AI News for 3/2/2026-3/3/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 12765 messages) for you. Estimated reading time saved (at 200wpm): 1137 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Probably the most consequential news of today is the confirmation that Anthropic has hit $19B ARR after an extraordinary month in the news and public consciousness, taking it remarkably close to OpenAI’s latest disclosed $20B and making the end of year 2026 target of $30B look comically close in retrospect. If Anthropic does “flip” OpenAI it will certainly be an earth-shattering reorder in the hierarchy that has existed since ChatGPT’s launch.
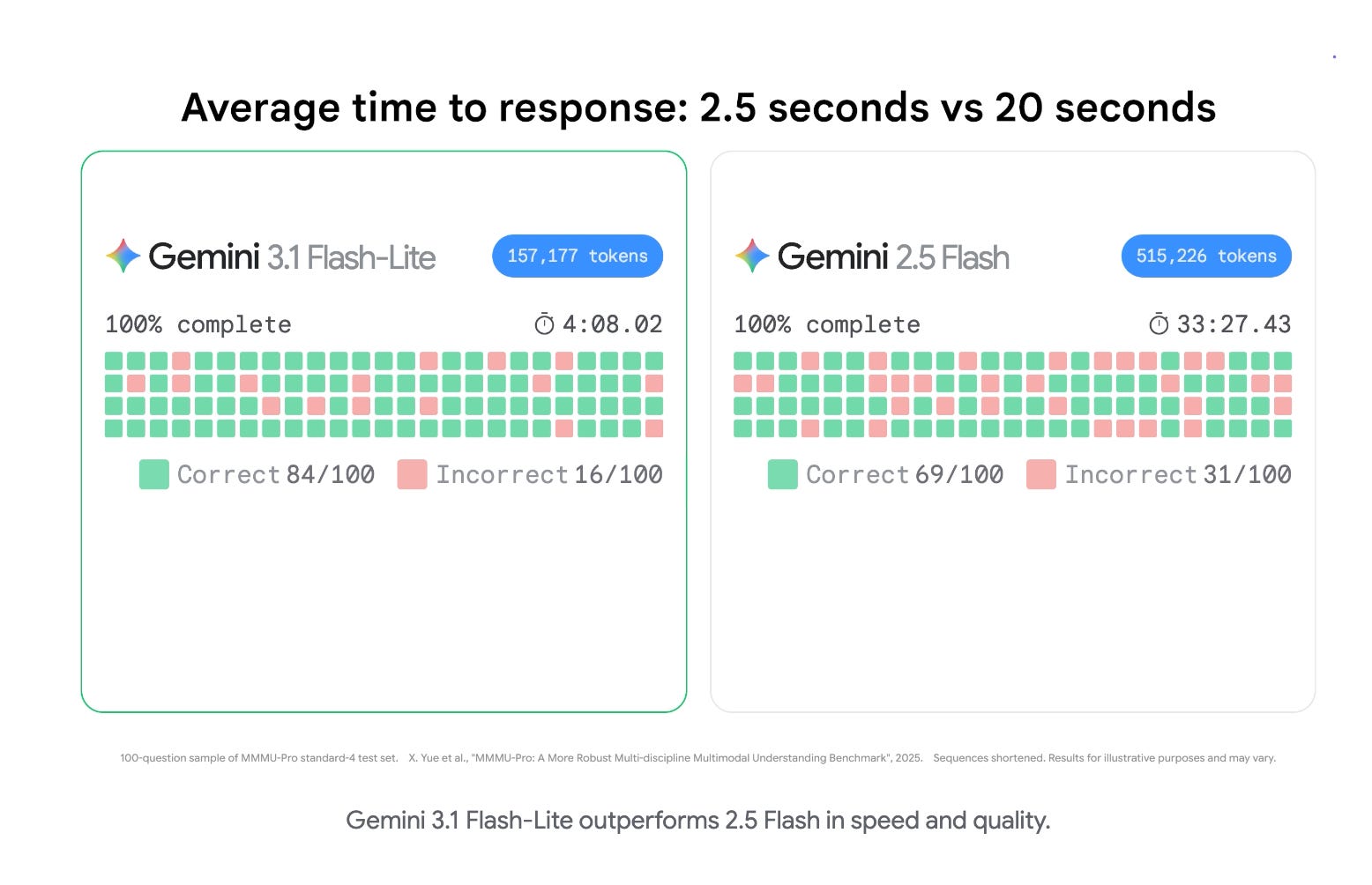
Lots of small notables today - we recommend the delightful sounds of the Gemini 3.1 Flash-Lite demo video which does a more effective job of communicating speed compared to the overall alignment focus of the GPT 5.3 Instant messaging.
