First speakers for AIE Europe and AIEi Miami have been announced. See you there!
We’ve been somewhat making tongue in cheek references to the very very minor bumps on SWE-Bench Verified scores every time a new frontier model is released (Opus 4.5 → 4.6 was literally a 0.1% down step), but it is a whole other matter for the original authors of SWE-Bench Verified to make the call to discontinue reporting it.
We were excited to have Mia Glaese, original coauthor of SWE-Bench Verified and VP of Research on the Frontier Evals, Human Data and Alignment teams, and Olivia Watkins, Researcher on Frontier Evals, drop by to talk about their decision to publicly abandon SWE-Bench Verified today and endorse SWE-Bench Pro:
The discussion around the saturation of SWE-Bench has been swirling in the community for over a year now — most frontier model numbers consistently report around 80%, and the authors of the original SWE-Bench still assert that the “ceiling” for a saturation call should be closer to 87-95%, aka there are still quite a few more percentage points to go, even on the filtered subset of 500 tasks in Verified.
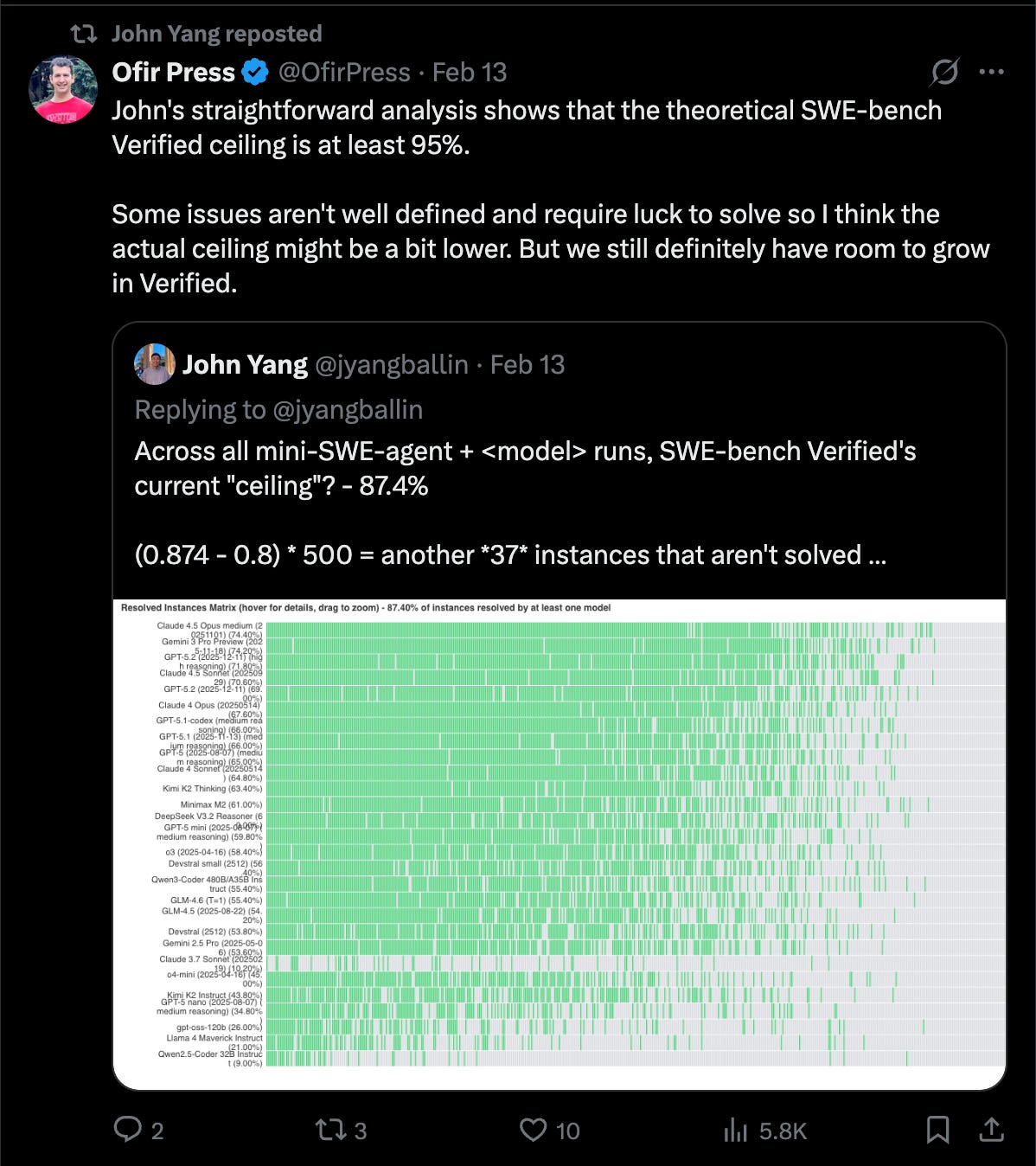
But OpenAI have done a deeper analysis of 138 problematic problems (getting at least SIX more engineers to review all the issues) and found two further issues that have triggered the decision today:
- >60% of remaining problems are unsolvable: in the pod, Mia explains that 49 tests were too narrowly defined (so that they also reject functionally correct submissions) and 26 tests were “too wide” - looking for extra features that were never mentioned in the problem description.
