Join Kyle, Nader, Vibhu, and swyx live at NVIDIA GTC next week!
Now that AIE Europe tix are ~sold out, our attention turns to Miami and World’s Fair!
The definitive AI Accelerator chip company has more than 10xed this AI Summer:
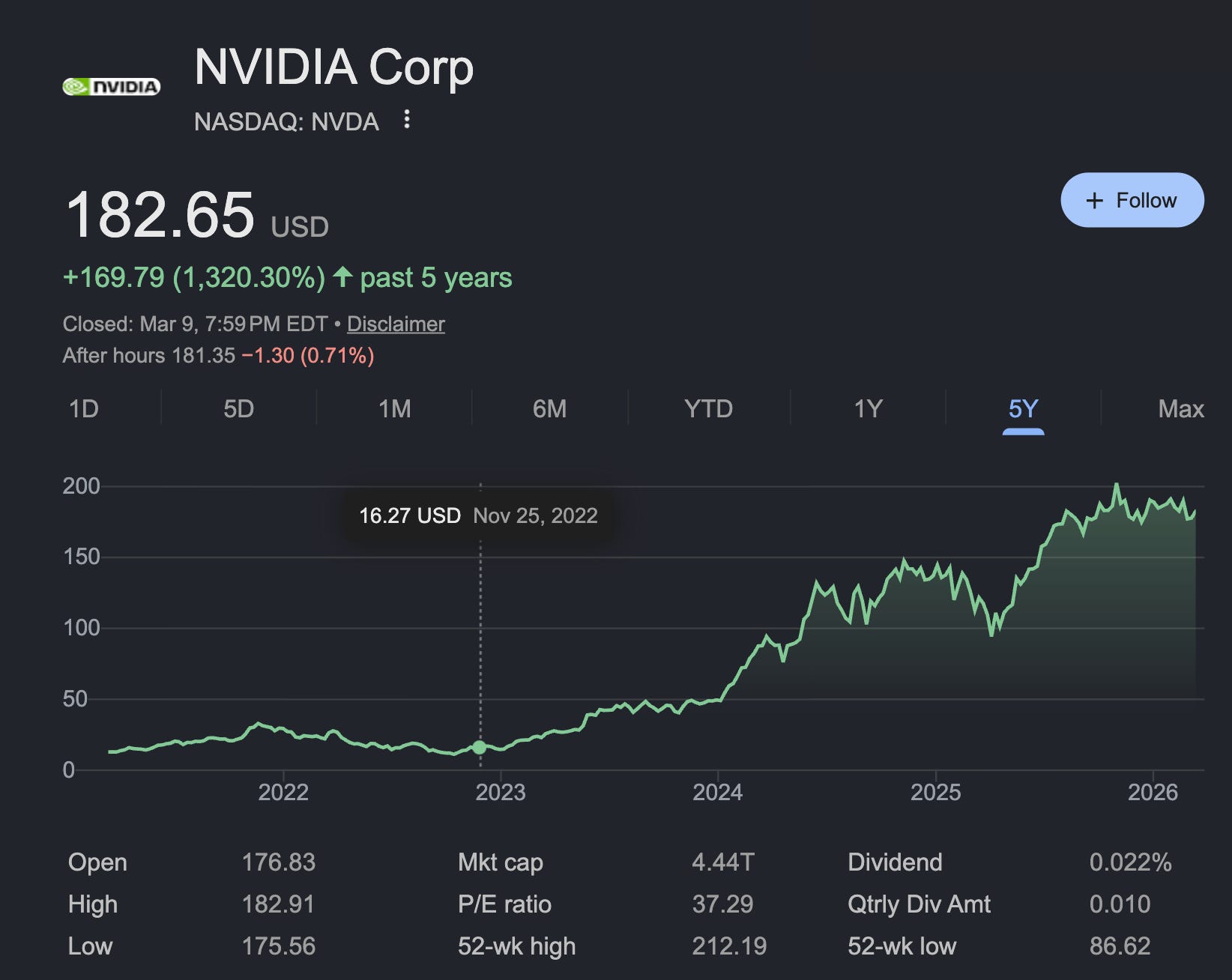
And is now a $4.4 trillion megacorp… that is somehow still moving like a startup. We are blessed to have a unique relationship with our first ever NVIDIA guests: Kyle Kranen who gave a great inference keynote at the first World’s Fair and is one of the leading architects of NVIDIA Dynamo (a Datacenter scale inference framework supporting SGLang, TRT-LLM, vLLM), and Nader Khalil, a friend of swyx from our days in Celo in The Arena, who has been drawing developers at GTC since before they were even a glimmer in the eye of NVIDIA:

Nader discusses how NVIDIA Brev has drastically reduced the barriers to entry for developers to get a top of the line GPU up and running, and Kyle explains NVIDIA Dynamo as a data center scale inference engine that optimizes serving by scaling out, leveraging techniques like prefill/decode disaggregation, scheduling, and Kubernetes-based orchestration, framed around cost, latency, and quality tradeoffs.