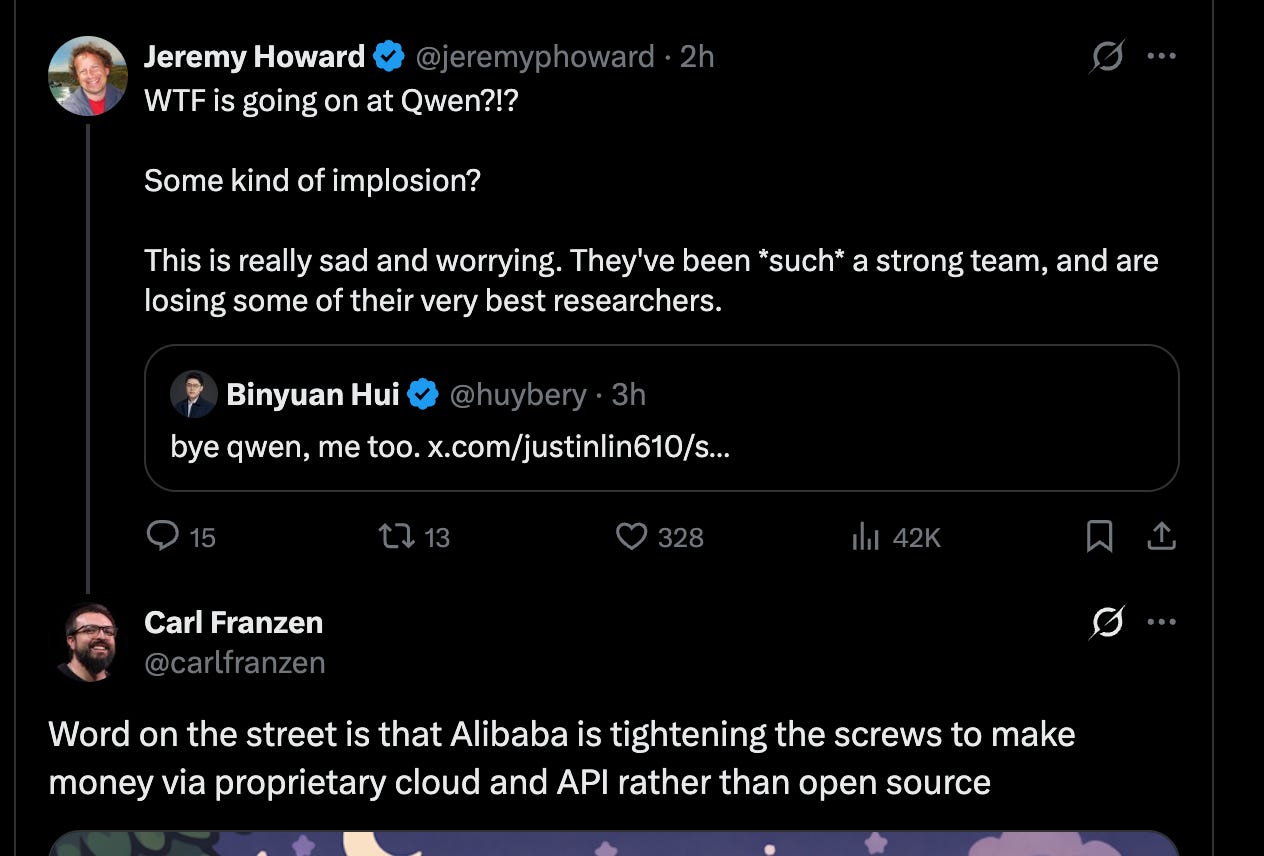
Finally, the mass departures of many Qwen researchers due to what seems like internal politics is a massive, perhaps lasting, blow to Open Source.