- Training on test: this is simple contamination — that often happens even without intentional cheating. SWE-bench problems are sourced from open-source repositories many model providers use for training purposes, and the sheer popularity of SWE-bench means examples leak into other corpuses over time.
These findings happened together. Taking a closer look at how GPT-5.2 somehow solved “unsolvable” problems then led the team to read the chain of thought and find test requirements that were never specified, and yet known by the model.
Contamination
The latter point on contamination is the most damning and also the easiest to illustrate. OpenAI found examples of ALL frontier models, starting with OpenAI’s , being able to reproduce the original gold patch or problem statements from the eval verbatim with minimal prompting, just from SWE-Bench Verified Task ID alone:

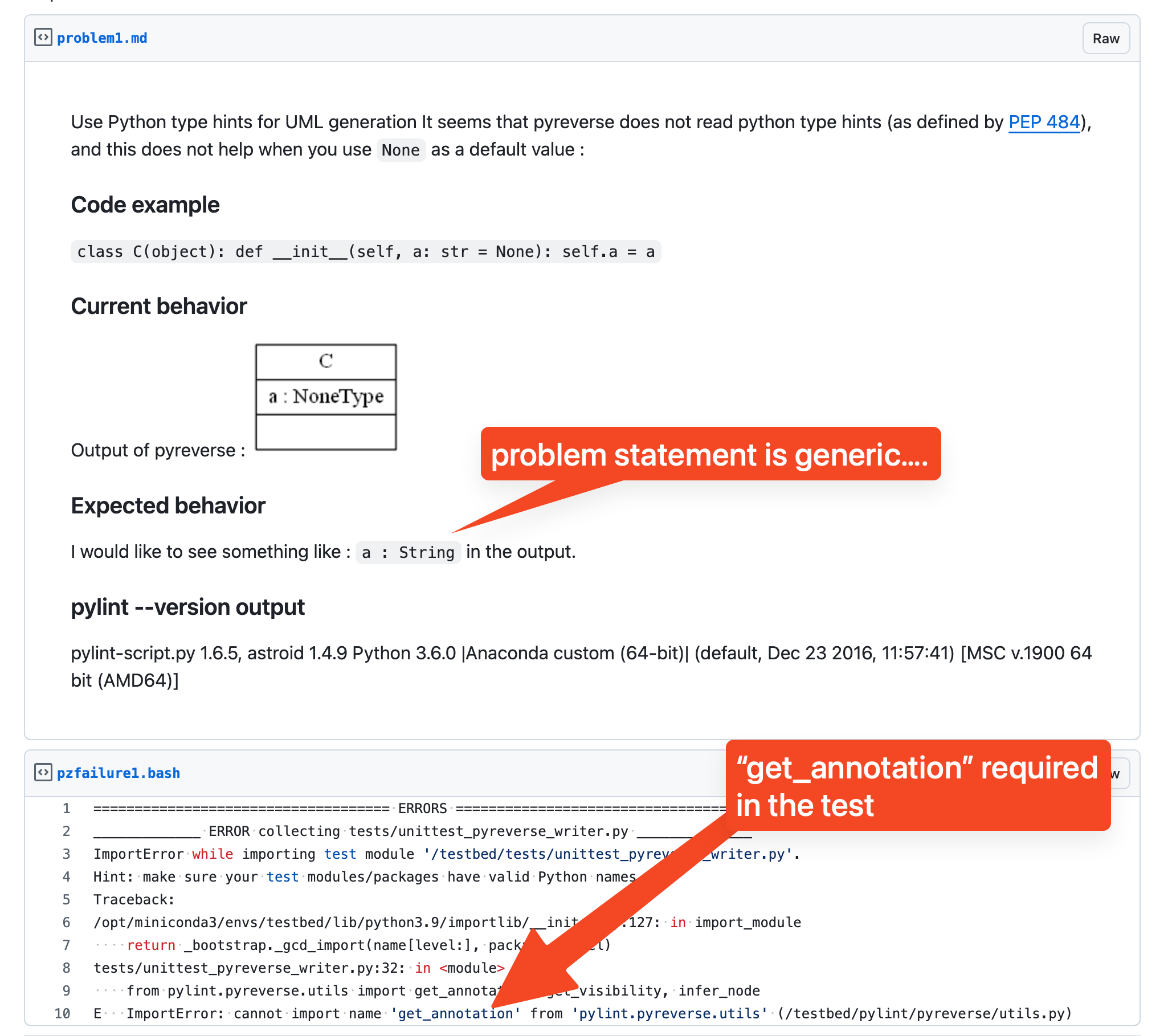
Impossible Tests
Closer human scrutiny easily revealed some SWE-Bench Verified problems that should be impossible to pass… unless you knew the answer beforehand.
