, is that the background sort of SWE agents sort of merge with the NIDE agents. How's your thinking involved there? Like, is it just as simple as like the IDE can call the background APIs and the background APIs can sort of export to the IDE? Or what's a deeper connection in that?
Greg [00:27:50]: I tend to think about AI productization by analogy to a coworker. What do you want out of a coworker who's a great programmer? Right? You don't... Slack them. Yeah, exactly. So you want to slack them. But sometimes you're like, hey, I kind of need help with this thing. Can you come over and look over my shoulder? Hey, program. Right? And like, hey, can you take the keyboard? Exactly. So you want the pair form factor. You also want the remote async form factor. And you want it to be one entity that has knowledge and memory across all of this. You don't want it to be a junior programmer who shows up every day being like, okay, I forgot everything. Can you remind me how to SSH into the whatever? Right? So I think all of that has to happen. Right? That you need AIs that have access to your infrastructure in a trustworthy way. Right? A way that you can audit. Like, one thing that is different about these models is that they're fine being micromanaged. Turns out humans don't like that very much. Right? If you look at every single command that they're running and you, like, demand, like, reports on everything they did, probably you're not going to retain that person. But the models are perfectly happy to. Right? And so that's an affordance that's, like, well worth thinking about and changing the interfaces to take maximum advantage of. At the same time, yeah, you really want the seamless blending between a model that's able... Yeah. ...to do a bunch of work on its remote machine, doesn't mess up my local state, fully sandboxed, fully observable, and then sometimes can be like, okay, I'm ready to run something locally. And that depending on what that is and depending on how sandboxable it is, that you can do one-off approvals, you could give it full delegated access. And I think that having the human be in control of this observability and to be managing this team, an agent that has just different surfaces. Right? It doesn't... Like, the identity of the agent being something that runs locally versus the identity being something that runs remotely. To me, that's the wrong question. It's really the agent should be this, like, model that's executing and then requesting to run things in a remote sandbox or locally or maybe multiple sandboxes. Or maybe it's running on your computer and my computer.
Swyx [00:29:53]: Like, there's no reason that it has to be local to any of these things. Software agents, you can just sort of seamlessly and fluidly move around. You mentioning approvals gives me a chance to spotlight my friend Fuad, who is helping this team. Sorry, the agent robustness team that was also launched at AI Engineer. What's that? What's opening his interest in that?
Greg [00:30:11]: The way we think about agent robustness is through defense in depth. There's a layer of the model itself. We publish techniques like instruction hierarchy. And so with instruction hierarchy, you sort of indicate that, hey, there's this message is from the system. This message is from the developer. This message is from the user and that they should be trusted in that order. And so that way, the model can know something that says ignore. Ignore previous instructions from a user. I'm not going to follow that. Yeah, right. And so I think that having like, it's almost like thinking about how we prevent SQL injections, right? Having systems at a low level that are robust against these attempted exploits is very important, but that's not where you stop, right? You want multiple layers of thinking about the system controls, right? If a model is sandboxed and isn't actually able to execute something or access a specific piece of data, then you have full guarantees around what's possible. And there's, you know, various levels in between of approach that we take. And so I think that a lot of what is the frontier as these agents get become more embedded in our lives and are trusted with more responsibility is also increasing the safety and security of them in lockstep.
Swyx [00:31:19]: There's an analogy that I made to like the Linux kernel OS rings as well. And it's really interesting that we're basically kind of building this in to the LLM as like concepts of sort of different layers of security. And also the other thing I also was. Very happy to see was that I invited a talk on the model spec for AI engineer, and that was the most viewed talk of all of that we've ever had, which, which is like, it's very, it's hard to make safety and reliability sexy.
Model Specs
Greg [00:31:48]: I think the model spec is a perfect example of when the models are very capable, you start to really care about what they're going to do. That becomes the most important question. And the model spec is an example where we've made it very legible. To the outside world, what our intention is for this model to do, and it doesn't mean that we always produce a model that is capable of following that, but it's a north star, right? It's something that really sets. This is the intention and anything that deviates from that is not through our explicit effort. It's anti to our explicit effort. And I think that the gap between the spec and the actual behavior is shrinking very, very constantly. The thing that's very interesting is almost like values, right? It's really thinking deeply about, well, what should a model do if you ask it a controversial question? Right? If you say, I think that the world is flat or whatever, like, is it supposed to say, yes, it's flat? Or you're supposed to be like, well, like, here's what science says. And honestly, these things are subtle, right? That it's not really clear what the right thing is just on, you know, two minutes of thinking about it. But if you read the spec, you can actually really see the thoughtfulness that has gone into it. And it's not the final answer, right? It's something we want feedback on. It's something that we want to produce collectively as a community.
Alessio [00:32:55]: I know we want to talk about open source next too, but I had a more esoteric question. I was listening to your old Lex Friedman interview. And you kind of mentioned, um, back in the day, back in the day, foundation, but Asimov, it made me think about, we have Brett Taylor on the podcast and we talked about how certain languages have inherent capabilities, like rust is memory safe. And so that just happens. Do you see almost like a cycle history of LLMs of, and software engineer where it's like, Hey, these models, I can predict the way software is going to look like everything is going to be blue and purple gradients, right? We're kind of seeing that today. What else are these models really driving us to work? And is there a way that we can change that?
... [Content truncated due to size limits]