We also dive into Jensen’s “SOL” (Speed of Light) first-principles urgency concept, long-context limits and model/hardware co-design, internal model APIs (https://build.nvidia.com), and upcoming Dynamo and agent sessions at GTC.
Full Video pod on YouTube
Timestamps
00:00 Agent Security Basics
00:39 Podcast Welcome and Guests
07:19 Acquisition and DevEx Shift
13:48 SOL Culture and Dynamo Setup
27:38 Why Scale Out Wins
29:02 Scale Up Limits Explained
30:24 From Laptop to Multi Node
33:07 Cost Quality Latency Tradeoffs
38:42 Disaggregation Prefill vs Decode
41:05 Kubernetes Scaling with Grove
43:20 Context Length and Co Design
57:34 Security Meets Agents
58:01 Agent Permissions Model
59:10 Build Nvidia Inference Gateway
01:01:52 Hackathons And Autonomy Dreams
01:10:26 Local GPUs And Scaling Inference
01:15:31 Long Running Agents And SF Reflections
Transcript
Agent Security Basics
Nader: Agents can do three things. They can access your files, they can access the internet, and then now they can write custom code and execute it. You literally only let an agent do two of those three things. If you can access your files and you can write custom code, you don’t want internet access because that’s one to see full vulnerability, right?
If you have access to internet and your file system, you should know the full scope of what that agent’s capable of doing. Otherwise, now we can get injected or something that can happen. And so that’s a lot of what we’ve been thinking about is like, you know, how do we both enable this because it’s clearly the future.
But then also, you know, what, what are these enforcement points that we can start to like protect?
swyx: All right.
Podcast Welcome and Guests
swyx: Welcome to the Lean Space podcast in the Chromo studio. Welcome to all the guests here. Uh, we are back with our guest host Viu. Welcome. Good to have you back. And our friends, uh, Netter and Kyle from Nvidia. Welcome.
Kyle: Yeah, thanks for having us.
swyx: Yeah, thank you. Actually, I don’t even know your titles.
Uh, I know you’re like architect something of Dynamo.
Kyle: Yeah. I, I’m one of the engineering leaders [00:01:00] and a architects of Dynamo.
swyx: And you’re director of something and developers, developer tech.
Nader: Yeah.
swyx: You’re the developers, developers, developers guy at nvidia,
Nader: open source agent marketing, brev,
swyx: and like
Nader: Devrel tools and stuff.
swyx: Yeah. Been
Nader: the focus.
swyx: And we’re, we’re kind of recording this ahead of Nvidia, GTC, which is coming to town, uh, again, uh, or taking over town, uh, which, uh, which we’ll all be at. Um, and we’ll talk a little bit about your sessions and stuff. Yeah.
Nader: We’re super excited for it.
GTC Booth Stunt Stories
swyx: One of my favorite memories for Nader, like you always do like marketing stunts and like while you were at Rev, you like had this surfboard that you like, went down to GTC with and like, NA Nvidia apparently, like did so much that they bought you.
Like what, what was that like? What was that?
Nader: Yeah. Yeah, we, we, um. Our logo was a chaka. We, we, uh, we were always just kind of like trying to keep true to who we were. I think, you know, some stuff, startups, you’re like trying to pretend that you’re a bigger, more mature company than you are. And it was actually Evan Conrad from SF Compute who was just like, you guys are like previous
swyx: guest.
Yeah.
Nader: Amazing. Oh, really? Amazing. Yeah. He was just like, guys, you’re two dudes in the room. Why are you [00:02:00] pretending that you’re not? Uh, and so then we were like, okay, let’s make the logo a shaka. We brought surfboards to our booth to GTC and the energy was great. Yeah. Some palm trees too. They,
Kyle: they actually poked out over like the, the walls so you could, you could see the bread booth.
Oh, that’s so funny. And
Nader: no one else,
Kyle: just from very far away.
Nader: Oh, so you remember it back
Kyle: then? Yeah I remember it pre-acquisition. I was like, oh, those guys look cool,
Nader: dude. That makes sense. ‘cause uh, we, so we signed up really last minute, and so we had the last booth. It was all the way in the corner. And so I was, I was worried that no one was gonna come.
So that’s why we had like the palm trees. We really came in with the surfboards. We even had one of our investors bring her dog and then she was just like walking the dog around to try to like, bring energy towards our booth. Yeah.
swyx: Steph.
Kyle: Yeah. Yeah, she’s the best,
swyx: you know, as a conference organizer, I love that.