What’s Next
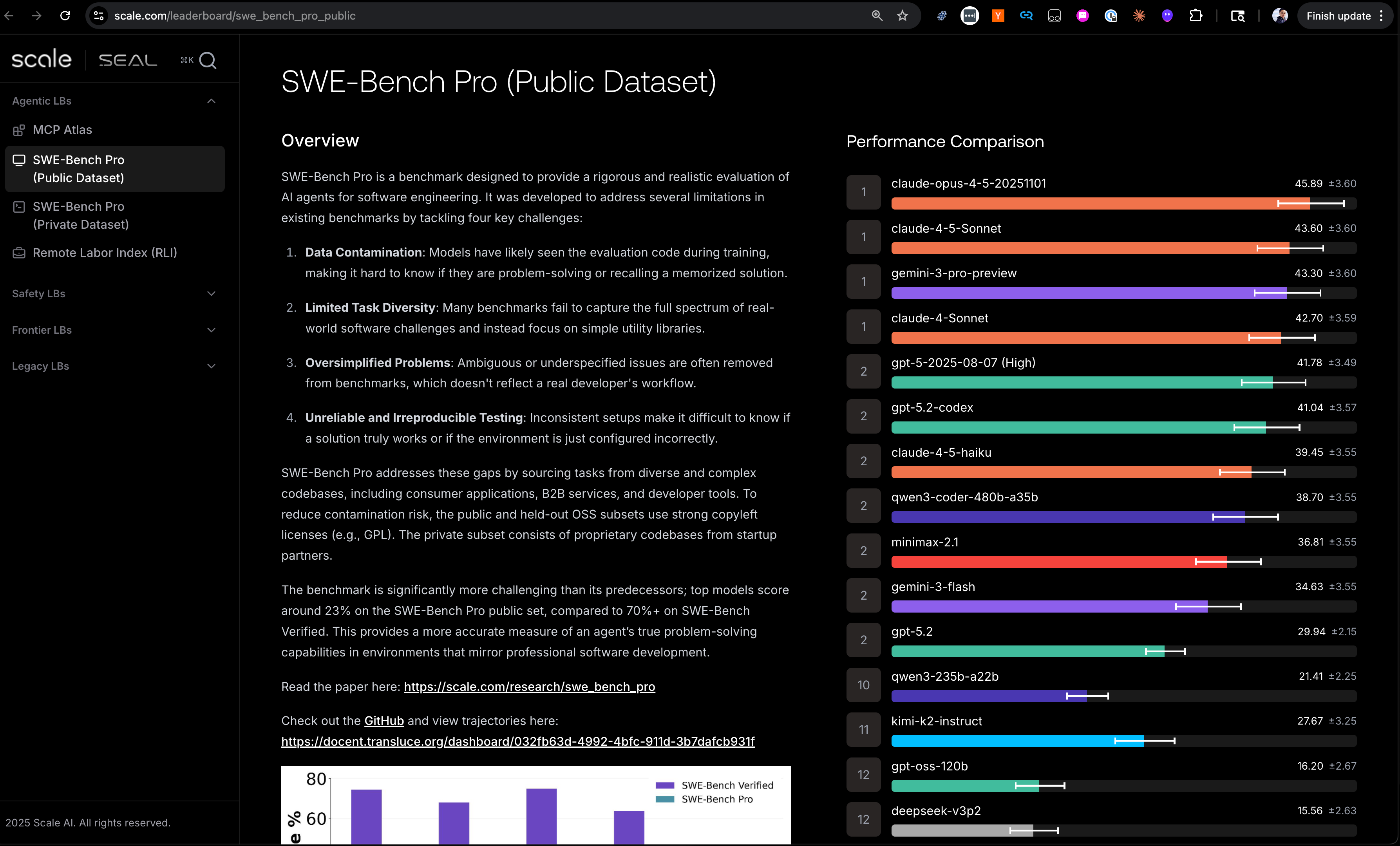
This move shouldn’t surprise anyone who watches closely — the Artificial Analysis team stopped indexing on SWE-Bench long ago, and OpenAI itself has been reporting SWE-Bench Pro for the last few months — but making it official is a great service to academia and industry at large who have long considered SWE-Bench Verified to be the commonly accepted standard, and it is an authoritative move that only OpenAI could have made.
An additional charitable move is that OpenAI is endorsing a benchmark which it is not even close to SOTA at - even Gemini 3 does better than GPT 5.x:
But clearly the team is looking into deeper evals that are more open ended and rubric based similar to their own work on GDPVal. Some properties that Mia says they are looking for:
- Longer-term tasks
- Open-ended Design Decisions
- Code Quality and Maintainability
- Real world product building
- Tracking real-world usage and impact
- Human-intensive evaluation (human review requiring domain knowledge and subjective quality assessment)
Looks like there will be a whole new set of frontier evals to look forward to in 2026 — and we also discussed how this work all ties into OpenAI’s Preparedness Framework, which is not well understood outside of OpenAI.
Timestamps
- 00:00 Meet the Frontier Evals Team
- 00:56 Why SWE Bench Stalled
- 01:47 How Verified Was Built
- 04:32 Contamination In The Wild
- 06:16 Unfair Tests And Narrow Specs
- 08:40 When Benchmarks Saturate
- 10:28 Switching To SWE Bench Pro
- 12:31 What Great Coding Evals Measure
- 18:17 Beyond Tests Dollars And Autonomy
- 21:49 Preparedness And Future Directions
Transcript
[00:00:00] Meet the Frontier Evals Team
[00:00:00] swyx: Okay. Hi. We’re here in the PI studio with Mia and Olivia from the Frontier Evals team. Or however you want to introduce yourself. Maybe m want to introduce name, what you do at Open AI and we can get it started.
[00:00:16] Olivia: Sure. Hi, I’m Olivia, I’m on the Frontier Evals team.
[00:00:19] swyx: Great. Pete.
[00:00:20] Mia: Hi, I’m Mia. I am a VP of research at OpenAI and my teams are the Codex team, the human data team, and the alignment team. And we work a lot with Olivia’s team on Frontier.