AI Twitter Recap
Gemini 3.1 Flash‑Lite launch: “dynamic thinking levels” + aggressive price/perf
- Gemini 3.1 Flash‑Lite (Preview) shipped as Google’s fastest, most cost-efficient Gemini 3-series endpoint, emphasizing latency and throughput for high-volume workloads. DeepMind’s launch thread positions it as “intelligence at scale” with adjustable thinking levels (dial compute based on task complexity) @GoogleDeepMind, with API rollout via AI Studio / Vertex @Google. Jeff Dean highlighted $0.25/M input and $1.50/M output, 1432 Elo on LMArena, and 86.9% GPQA Diamond alongside 2.5× faster time-to-first-token than Gemini 2.5 Flash @JeffDean; Noam Shazeer echoed the “thinking levels” framing as a product knob for “maximum intelligence, minimal latency” @NoamShazeer; Sundar Pichai amplified the same speed/cost message @sundarpichai.
- Third-party benchmarking/positioning: Artificial Analysis reports Flash‑Lite retains a 1M context window, measures >360 output tokens/s and ~5.1s average answer latency, improves their “Intelligence Index” vs 2.5 Flash‑Lite, but pricing increased (blended cost up materially) @ArtificialAnlys. Arena notes Flash‑Lite Preview ranking #36 in Text Arena (1432) and tied around #35 in Code Arena, framed as a strong point on the cost-performance frontier @arena. A recurring community reaction is “Flash‑Lite… very funny Google” due to naming plus rapid cadence @JasonBotterill, and “Google launches models faster than I can finish testing” @matvelloso.
- Multimodal angle: Google staff pushed “use Flash‑Lite instead of writing parsers” for text+images+video+audio+PDF ingestion @koraykv, reinforcing Flash‑Lite as a plumbing model for production workflows.
OpenAI: GPT‑5.3 Instant rollout + “less preachy” + teased GPT‑5.4
- GPT‑5.3 Instant rolled out to all ChatGPT users, explicitly responding to complaints that 5.2 was “too cautious” with “too many caveats.” OpenAI claims improved conversational naturalness, fewer unnecessary refusals/defensive disclaimers, and better search-integrated answers @OpenAI, @nickaturley. OpenAI also states reduced hallucinations: 26.8% better with search and 19.7% without per an internal contributor @aidan_mclau and echoed by staff @christinahkim.
- API/Arena exposure: “GPT‑5.3‑chat‑latest” appears in the API per community reporting @scaling01 and is available for side-by-side evals in Text Arena @arena.
- GPT‑5.4 teased with a high-engagement “sooner than you Think” post @OpenAI, prompting confusion about sequencing vs “5.3 Thinking and Pro will follow soon” chatter @kimmonismus. Multiple tweets speculate 5.4 is also being used as a news-cycle deflection amid DoD/NSA contract controversy @kimmonismus.
Alibaba Qwen shock: leadership exits, “Qwen is nothing without its people,” and open-source uncertainty
- Key departures: A major thread across the dataset is the exit of Qwen’s tech leadership and senior contributors. Justin Lin’s “stepping down” post triggered widespread reaction @JustinLin610, followed by high-signal confirmations/tributes and then more exits including another leader (“bye qwen, me too”) @huybery and a separate sign-off @kxli_2000. External observers describe this as Alibaba Cloud “kicking out” Qwen’s tech lead @YouJiacheng.
- Why it matters technically: Many engineers view Qwen as critical infrastructure for the open model ecosystem—especially <10B and “Pareto frontier” models, plus VLM/OCR derivatives. This is framed as a genuine ecosystem risk if open-weights cadence slows or licensing stance shifts @natolambert, @teortaxesTex, @awnihannun. There’s also immediate speculation on whether Qwen’s OSS posture changes given “popular open models wasn’t enough” @code_star.