Right? Like, it’s like everyone who sponsors a conference comes, does their booth. They’re like, we are changing the future of ai or something, some generic bullshit and like, no, like actually try to stand out, make it fun, right? And people still remember it after three years.
Nader: Yeah. Yeah. You know what’s so funny?
I’ll, I’ll send, I’ll give you this clip if you wanna, if you wanna add it [00:03:00] in, but, uh, my wife was at the time fiance, she was in medical school and she came to help us. ‘cause it was like a big moment for us. And so we, we bought this cricket, it’s like a vinyl, like a vinyl, uh, printer. ‘cause like, how else are we gonna label the surfboard?
So, we got a surfboard, luckily was able to purchase that on the company card. We got a cricket and it was just like fine tuning for enterprises or something like that, that we put on the. On the surfboard and it’s 1:00 AM the day before we go to GTC. She’s helping me put these like vinyl stickers on.
And she goes, you son of, she’s like, if you pull this off, you son of a bitch. And so, uh, right. Pretty much after the acquisition, I stitched that with the mag music acquisition. I sent it to our family group chat. Oh
swyx: Yeah. No, well, she, she made a good choice there. Was that like basically the origin story for Launchable is that we, it was, and maybe we should explain what Brev is and
Nader: Yeah.
Yeah. Uh, I mean, brev is just, it’s a developer tool that makes it really easy to get a GPU. So we connect a bunch of different GPU sources. So the basics of it is like, how quickly can we SSH you into a G, into a GPU and whenever we would talk to users, they wanted A GPU. They wanted an A 100. And if you go to like any cloud [00:04:00] provisioning page, usually it’s like three pages of forms or in the forms somewhere there’s a dropdown.
And in the dropdown there’s some weird code that you know to translate to an A 100. And I remember just thinking like. Every time someone says they want an A 100, like the piece of text that they’re telling me that they want is like, stuffed away in the corner. Yeah. And so we were like, what if the biggest piece of text was what the user’s asking for?
And so when you go to Brev, it’s just big GPU chips with the type that you want with
swyx: beautiful animations that you worked on pre, like pre you can, like, now you can just prompt it. But back in the day. Yeah. Yeah. Those were handcraft, handcrafted artisanal code.
Nader: Yeah. I was actually really proud of that because, uh, it was an, i I made it in Figma.
Yeah. And then I found, I was like really struggling to figure out how to turn it from like Figma to react. So what it actually is, is just an SVG and I, I have all the styles and so when you change the chip, whether it’s like active or not it changes the SVG code and that somehow like renders like, looks like it’s animating, but it, we just had the transition slow, but it’s just like the, a JavaScript function to change the like underlying SVG.
Yeah. And that was how I ended up like figuring out how to move it from from Figma. But yeah, that’s Art Artisan. [00:05:00]
Kyle: Speaking of marketing stunts though, he actually used those SVGs. Or kind of use those SVGs to make these cards.
Nader: Oh yeah. Like
Kyle: a GPU gift card Yes. That he handed out everywhere. That was actually my first impression of that
Nader: one.
Yeah,
swyx: yeah, yeah.
Nader: Yeah.
swyx: I think I still have one of them.
Nader: They look great.
Kyle: Yeah.
Nader: I have a ton of them still actually in our garage, which just, they don’t have labels. We should honestly like bring, bring them back. But, um, I found this old printing press here, actually just around the corner on Ven ness. And it’s a third generation San Francisco shop.
And so I come in an excited startup founder trying to like, and they just have this crazy old machinery and I’m in awe. ‘cause the the whole building is so physical. Like you’re seeing these machines, they have like pedals to like move these saws and whatever. I don’t know what this machinery is, but I saw all three generations.
Like there’s like the grandpa, the father and the son, and the son was like, around my age. Well,
swyx: it’s like a holy, holy trinity.
Nader: It’s funny because we, so I just took the same SVG and we just like printed it and it’s foil printing, so they make a a, a mold. That’s like an inverse of like the A 100 and then they put the foil on it [00:06:00] and then they press it into the paper.
And I remember once we got them, he was like, Hey, don’t forget about us. You know, I guess like early Apple and Cisco’s first business cards were all made there. And so he was like, yeah, we, we get like the startup businesses but then as they mature, they kind of go somewhere else. And so I actually, I think we were talking with marketing about like using them for some, we should go back and make some cards.
swyx: Yeah, yeah, yeah. You know, I remember, you know, as a very, very small breadth investor, I was like, why are we spending time like, doing these like stunts for GPUs? Like, you know, I think like as a, you know, typical like cloud hard hardware person, you go into an AWS you pick like T five X xl, whatever, and it’s just like from a list and you look at the specs like, why animate this GP?
And, and I, I do think like it just shows the level of care that goes throughout birth and Yeah. And now, and also the, and,
Nader: and Nvidia. I think that’s what the, the thing that struck me most when we first came in was like the amount of passion that everyone has. Like, I think, um, you know, you talk to, you talk to Kyle, you talk to, like, every VP that I’ve met at Nvidia goes so close to the metal.