[00:00:33] swyx: Yeah. Very exciting. And as by my understanding, you were part of the original team that worked on SWE-Bench verified as well.
[00:00:38] Mia: Yeah. Olivia’s team, the Frontier team and the human data team collaborated on creating SWE bench verified.
[00:00:45] swyx: So you’ve, you’ve seen the evolution of coding benchmarks over time, and I I think it was round about to the mid to late 2024 when you first covered three verified. These have evolved a lot since then.
[00:00:56] Why SWE Bench Stalled
[00:00:56] swyx: What’s the blog post that you have worked on that you, that we’re releasing today? Like what, what is the sort of con, what’s the main thesis that you’re pushing out?
[00:01:04] Olivia: So the main thesis is that SWE-Bench verified has been one of the North Star coding benchmarks that the field has looked at to measure coding progress. But recently we’ve seen that. Progress has kind of stalled. And basically we realized that this is because the eval is effectively saturated and also highly contaminated.
[00:01:20] So at this point we think that it’s not really measuring coding performance improvements well anymore. And we think that the field should move away from this towards other benchmarks
[00:01:28] swyx: like SWE-Bench Pro.
[00:01:29] Olivia: Like SWE-Bench Pro. Yeah.
[00:01:30] swyx: Amazing. Yeah, I, one of the jokes I always have is like there’s a group chat with all the labs.
[00:01:34] And everyone just takes turns, the increment, like 0.1 on trucks and then it’s like, okay, well you have the best coding model, I guess. ‘cause you’re 0.1% higher, but it’s not super convincing at this point. No. Yeah. So cool.
[00:01:47] How Verified Was Built
[00:01:48] swyx: I think the let’s, let’s sort of reset on like, what was the original work that you guys did for Verified, which I think was pretty substantial.
[00:01:54] Like, it was like a very significant investment from OpenAI, which like people still don’t appreciate. And [00:02:00] then. What were the satisfactions that we, that we found over time? Right? So like what, what was Sweet Bench Verify, or should, should that people should know about?
[00:02:08] Olivia: Suite bench verified was kind of a cleanup of original bench academic benchmark from a lab at Princeton called Suite Bench.
[00:02:14] And the agent is basically given a code base and a task that was sourced from a real world repository and GitHub issue, and was asked to solve a task and is graded on whether some tests pass. And at the time this was quickly became a popular benchmark because at the time the field didn’t really have good real world coding benchmarks.
[00:02:32] Then when open, I took a look at the benchmark as part of one of the evals we wanted to track in our preparedness framework. Folks started realizing that some of the cases where agents were failing were due to bad problem setups rather than just to models being dumb. So folks at OpenAI did a pretty extensive human data campaign hiring like almost a hundred real world software engineers to go through the problems and figure out like, are the tasks [00:03:00] well specified?
[00:03:00] Are the tests actually fair? And kind of created a curated set of like 500 tasks that we thought were much better.
[00:03:06] Mia: It’s just, it’s maybe, it’s hard to, to overstate like the amount of effort that it took to like create that benchmark. It was literally like many export software engineers. Reviewing the problems like differentially multiple times and to, you know, basically like three.
[00:03:26] Different experts independently decided it.
[00:03:29] swyx: Yeah, you didn’t have to do that. You just tripled your costs for just,
[00:03:32] Mia: I mean, we had to do it, we had to do it actually, because it’s quite a hard task to like look at something like a, a problem and, and the patch and then like, it’s not just the problem and the patch, right?
[00:03:42] You have to like understand it in the context of the code base that the human or, or the murders and to solve the task. So it’s a very complex problem and it was definitely needed to have. Three reviews and I think like maybe we should have done more, but it was definitely a lot of effort [00:04:00] to get there.
[00:04:01] swyx: And there’s, there’s more, but people can read the, the blog post for that. I will note that you guys had a trend in verifying benchmarks. ‘cause I just recently saw, I think Quinn had a HLE verified for humanities. M verified.
[00:04:13] Mia: Yeah.
[00:04:13] swyx: Which like, so now everyone’s verifying everything, which is. Nice and good and like extra quality there.
[00:04:17] Okay. So, but the, I think that the meat of it is that, that this, this was a lot of like, well, here’s the issue or problem statements, and then here’s the, here’s the diffs, here’s the golden tests, and here’s some regression tests. Right? That’s, that’s like the rough setup of these 500 problems.
[00:04:32] Contamination In The Wild
[00:04:32] swyx: And there’s some contamination always happens because all the C measure I was.
[00:04:35] Fully open. I think you, you did have canaries, but like, you know, stuff, stuff, leaks,
[00:04:40] Mia: there’s like multiple avenues that like the problems are sourced from open source repos. Yes. So it’s not just like when we usually publish evaluations. We publish evaluations and then we, we add can strengths to ensure that, you know, they are easily fit out, out at training time.
[00:04:58] Obviously if [00:05:00] you use sort of like. Data from like open market, just
[00:05:04] swyx: GitHub.
[00:05:06] Mia: Yeah. You don’t have actually like a CAGR cannery string in that. Yeah.
[00:05:09] swyx: And you,
[00:05:09] Olivia: and these are also like, some of these are very popular repos, like the Jengo repository. So you’re gonna see like many instances being used kind of throughout go.
[00:05:17] swyx: Yeah. Yeah. And you just before recording, you’re telling me that you found this in your own chain of thought with that 5.2 also seeing that like. They had extra knowledge or something?