- Organizational diagnosis: A recurring interpretation is that “unification” under a higher-level Alibaba structure (reporting to CEO) created political pressure around influence/visibility @Xinyu2ML, with broader commentary about big-tech hierarchies punishing “bridges” who build external trust @hxiao.
- Despite the turmoil, shipping continues: Qwen 3.5 LoRA fine-tuning guides and low-VRAM training recipes spread quickly (notably Unsloth) @UnslothAI, and GPTQ Int4 weights with vLLM/SGLang support were promoted @Alibaba_Qwen. Community also pushed education/reimplementations around Qwen3.5 @rasbt. The tension is: strong release velocity paired with leadership flight.
Long-context + training efficiency: making “impossible” context windows practical
- 87% attention-memory reduction for long-context training: A Together paper highlighted a hybrid of Context Parallelism plus Sequence Parallel-style head chunking, claiming training a 5M context window 8B model on 8×H100 (single node) and cutting attention memory footprint by up to 87% @rronak_. The tweet also calls out a practical gap: most RL post-training for long-context frontier models is still done on only a fraction of the full context due to memory cost.
- FlashOptim (Databricks): Open-source optimizer implementations (AdamW/SGD/Lion) that preserve update equivalence while cutting memory—tweet thread announces
pip install flashoptim@davisblalock, and MosaicAI summarizes >50% training memory reduction, e.g., bringing AdamW training overhead from ~16 bytes/param down to 7 bytes (or 5 with gradient release) and reducing an example 8B finetune peak from 175 GiB → 113 GiB @DbrxMosaicAI. - Heterogeneous infra for RL: SkyPilot argues RL post-training should split workloads across beefy GPUs (trainer), cheap GPUs (rollouts), and high-memory CPUs (replay buffers); Job Groups provides a single YAML orchestration model with coordinated lifecycle and service discovery @skypilot_org.
- Kernel/toolchain gotchas: A CuTeDSL + torch.compile regression report notes ~2.5× slowdown for wrapped kernels (including RMSNorm “Quack” kernels) when made compile-compatible via custom ops—highlighting friction between kernel-level speed and graph compilation requirements @maharshii.
Agent engineering reality check: benchmarks vs “real work,” consensus failures, and tooling shifts (MCP, sandboxes, observability)
- Benchmarks don’t match labor economics: A new database attempts to map agent benchmarks to real-world work distribution, arguing current evaluations overweight math/coding despite most labor/capital being elsewhere @ZhiruoW. This point was boosted as “central problem of AI benchmarking for real work” @emollick. Arena’s Document Arena launch is a direct response: real PDF reasoning side-by-side evals; Claude Opus 4.6 leads (per Arena) @arena.
- Multi-agent coordination is fragile: Byzantine consensus games show LLM agent agreement is unreliable even when benign; failures often come from stalls/timeouts more than adversarial corruption, worsening with group size @omarsar0. Complementary work on Theory of Mind + BDI + symbolic verification suggests cognitive “ToM modules” don’t automatically help; gains depend strongly on base model capability @omarsar0.
- MCP “dead?” vs MCP expanding: There’s an explicit “MCP is dead?” prompt from DAIR’s Omar @omarsar0, but in the same dataset MCP adoption expands: Notion ships MCP/API support for Meeting Notes (one-liner install via Claude Code) @zachtratar; Cursor ships MCP Apps where agents render interactive UIs inside chat @cursor_ai.
- “Kill code review” debate: swyx frames removing human code review as a “Final Boss” of agentic engineering and SDLC inversion @swyx. Counterpoint: thdxr argues that teams “producing this much code” via LLMs may be using them incorrectly; large code volumes create self-defeating codebases and LLMs themselves struggle with the resulting complexity @thdxr.