Like, I remember it was almost a year ago, and like my VP asked me, he’s like, Hey, [00:07:00] what’s cursor? And like, are you using it? And if so, why? Surprised at this, and he downloaded Cursor and he was asking me to help him like, use it. And I thought that was, uh, or like, just show him what he, you know, why we were using it.
And so, the amount of care that I think everyone has and the passion, appreciate, passion and appreciation for the moment. Right. This is a very unique time. So it’s really cool to see everyone really like, uh, appreciate that.
swyx: Yeah.
Acquisition and DevEx Shift
swyx: One thing I wanted to do before we move over to sort of like research topics and, uh, the, the stuff that Kyle’s working on is just tell the story of the acquisition, right?
Like, not many people have been, been through an acquisition with Nvidia. What’s it like? Uh, what, yeah, just anything you’d like to say.
Nader: It’s a crazy experience. I think, uh, you know, we were the thing that was the most exciting for us was. Our goal was just to make it easier for developers.
We wanted to find access to GPUs, make it easier to do that. And then all, oh, actually your question about launchable. So launchable was just make one click exper, like one click deploys for any software on top of the GPU. Mm-hmm. And so what we really liked about Nvidia was that it felt like we just got a lot more resources to do all of that.
I think, uh, you [00:08:00] know, NVIDIA’s goal is to make things as easy for developers as possible. So there was a really nice like synergy there. I think that, you know, when it comes to like an acquisition, I think the amount that the soul of the products align, I think is gonna be. Is going speak to the success of the acquisition.
Yeah. And so it in many ways feels like we’re home. This is a really great outcome for us. Like we you know, I love brev.nvidia.com. Like you should, you should use it’s, it’s the
Kyle: front page for GPUs.
Nader: Yeah. Yeah. If you want GP views,
Kyle: you go there, get
swyx: it there, and it’s like internally is growing very quickly.
I, I don’t remember You said some stats there.
Nader: Yeah, yeah, yeah. It’s, uh, I, I wish I had the exact numbers, but like internally, externally, it’s been growing really quickly. We’ve been working with a bunch of partners with a bunch of different customers and ISVs, if you have a solution that you want someone that runs on the GPU and you want people to use it quickly, we can bundle it up, uh, in a launchable and make it a one click run.
If you’re doing things and you want just like a sandbox or something to run on, right. Like open claw. Huge moment. Super exciting. Our, uh, and we’ll talk into it more, but. You know, internally, people wanna run this, and you, we know we have to be really careful from the security implications. Do we let this run on the corporate network?
Security’s guidance was, Hey, [00:09:00] run this on breath, it’s in, you know, it’s, it’s, it’s a vm, it’s sitting in the cloud, it’s off the corporate network. It’s isolated. And so that’s been our stance internally and externally about how to even run something like open call while we figure out how to run these things securely.
But yeah,
swyx: I think there’s also like, you almost like we’re the right team at the right time when Nvidia is starting to invest a lot more in developer experience or whatever you call it. Yeah. Uh, UX or I don’t know what you call it, like software. Like obviously NVIDIA is always invested in software, but like, there’s like, this is like a different audience.
Yeah. It’s a
Nader: wider
Kyle: developer base.
swyx: Yeah. Right.
Nader: Yeah. Yeah. You know, it’s funny, it’s like, it’s not, uh,
swyx: so like, what, what is it called internally? What, what is this that people should be aware that is going on there?
Nader: Uh, what, like developer experience
swyx: or, yeah, yeah. Is it’s called just developer experience or is there like a broader strategy here
Nader: in Nvidia?
Um, Nvidia always wants to make a good developer experience. The thing is and a lot of the technology is just really complicated. Like, it’s not, it’s uh, you know, I think, um. The thing that’s been really growing or the AI’s growing is having a huge moment, not [00:10:00] because like, let’s say data scientists in 2018, were quiet then and are much louder now.
The pie is com, right? There’s a whole bunch of new audiences. My mom’s wondering what she’s doing. My sister’s learned, like taught herself how to code. Like the, um, you know, I, I actually think just generally AI’s a big equalizer and you’re seeing a more like technologically literate society, I guess.
Like everyone’s, everyone’s learning how to code. Uh, there isn’t really an excuse for that. And so building a good UX means that you really understand who your end user is. And when your end user becomes such a wide, uh, variety of people, then you have to almost like reinvent the practice, right? Yeah. You have
Kyle: to, and actually build more developer ux, right?
Because the, there are tiers of developer base that were added. You know, the, the hackers that are building on top of open claw, right? For example, have never used gpu. They don’t know what kuda is. They, they, they just want to run something.