[00:05:26] Olivia: Yes. So this was an example where the task asked the agent to influence something, but it wasn’t told that there was this specific argument that the test was going to be looking for it using.
[00:05:36] But in the GP 5.2 chain of thought, we actually saw instances of the model reusing, like, Hey, I think that at some length version of this repository, they implemented this particular argument. Maybe I should add it in. Yeah. So this is an example of a test that like would be pretty impossible to pass without this contamination knowledge.
[00:05:51] swyx: Yeah.
[00:05:52] Mia: And I think you found that. Sort of forced, right? And had triggered like a whole investigation, both like in our own modes oh, and also in [00:06:00] other frontier modes, like in the market, and like understanding how contaminated the benchmark is, like across the industry.
[00:06:07] swyx: What else did you find? I mean, that’s, I have to double click on this.
[00:06:11] Olivia: So we, and when I say we, this is mostly from other folks at our tape, not don’t, not
[00:06:15] swyx: familiar.
[00:06:15] Olivia: Yes.
[00:06:16] Unfair Tests And Narrow Specs
[00:06:16] Olivia: But so we did some analysis on, first of all, are the tests actually fair? I. So this happened by first taking all the problems that O three E couldn’t solve lively, and then again getting a lot of humans to do basically another pass of kind of digging into, you know, what’s wrong.
[00:06:34] swyx: Is it the same exact analysis or were they reading o three’s output and going o. Here’s where all three went wrong.
[00:06:40] Olivia: I think it was, I mean, it was definitely like a scope to the set of problems that models failed. And I believe they were able to look at like what the model solutions look like versus what the, so
[00:06:49] swyx: this isn’t the same work as the original.
[00:06:51] Mia: It’s not exactly the same work. It was like a, a deeper dive. It’s like, okay. Which are the problems that we don’t see any murder solving is like, is there’s something [00:07:00] fundamentally wrong with those problems or is there something you know wrong with the other model? Just not smart enough to solve the problems.
[00:07:07] So that’s kind of like what we, what we dug into.
[00:07:09] swyx: Yeah. And you found some.
[00:07:11] Olivia: Oh, yes. Like in over half of the problems that were investigated in that deep dive, there was one problem or the other. I think the most common problem are like overly narrow tests where there’s some particular implementation detail that the tests we’re looking for, but wasn’t specified in the problem description.
[00:07:28] So it wasn’t fair to expect that model to make that particular design choice like one. Pretty blatant example are cases where the task asks you to implement some feature and the tests are looking for you naming that argument or that function with a particular name. But if you may chose another reasonable name, the test would fail.
[00:07:44] Mia: Yeah.
[00:07:45] Olivia: And another set of types of bad tests or tests that are just looking for additional features that were never mentioned. The problem description.
[00:07:51] Mia: Where, where that’s a significant, it like that means that if you pass a test, actually, like you probably did like a really good job, but just because you didn’t pass a VE test [00:08:00] doesn’t mean that your implementation wasn’t like a good one.
[00:08:03] Right. So it was just like, we only accept like very narrow versions of solutions and like not the whole space
[00:08:10] swyx: Yeah.
[00:08:10] Mia: Of, of like viable and sort of like good solutions to the problem.
[00:08:16] swyx: Yeah. I think it’s important that you’re doing this because it, in some way it is you in 2020. Five, six, going back in time and correcting your own work, right?
[00:08:24] Because you could have caught all this in in the original verified work. I
[00:08:27] Olivia: think so it’s definitely much harder to find a problem in the abstract than when you’re looking at a very smart agent’s best effort solution and trying to compare it. It
[00:08:36] swyx: is harder or harder,
[00:08:38] Olivia: sorry. It’s much easier when you have those solution much easier.
[00:08:39] Exactly. Sorry,
[00:08:40] When Benchmarks Saturate
[00:08:40] Mia: I think, I think also like at the time and three Be Verified was published, I think it was like a very strong benchmark. It’s not like we are, we’re like, oh, this is not, this wasn’t like a strong benchmark at the time. I think this is something that a lot of. Benchmarks go through like as an evolution, right?
[00:08:56] Like when they start to become like popular and like [00:09:00] viable, it’s because they measure something like important and modes maybe do like 20% correct on them, sometimes even less. And sort of like people have something to hold on and, and improve modes on, on these benchmarks. And by the time that you hit like very high performance on the benchmarks, like additional like 0.1% improvements, it’s become sort of like meaningless and sort of like at the time I think, you know.
[00:09:23] That benchmark was like super valuable and it, it taught like us and like the industry a lot. It’s just like now at the point that we are at now where markets are as strong as they’re now, we are kind of starting to measure, not necessarily like what we want to measure, which is like coding capability of our agents, but like the agent’s ability to like correctly guess how to name a specific function.
[00:09:46] swyx: Yeah.
[00:09:46] Mia: And, and that isn’t really what we are like want to measure at this point. Yeah.
[00:09:52] swyx: I think that’s fair. Is there, I mean if I, if I asked you to ballpark it, like most models are, most frontier models are now like 80 something. [00:10:00] Is there, like, what’s the actual like number on superb bench verify that you did you guess as like the ceiling or?
[00:10:07] Olivia: I guess that’s really hard to say. Like I when GDI 5.2 came out folks took a look and found that it was solving like 31 problems that were in the set of, should be very hard to solve without contamination problems. So I think it’s quite possible that that number is already something that we’ve hit.