- Sandboxed “computer use” platforms: Perplexity’s “Computer” draws heavy engagement: Srinivas solicits feature requests @AravSrinivas, and Perplexity positions its product as orchestrating many models and embedding directly into apps with a managed secure sandbox (no API key management) @AravSrinivas, @AskPerplexity. Cursor’s cloud agents similarly run in isolated VMs and output merge-ready PRs with artifacts @dl_weekly.
Talent, governance, and trust: Anthropic vs DoD, OpenAI contract scrutiny, and high-profile moves
- Max Schwarzer (VP Post-Training at OpenAI) → Anthropic: A major personnel move: Schwarzer announced leaving OpenAI after leading post-training and shipping GPT‑5/5.1/5.2/5.3-Codex, joining Anthropic to return to IC RL research @max_a_schwarzer. This fueled narratives of “big win for Anthropic” @kimmonismus and broader “legends dropping out” anxiety @yacinelearning.
- Anthropic vs Pentagon/Palantir tension: Reporting claims DoD threatened to label Anthropic a “supply chain risk,” potentially impacting Palantir’s usage for federal work; Anthropic wants safeguards (mass domestic surveillance + autonomous weapons) @srimuppidi, with additional coverage pointers @aaronpholmes.
- OpenAI–DoD / NSA trust crisis: Multiple tweets demand actual contract language, arguing “incidental” surveillance wording historically enabled warrantless domestic surveillance; critics cite PRISM/Upstream and FISA/EO 12333 context @jeremyphoward, and call for independent legal red-teaming rather than “trust us” assurances @sjgadler. This is repeatedly linked to the hypothesis that OpenAI will use model launches to steer the narrative.
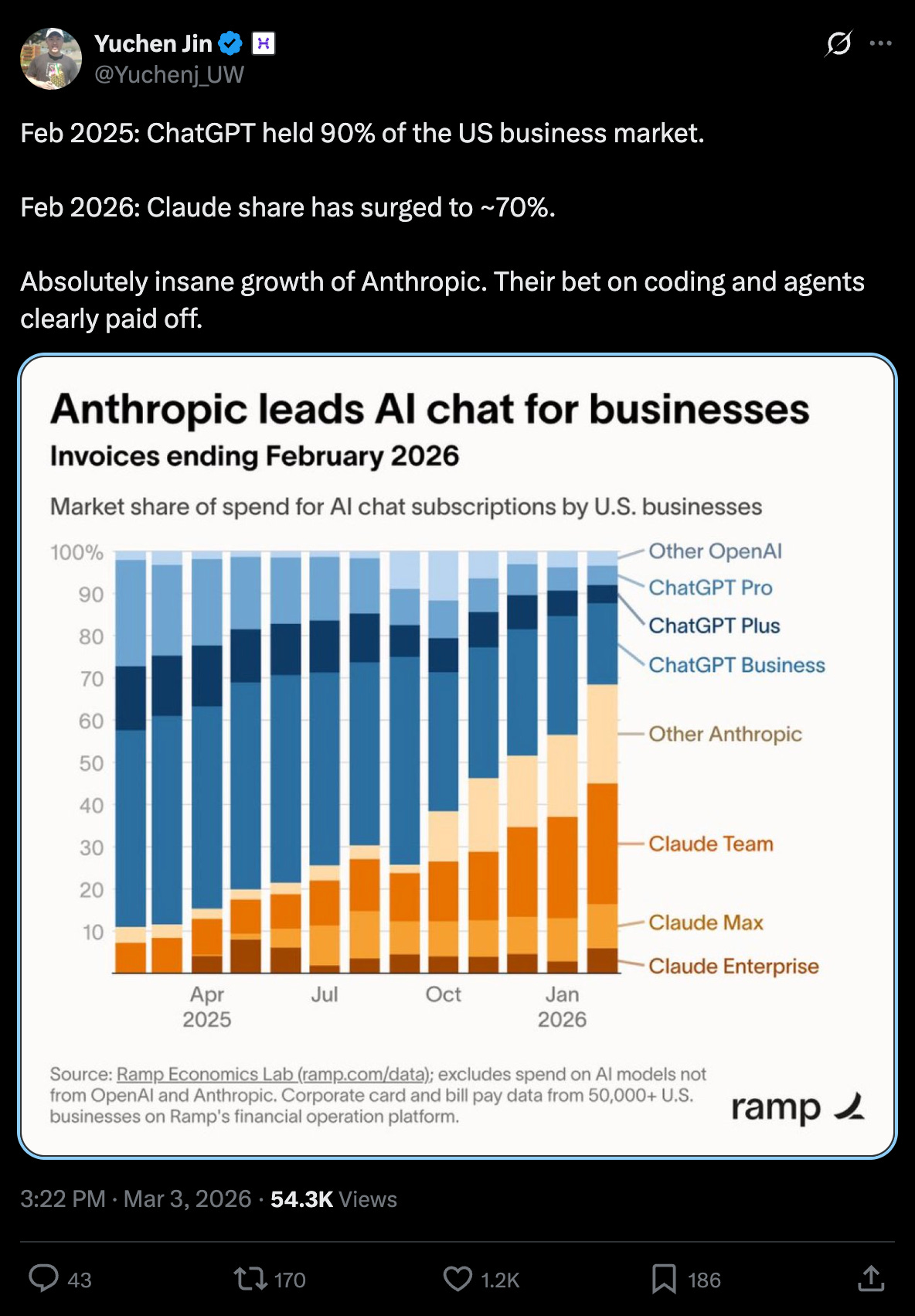
- Market-share claims: One viral claim states Claude surged from minority share to dominating US business market share vs ChatGPT within a year @Yuchenj_UW. Treat this as directional unless you can validate the underlying dataset, but it reflects perceived momentum: “coding + agents paid off.”
Top tweets (by engagement, tech-focused)
- GPT‑5.4 teaser: “5.4 sooner than you Think.” @OpenAI
- Gemini 3.1 Flash‑Lite launch thread @GoogleDeepMind
- GPT‑5.3 Instant rollout + “less preachy” @OpenAI
- Qwen leadership departure (“stepping down”) @JustinLin610 and follow-on sign-offs @huybery