Nader: Yeah.
Kyle: You need new UX that is not just. Hey, you know, how do you program something in Cuda and run it?
And then, and then we built, you know, like when Deep Learning was getting big, we built, we built Torch and, and, but so recently the amount of like [00:11:00] layers that are added to that developer stack has just exploded because AI has become ubiquitous. Everyone’s using it in different ways. Yeah. It’s
Nader: moving fast in every direction.
Vertical, horizontal.
Vibhu: Yeah. You guys, you even take it down to hardware, like the DGX Spark, you know, it’s, it’s basically the same system as just throwing it up on big GPU cluster.
Nader: Yeah, yeah, yeah. It’s amazing. Blackwell.
swyx: Yeah. Uh, we saw the preview at the last year’s GTC and that was one of the better performing, uh, videos so far, and video coverage so far.
Awesome. This will beat it. Um,
Nader: that was
swyx: actually, we have fingers
Nader: crossed. Yeah.
DGX Spark and Remote Access
Nader: Even when Grace Blackwell or when, um, uh, DGX Spark was first coming out getting to be involved in that from the beginning of the developer experience. And it just comes back to what you
swyx: were involved.
Nader: Yeah. St. St.
swyx: Mars.
Nader: Yeah. Yeah. I mean from, it was just like, I, I got an email, we just got thrown into the loop and suddenly yeah, I, it was actually really funny ‘cause I’m still pretty fresh from the acquisition and I’m, I’m getting an email from a bunch of the engineering VPs about like, the new hardware, GPU chip, like we’re, or not chip, but just GPU system that we’re putting out.
And I’m like, okay, cool. Matters. Now involved with this for the ux, I’m like. What am I gonna do [00:12:00] here? So, I remember the first meeting, I was just like kind of quiet as I was hearing engineering VPs talk about what this box could be, what it could do, how we should use it. And I remember, uh, one of the first ideas that people were idea was like, oh, the first thing that it was like, I think a quote was like, the first thing someone’s gonna wanna do with this is get two of them and run a Kubernetes cluster on top of them.
And I was like, oh, I think I know why I’m here. I was like, the first thing we’re doing is easy. SSH into the machine. And then, and you know, just kind of like scoping it down of like, once you can do that every, you, like the person who wants to run a Kubernetes cluster onto Sparks has a higher propensity for pain, then, then you know someone who buys it and wants to run open Claw right now, right?
If you can make sure that that’s as effortless as possible, then the rest becomes easy. So there’s a tool called Nvidia Sync. It just makes the SSH connection really simple. So, you know, if you think about it like. If you have a Mac, uh, or a PC or whatever, if you have a laptop and you buy this GPU and you want to use it, you should be able to use it like it’s A-A-G-P-U in the cloud, right?
Um, but there’s all this friction of like, how do you actually get into that? That’s part of [00:13:00] Revs value proposition is just, you know, there’s a CLI that wraps SSH and makes it simple. And so our goal is just get you into that machine really easily. And one thing we just launched at CES, it’s in, it’s still in like early access.
We’re ironing out some kinks, but it should be ready by GTC. You can register your spark on Brev. And so now if you
swyx: like remote managed yeah, local hardware. Single pane of glass. Yeah. Yeah. Because Brev can already manage other clouds anyway, right?
Vibhu: Yeah, yeah. And you use the spark on Brev as well, right?
Nader: Yeah. But yeah, exactly. So, so you, you, so you, you set it up at home you can run the command on it, and then it gets it’s essentially it’ll appear in your Brev account, and then you can take your laptop to a Starbucks or to a cafe, and you’ll continue to use your, you can continue use your spark just like any other cloud node on Brev.
Yeah. Yeah. And it’s just like a pre-provisioned center
swyx: in your
Nader: home. Yeah, exactly.
swyx: Yeah. Yeah.
Vibhu: Tiny little data center.
Nader: Tiny little, the size of
Vibhu: your phone.
SOL Culture and Dynamo Setup
swyx: One more thing before we move on to Kyle. Just have so many Jensen stories and I just love, love mining Jensen stories. Uh, my favorite so far is SOL. Uh, what is, yeah, what is S-O-L-S-O-L
Nader: is actually, i, I think [00:14:00] of all the lessons I’ve learned, that one’s definitely my favorite.
Kyle: It’ll always stick with you.
Nader: Yeah. Yeah. I, you know, in your startup, everything’s existential, right? Like we’ve, we’ve run out of money. We were like, on the risk of, of losing payroll, we’ve had to contract our team because we l ran outta money. And so like, um, because of that you’re really always forcing yourself to I to like understand the root cause of everything.
If you get a date, if you get a timeline, you know exactly why that date or timeline is there. You’re, you’re pushing every boundary and like, you’re not just say, you’re not just accepting like a, a no. Just because. And so as you start to introduce more layers, as you start to become a much larger organization, SOL is is essentially like what is the physics, right?