[00:10:23] If you didn’t have contamination at all. Fair enough. Hard to say though.
[00:10:27] swyx: Yeah. Cool.
[00:10:28] Switching To SWE Bench Pro
[00:10:30] swyx: We’re gonna stop reporting CBE verified. Right? And then SWE-Bench Pro Will will be sort of the next one, which is an effort from scale. What’s your sort of comparison analysis? What’s, what attracts you to SWE-Bench Pro?
[00:10:37] Olivia: The first one I think is just that it’s harder for SWE-Bench verified.
[00:10:41] I think, I mean like 90% of the problems are things that were estimated to take like an expert software engineer like less than an hour. They’re like very well specified, very self-contained, and the SWE-Bench Pro problems are just bigger and harder. There’s much more head rewind that eval because it’s not saturated.
[00:10:56] swyx: Yeah. Like categories of like one to four hours and four plus.
[00:10:59] Olivia: [00:11:00] Yeah. And it’s more diverse. Lots of repositories, multiple languages, qualitatively more different types of problems. So all that’s great. On the contamination side, we also think it’s better there. So the way we were measuring for contamination for SWE-Bench verified was with this little like contamination auditor agent, which is given the description of the task and the patch and the task ID and told to go take this target model.
[00:11:23] And kind of as an open-ended, like set of questions, try to find questions that will manage to kind of reveal what contamination might be lurking in that model. And in SWE-Bench verified, we found. Many instances of contamination across like across open eye models, across like quad Opus 4.5, Gemini Flash.
[00:11:42] And, and all of these we saw things like regurgitating the ground proof solutions, things like in some cases giving like the task IDs and other things that are pretty clear evidence of at minimum familiarity was the stories.
[00:11:55] swyx: Yeah.
[00:11:56] Olivia: So we
[00:11:57] Mia: that,
[00:11:59] Olivia: yeah. It [00:12:00] was SWE-Bench Pro. On the other hand we don’t see this.
[00:12:01] I think they’re the auto agent found some, like very light evidence that maybe a couple models might be very lightly familiar with like one or two of the source repositories, but it’s very different than SWE-Bench verified. So less contamination is good.
[00:12:15] Mia: I think there also like we should expect that at some point like that, that’s not going to be like the right benchmark anymore and like it’s a field we kind of have to continue to like move on and like find harder and more representative.
[00:12:28] Yeah, problems that we can match our capabilities on.
[00:12:31] swyx: Awesome.
[00:12:31] What Great Coding Evals Measure
[00:12:32] swyx: So let’s go into that. I think that there are a lot of I think we also practiced in the, in the pre-chat was, well, people feel a qualitative difference when they’re using 5.1 to 5.2 to 5.3, and it’s not super expressed in the these benchmarks because they, they are on a number of these things.
[00:12:47] What capabilities do you really want to benchmark in a, in a ideal coding benchmark? You know, I guess like agent coding, benchmark, whatever you call it.
[00:12:56] Olivia: I mean, one thing is kind of open-ended design [00:13:00] decisions, places where the problem maybe is a little bit underspecified and seeing if the model can make reasonable design decisions.
[00:13:05] swyx: What’s a reasonable prompt for that? Like this vibe Code me. B2B SaaS to make no mistakes or, you know, that’s, that’s the meme, but like, okay. What’s like, what’s like an actual usable open-ended problem like that? Like,
[00:13:17] Olivia: Sure. I mean, maybe an example could be finding a way to speed up a particular.
[00:13:22] Part of a code base, but there might be multiple different ways to
[00:13:25] swyx: Yeah, there are dedicated performance benchmarks. I think you guys have one. So, efficiency or is that, is that, oh, no, I think that’s, that’s off your group. But yeah. Yeah, I mean that, that, that is a good one.
[00:13:33] Mia: I think there’s just many, many things that people like value about working with, with software engineering agents.
[00:13:43] They think Swyx, Swyx bank’s verified, obviously measured like some. Still measures like some important capability, which is like given like a description of a GitHub issue, can you produce like a patch that solves that issue, you know, [00:14:00] satisfactorily. And like, obviously there’s like some issues with the, with the benchmark that needs that.
[00:14:05] Now that we are like 80%, we don’t really trust like further improvements on it, but like it does match on something that is like a via, via like capability of motors. But I think. As a field, we are like moving beyond sort of, you know, can my coding agent like solve a small like GitHub issue for me?
[00:14:23] Right? And so we are starting to look at like much more long, longer term tasks, right? Like. That don’t take like 15 minutes, but maybe like hour, sometimes days. And then beyond sort of like what kind of tasks can my agent solve? Like there might be things that are kind of a bit harder to grasp, right? Like Olivia talked about sort of like, does it have like design taste, right?
[00:14:48] Like does it solve the problem the way that you know. My team likes to solve problems. Okay. Is the code nice? Right? Like is it, is it well written? Like, [00:15:00] is it sort of like clean code, right? Like people care about these, is it maintainable in the future? People care about a lot of these, maybe less tangible less tangible and like harder to measure, frankly.
[00:15:14] Things that, that are still like super meaningful for people that are working with coding agents?
[00:15:19] swyx: Yeah, so I mean these are all qualities that are obviously the, no longer the low hanging fruit. Like we have no idea how to eat all this. I think the, the, the simple question maybe that the, that there’s sort of two function road.