- Unsloth: Qwen3.5 LoRA with ~5GB VRAM claim + notebook @UnslothAI
- Cursor: MCP Apps (interactive UIs inside agent chat) @cursor_ai
- Together long-context training memory reduction (up to 87%) @rronak_
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.5 Model Releases and Benchmarks
-
Qwen 2.5 -> 3 -> 3.5, smallest models. Incredible improvement over the generations. (Activity: 1017): Qwen 3.5 is a notable advancement in the Qwen model series, featuring a
0.8Bparameter model that includes a vision encoder, suggesting the language model component is even smaller. This model is part of a trend towards smaller, more efficient models, such as the current smaller MoE (Mixture of Experts) models, which are praised for their performance. Despite its size, Qwen 3.5 has been criticized for factual inaccuracies, such as incorrect information about aircraft engines, highlighting the need for rigorous fact-checking. Commenters highlight the potential of smaller models like Qwen 3.5 to enable personal assistants on local machines, emphasizing their efficiency and accessibility for users with limited GPU resources. However, there is concern over the model’s tendency to hallucinate facts, which could undermine its reliability.- The smaller Qwen models, particularly the MoE (Mixture of Experts) models, are noted for their impressive performance improvements over previous generations. These models are becoming increasingly viable for personal use on local machines, offering significant advancements in efficiency and capability, even at smaller scales.
- A user highlights the hallucination issues in Qwen 3.5, pointing out specific factual inaccuracies related to aircraft engine types and configurations. This underscores the importance of fact-checking outputs from AI models, as they can confidently present incorrect information.
- The performance of smaller quantized models, such as the 4B model, is praised for its efficiency on less powerful hardware. A user reports achieving 60 tokens per second with 128k context using
llama.cpp, which is considered a significant improvement over older, larger models. This demonstrates the potential for high-performance AI on local, resource-constrained environments.