The speed of light moves at a certain speed. So if flight’s moving some slower, then you know something’s in the way. So before trying to like layer reality back in of like, why can’t this be delivered at some date? Let’s just understand the physics. What is the theoretical limit to like, uh, how fast this can go?
And then start to tell me why. ‘cause otherwise people will start telling you why something can’t be done. But actually I think any great leader’s goal is just to create urgency. Yeah. [00:15:00] There’s an infinite
Kyle: create compelling events, right?
Nader: Yeah.
Kyle: Yeah. So l is a term video is used to instigate a compelling event.
You say this is done. How do we get there? What is the minimum? As much as necessary, as little as possible thing that it takes for us to get exactly here and. It helps you just break through a bunch of noise.
swyx: Yeah.
Kyle: Instantly.
swyx: One thing I’m unclear about is, can only Jensen use the SOL card? Like, oh, no, no, no.
Not everyone get the bullshit out because obviously it’s Jensen, but like, can someone else be like, no, like
Kyle: frontline engineers use it.
Nader: Yeah. Every, I think it’s not so much about like, get the bullshit out. It’s like, it’s like, give me the root understanding, right? Like, if you tell me something takes three weeks, it like, well, what’s the first principles?
Yeah, the first principles. It’s like, what’s the, what? Like why is it three weeks? What is the actual yeah. What’s the actual limit of why this is gonna take three weeks? If you’re gonna, if you, if let’s say you wanted to buy a new computer and someone told you it’s gonna be here in five days, what’s the SOL?
Well, like the SOL is like, I could walk into a Best Buy and pick it up for you. Right? So then anything that’s like beyond that is, and is that practical? Is that how we’re gonna, you know, let’s say give everyone in the [00:16:00] company a laptop, like obviously not. So then like that’s the SOL and then it’s like, okay, well if we have to get more than 10, suddenly there might be some, right?
And so now we can kind of piece the reality back.
swyx: So, so this is the. Paul Graham do things that don’t scale. Yeah. And this is also the, what people would now call behi agency. Yeah.
Kyle: It’s actually really interesting because there’s a, there’s a second hardware angle to SOL that like doesn’t come up for all the org sol is used like culturally at a
swyx: media for everything.
I’m also mining for like, I think that can be annoying sometimes. And like someone keeps going IOO you and you’re like, guys, like we have to be stable. We have to, we to fucking plan. Yeah.
Kyle: It’s an interesting balance.
Nader: Yeah. I encounter that with like, actually just with, with Alec, right? ‘cause we, we have a new conference so we need to launch, we have, we have goals of what we wanna launch by, uh, by the conference and like, yeah.
At the end of the day, where is
swyx: this GTC?
Nader: Um, well this is like, so we, I mean we did it for CES, we did for GT CDC before that we’re doing it for GTC San Jose. So I mean, like every, you know, we have a new moment. Um, and we want to launch something. Yeah. And we want to do so at SOL and that does mean that some, there’s some level of prioritization that needs [00:17:00] to happen.
And so it, it is difficult, right? I think, um, you have to be careful with what you’re pushing. You know, stability is important and that should be factored into S-O-L-S-O-L isn’t just like, build everything and let it break, you know, that, that’s part of the conversation. So as you’re laying, layering in all the details, one of them might be, Hey, we could build this, but then it’s not gonna be stable for X, y, z reasons.
And so that was like, one of our conversations for CES was, you know, hey, like we, we can get this into early access registering your spark with brev. But there are a lot of things that we need to do in order to feel really comfortable from a security perspective, right? There’s a lot of networking involved before we deliver that to users.
So it’s like, okay. Let’s get this to a point where we can at least let people experiment with it. We had it in a booth, we had it in Jensen’s keynote, and then let’s go iron out all the networking kinks. And that’s not easy. And so, uh, that can come later. And so that was the way that we layered that back in.
Yeah. But
Kyle: It’s not really about saying like, you don’t have to do the, the maintenance or operational work. It’s more about saying, you know, it’s kind of like [00:18:00] highlights how progress is incremental, right? Like, what is the minimum thing that we can get to. And then there’s SOL for like every component after that.
But there’s the SOL to get you, get you to the, the starting line. And that, that’s usually how it’s asked. Yeah. On the other side, you know, like SOL came out of like hardware at Nvidia. Right. So SOL is like literally if we ran the accelerator or the GPU with like at basically full speed with like no other constraints, like how FAST would be able to make a program go.
swyx: Yeah. Yeah. Right.
Kyle: So
swyx: in, in training that like, you know, then you work back to like some percentage of like MFU for example.