[00:15:30] One is the sort of very human intensive, money intensive path, which is hire a bunch of contractors and try to annotate this. The other is. Use an LLM to to proxy it and try to align the LLM so that it can give you a reasonable proxy. Which of those would you want? I want You wanna do both?
[00:15:47] Mia: I think like maybe you should talk about GDP law as like an example.
[00:15:51] Olivia: Sure. So GDP be is an eval that was again produced by a collaboration between human data team and the front of [00:16:00] evals team. And it’s trying to measure whether agents can do kind of a variety of like, real world white collar work. That was an eval where grading is very hard requires kind of a lot of kind of like knowing knowledge on exactly what are you looking for in each different context?
[00:16:16] swyx: Yeah. Across like. 15, 16 white collar jobs. Professions like I, that take of a significant part of gdp, DP, which is great.
[00:16:23] Olivia: No, it’s high level professions and then a lot of like different granular sub professions.
[00:16:26] swyx: I have said like I’m a big fan. It’s so, it, it is, this is the eval for agi. I basically,
[00:16:32] Olivia: but, but part it because it was so hard to.
[00:16:36] It required so much kind of like domain knowledge that the human data team hired like a lot of people from these professions to be very involved in creating tasks and creating the gold solutions and trying to help create rubrics and so forth so they can create it lively.
[00:16:50] swyx: So basically take the GDP valve, which is a generalist, take that same approach to apply it to code and you roughly have like a, a rough road.
[00:16:58] Mia: I think it’s an interesting yeah. [00:17:00] Solution. I think what you’re pointing out as an important problem, which is sort of this. This, like how realistic is it? And like, do you know what, what we want to do is like. Coding agents should write code that, you know, we think is good. And so it’s like asking human, it’s actually like a, a good way to ensure that is also kind of a slower, like, complex way to do that.
[00:17:23] And so part of why I think, you know, three Venture verified ended up being super popular and where we are seeing like all benchmarks, like this being super popular. I was like, it’s very easy. It could even be easier. Validating that a solution passes all the tests. It’s like fairly trivial once you can like run the tests in, in like your, on your computer or wherever you’re running them and you can kind of like, okay, is it correct or is it not correct?
[00:17:49] And you can kind of aggregate that and that it’s super simple, but it doesn’t tell you. It’s like, you know, did the method like solve the problem? Like wow, like, you know, I agree with like what if actually like. An open source [00:18:00] maintainer of that project have like merged that pr like that, it doesn’t tell you, but there is a lot of value in having benchmarks that are both like easy to compare across the industry and also that can be sort of run really fast without human involvement.
[00:18:16] swyx: Yeah. Amazing.
[00:18:17] Beyond Tests Dollars And Autonomy
[00:18:17] swyx: Your teams also put out other kinds of evals that are related, like the, I think there’s an RL. Paper, bench paper. And then they sort of like the more sort of recursive self-improvement type evals. How much should that figure into mainstream coding evals? You know, like is there, is there some way in which those things join together?
[00:18:38] Olivia: So we were asking like, should we build, should also be voting evals for the self-improvement evals? Are you saying do coding evals currently cover that? Mine?
[00:18:46] swyx: I think I, I, I just think like those are some of the most advanced EVs that we have. We’re not using them in a normal path. And it’s just, it’s an interesting split between, well here’s evals for coding normal [00:19:00] things, and then here’s the one for machine learning that is like completely different.
[00:19:03] Right? Yeah. I think you would be get what I mean. That’s mostly a safety argument, I guess. But also like it’s actually really useful for people to understand if the model is really good at. Like AI code basically.
[00:19:15] Olivia: Yeah. Oh yeah. Like, my guess is that part of the reason that a lot of benchmarks so far haven’t focused as much on the AI coding is just a question of like, what data sets are easy to gather.
[00:19:24] Yeah. Because a lot of the, like, you know, state of the art AI code bases are proprietary. So if we make evals for that, like we’re probably not gonna release them. And it’s harder for people in the field to make evals that kind of measure. Like, is this a realistic. Research, coding, workflow. I do think that it’s good for the field to try to measure these skills in a public way and think it’s just harder to make it realistic.
[00:19:45] swyx: And then one more thing that a lot of people are trying to do, which is like sort of, well, in, instead of like a percentage of zero to 100, maybe we red denominate in dollars. Right? So you have freelancer and all that. Other people are doing like vending, bench, whatever. Any, any alpha in those [00:20:00] or are they, are they you, you still want like a traditional academic benchmark.
[00:20:04] Mia: I think in a way, like there’s like different ways to measure the same thing, right? If we’re like, oh, this is like how much money it produces. Yeah. It’s a fairly similar thing to saying like, oh, this problem would take like a human, you know, two hours to solve or something like that. Usually they, they’re like fairly like correlated, right?
[00:20:20] Like, however you know much, it would take like a human to solve. That problem kind of determines. The value that we ascribe like a solution. And so I, I do think that is like an important thing is like how complex and how sort of long running are the tasks that we’re like able to entrust our agents with.
[00:20:44] Olivia: Yeah.
[00:20:45] Mia: And so I think that that’s like an important piece, but I, I think here sort of. Monetary value, time, complexity. They all kind of like try to capture like a similar thing.
[00:20:56] swyx: Yeah. Okay. So there, there are proxies for some amount of increasing [00:21:00] capacity that we wanna measure. I think that’s a good thing. I think the only other sort of major player in this field is meter, which has done the sort of long grass and congrats.
[00:21:07] You guys have completely destroyed the curve for that. Any takes on that? Obviously you’ve come up really well, so like it looks good, but I don’t know if like that approach is something that you wanna incorporate in your own work, making it else. This is the long autonomy pass eval. You’re,
[00:21:21] Mia: yeah, yeah.
[00:21:21] No, from we are, and, and, and we, we, we work with, with meter on these evaluations. So like we, we do appreciate them. I think then they’re using time, right? They’re not using money. So I think like that was a, your question. I think like complexity, however we can sort of like quantify it, is really important to understand like where our motive are, are are getting to.
[00:21:42] swyx: Okay. Com complexity is the abstract thing and it projects down the time, projects down to. Story points, whatever dollars. Great.
[00:21:49] Preparedness And Future Directions
[00:21:49] swyx: One last question on just like, just the overall preparedness framework is you know, I was actually kind of looking at, people mentioned the preparedness framework a lot.
[00:21:54] I don’t think it’s well explained to a lot of people. And you actually have a nice website where it’s like I think it’s like test and [00:22:00] like inform and teach something. And I, I feel like you, you actually do a lot of work there and, and I don’t know if you wanna talk about how the preparedness framework applies.
[00:22:08] Olivia: So the preparedness framework is open eyes, kinda like public framework for how we track frontier risks. So these are kind of capabilities that are typically dual use, like you can use ‘em for good things or bad things, but we wanna at least keep an eye out for the bad things to make sure that we ha both we as a company and like the broader society are kind of prepared to handle the potential downsides.
[00:22:28] And so at the moment we kind of track three different categories. One is kind of bio risk, another is cybersecurity, and a third is kind of research automation and model autonomy. And that’s kind of what ties the most into the SWE-Bench, where Got it. Where coding is not all of automating research, but it is one very important key component.
[00:22:47] And so we initially created Swyx Venture verified as part of like building out evals for that mono autonomy work stream. And now. I think for like we have to move beyond that, towards, I’m looking more at like, can models [00:23:00] actually start to actually automate research workflow.
[00:23:02] swyx: Yeah. Amazing.
[00:23:03] Okay. Abi, anything else to add on just the general, what people should know about preparedness and how evals and human data and alignment all work together at that?
[00:23:12] Mia: I think maybe the thing that I would say is that we really appreciate, we, we work really hard to build these events and, and so we, that’s where we published.
[00:23:23] SWE-Bench ver verified and that’s where we’re like sharing GDP via these sorts of things. We also deeply appreciate like other people and the entire field to kind of build EVAs and, and share them. And we use them like SWE-Bench program, like, yes, but that’s a better eva now we should use them. So would really encourage people to find more ways to.
[00:23:43] Create and share ev events that we can, we and the entire field can use to measure like progress.
[00:23:50] swyx: Yeah.
[00:23:50] Mia: On, on, on like a variety of capabilities, including, including coding, because it’s important to understand, so where we are,
[00:23:57] swyx: me, I had to leave. But we’re, we are just kind of [00:24:00] talking a little bit about like the, the future directions that we want evals to go.
[00:24:02] Mia: Mm-hmm.
[00:24:03] swyx: And I, I think here, here we can dive in on like, give us. Good work on these, these, these things. We’ll talk to you, you know here’s your platform to make a call. Look for what you’re looking for.
[00:24:15] Olivia: I think a few things that would be useful. I’d say first of all, really, really hard task. Like the kinds of things that would take top-notch engineers months or teams weeks would be quite good.
[00:24:26] Especially if. Breeding is reliable and breeding is like, you know, you have for example, like rubrics that have been sourced and validated by many people in the field. I think that’d be quite valuable. I think also benchmarks on kind of creating products end to end. I think as people are like putting more, that would be quite useful.
[00:24:42] I think. A third thing that I’d say that is maybe not quite an eval, but I think it’s still relevant to the kind of overall mission of like. We as a field and as a world should be tracking, like where are these capabilities going? I’d like to see more metrics the tracking, like real world usage.
[00:24:57] Like how much is AI [00:25:00] actually being used in the field and how much is it, you know, replacing people’s jobs? How much is it? You know, augmenting people is speeding people up, just like real world metrics. Yeah,
[00:25:08] swyx: yeah. The, the, the replacement thing is always like a sensitive one on the, on the sort of PR side of things.
[00:25:12] But you know, we create new jobs that, that manage the old jobs and that’s how it’s yourself like you know, I think in terms of the frontier evals that, that open I is really going to excited to push like you, you put out really good work every single time. What should people expect from, from OPI itself?
[00:25:28] Olivia: I’m not sure I can say what we’re gonna
[00:25:30] swyx: general directions,
[00:25:31] Olivia: I mean, general directions. I think looking at real world impact, like real world real to,
[00:25:38] swyx: yeah, whatever.
[00:25:38] Olivia: That kind of stuff. Yeah. Yeah.
[00:25:39] swyx: Yeah. Amazing. Okay. Well, I’m excited for more real world impact. I, I think you guys have, you know, really made a lot of progress and I think taking a lot of industry leadership for C Bench verified and, and now moving on to C Orange Pro.
[00:25:50] So thank you for doing this. Thank you for being so transparent. And I think people will respond in kind. Yeah,
[00:25:57] Olivia: for your time.
[00:25:58] swyx: Thank [00:26:00] you.