Kyle: Yeah, that’s a, that’s a great example. So like, there’s an, there’s an S-O-L-M-F-U, and then there’s like, you know, what’s practically achievable.
swyx: Cool. Should we move on to sort of, uh, Kyle’s side?
Uh, Kyle, you’re coming more from the data science world. And, uh, I, I mean I always, whenever, whenever I meet someone who’s done working in tabular stuff, graph neural networks, time series, these are basically when I go to new reps, I go to ICML, I walk the back halls. There’s always like a small group of graph people.
Yes. Absolute small group of tabular people. [00:19:00] And like, there’s no one there. And like, it’s very like, you know what I mean? Like, yeah, no, like it’s, it’s important interesting work if you care about solving the problems that they solve.
Kyle: Yeah.
swyx: But everyone else is just LMS all the time.
Kyle: Yeah. I mean it’s like, it’s like the black hole, right?
Has the event horizon reached this yet in nerves? Um,
swyx: but like, you know, those are, those are transformers too. Yeah. And, and those are also like interesting things. Anyway, uh, I just wanted to spend a little bit of time on, on those, that background before we go into Dynamo, uh, proper.
Kyle: Yeah, sure. I took a different path to Nvidia than that, or I joined six years ago, seven, if you count, when I was an intern.
So I joined Nvidia, like right outta college. And the first thing I jumped into was not what I’d done in, during internship, which was like, you know, like some stuff for autonomous vehicles, like heavyweight object detection. I jumped into like, you know, something, I’m like, recommenders, this is popular. And
swyx: yeah, he did Rexi
Kyle: as well.
Yeah, Rexi. Yeah. I mean that, that was the taboo data at the time, right? You have tables of like, audience qualities and item qualities, and you’re trying to figure out like which member of [00:20:00] the audience matches which item or, or more practically which item matches which member of the audience. And at the time, really it was like we were trying to enable.
Uh, recommender, which had historically been like a little bit of a CP based workflow into something that like, ran really well in GPUs. And it’s since been done. Like there are a bunch of libraries for Axis that run on GPUs. Uh, the common models like Deeplearning recommendation model, which came outta meta and the wide and deep model, which was used or was released by Google were very accelerated by GPUs using, you know, the fast HBM on the chips, especially to do, you know, vector lookups.
But it was very interesting at the time and super, super relevant because like we were starting to get like. This explosion of feeds and things that required rec recommenders to just actively be on all the time. And sort of transitioned that a little bit towards graph neural networks when I discovered them because I was like, okay, you can actually use graphical neural networks to represent like, relationships between people, items, concepts, and that, that interested me.
So I jumped into that at [00:21:00] Nvidia and, and got really involved for like two-ish years.
swyx: Yeah. Uh, and something I learned from Brian Zaro Yeah. Is that you can just kind of choose your own path in Nvidia.
Kyle: Oh my God. Yeah.
swyx: Which is not a normal big Corp thing. Yeah. Like you, you have a lane, you stay in your lane.
Nader: I think probably the reason why I enjoy being in a, a big company, the mission is the boss probably from a startup guy. Yeah. The mission
swyx: is the boss.
Nader: Yeah. Uh, it feels like a big game of pickup basketball. Like, you know, if you play one, if you wanna play basketball, you just go up to the court and you’re like, Hey look, we’re gonna play this game and we need three.
Yeah. And you just like find your three. That’s honestly for every new initiative that’s what it feels like. Yeah.
Vibhu: It also like shows, right? Like Nvidia. Just releasing state-of-the-art stuff in every domain. Yeah. Like, okay, you expect foundation models with Nemo tron voice just randomly parakeet.
Call parakeet just comes out another one, uh, voice. The
Kyle: video voice team has always been producing.
Vibhu: Yeah. There’s always just every other domain of paper that comes out, dataset that comes out. It’s like, I mean, it also stems back to what Nvidia has to do, right? You have to make chips years before they’re actually produced.
Right? So you need to know, you need to really [00:22:00] focus. The
Kyle: design process starts like
Vibhu: exactly
Kyle: three to five years before the chip gets to the market.
Vibhu: Yeah. I, I’m curious more about what that’s like, right? So like, you have specialist teams. Is it just like, you know, people find an interest, you go in, you go deep on whatever, and that kind of feeds back into, you know, okay, we, we expect predictions.
Like the internals at Nvidia must be crazy. Right? You know? Yeah. Yeah. You know, you, you must. Not even without selling to people, you have your own predictions of where things are going. Yeah. And they’re very based, very grounded. Right?
Kyle: Yeah. It, it, it’s really interesting. So there’s like two things that I think that Amed does, which are quite interesting.
Uh, one is like, we really index into passion. There’s a big. Sort of organizational top sound push to like ensure that people are working on the things that they’re passionate about. So if someone proposes something that’s interesting, many times they can just email someone like way up the chain that they would find this relevant and say like, Hey, can I go work on this?
Nader: It’s actually like I worked at a, a big company for a couple years before, uh, starting on my startup journey and like, it felt very weird if you were to like email out of chain, if that makes [00:23:00] sense. Yeah. The emails at Nvidia are like mosh pits
swyx: shoot,
Nader: and it’s just like 60 people, just whatever. And like they’re, there’s this,
swyx: they got messy like, reply all you,
Nader: oh, it’s in, it’s insane.
It’s insane. They just
Kyle: help. You know, Maxim,
Nader: the context. But, but that’s actually like, I’ve actually, so this is a weird thing where I used to be like, why would we send emails? We have Slack. I am the entire, I’m the exact opposite. I feel so bad for anyone who’s like messaging me on Slack ‘cause I’m so unresponsive.
swyx: Your email
Nader: Maxi, email Maxim. I’m email maxing Now email is a different, email is perfect because man, we can’t work together. I’m email is great, right? Because important threads get bumped back up, right? Yeah, yeah. Um, and so Slack doesn’t do that. So I just have like this casino going off on the right or on the left and like, I don’t know which thread was from where or what, but like the threads get And then also just like the subject, so you can have like working threads.
I think what’s difficult is like when you’re small, if you’re just not 40,000 people I think Slack will work fine, but there’s, I don’t know what the inflection point is. There is gonna be a point where that becomes really messy and you’ll actually prefer having email. ‘cause you can have working threads.
You can cc more than nine people in a thread.
Kyle: You can fork stuff.
Nader: You can [00:24:00] fork stuff, which is super nice and just like y Yeah. And so, but that is part of where you can propose a plan. You can also just. Start, honestly, momentum’s the only authority, right? So like, if you can just start, start to make a little bit of progress and show someone something, and then they can try it.
That’s, I think what’s been, you know, I think the most effective way to push anything for forward. And that’s both at Nvidia and I think just generally.
Kyle: Yeah, there’s, there’s the other concept that like is explored a lot at Nvidia, which is this idea of a zero billion dollar business. Like market creation is a big thing at Nvidia.
Like,
swyx: oh, you want to go and start a zero billion dollar business?
Kyle: Jensen says, we are completely happy investing in zero billion dollar markets. We don’t care if this creates revenue. It’s important for us to know about this market. We think it will be important in the future. It can be zero billion dollars for a while.
I’m probably minging as words here for, but like, you know, like, I’ll give an example. NVIDIA’s been working on autonomous driving for a a long time,
swyx: like an Nvidia car.
Kyle: No, they, they’ve
Vibhu: used the Mercedes, right? They’re around the HQ and I think it finally just got licensed out. Now they’re starting to be used quite a [00:25:00] bit.
For 10 years you’ve been seeing Mercedes with Nvidia logos driving.
Kyle: If you’re in like the South San Santa Clara, it’s, it’s actually from South. Yeah. So, um. Zero billion dollar markets are, are a thing like, you know, Jensen,
swyx: I mean, okay, look, cars are not a zero billion dollar market. But yeah, that’s a bad example.
Nader: I think, I think he’s, he’s messaging, uh, zero today, but, or even like internally, right? Like, like it’s like, uh, an org doesn’t have to ruthlessly find revenue very quickly to justify their existence. Right. Like a lot of the important research, a lot of the important technology being developed that, that’s kind of
Kyle: where research, research is very ide ideologically free at Nvidia.
Yeah. Like they can pursue things that they were
swyx: Were you research officially?
Kyle: I was never in research. Officially. I was always in engineering. Yeah. We in, I’m in an org called Deep Warning Algorithms, which is basically just how do we make things that are relevant to deep warning go fast.
swyx: That sounds freaking cool.
Vibhu: And I think a lot of that is underappreciated, right? Like time series. This week Google put out time. FF paper. Yeah. A new time series, paper res. Uh, Symantec, ID [00:26:00] started applying Transformers LMS to Yes. Rec system. Yes. And when you think the scale of companies deploying these right. Amazon recommendations, Google web search, it’s like, it’s huge scale and
Kyle: Yeah.
Vibhu: You want fast?
Kyle: Yeah. Yeah. Yeah. Actually it’s, it, I, there’s a fun moment that brought me like full circle. Like, uh, Amazon Ads recently gave a talk where they talked about using Dynamo for generative recommendation, which was like super, like weirdly cathartic for me. I’m like, oh my God. I’ve, I’ve supplanted what I was working on.
Like, I, you’re using LMS now to do what I was doing five years ago.
swyx: Yeah. Amazing. And let’s go right into Dynamo. Uh, maybe introduce Yeah, sure. To the top down and Yeah.
Kyle: I think at this point a lot of people are familiar with the term of inference. Like funnily enough, like I went from, you know, inference being like a really niche topic to being something that’s like discussed on like normal people’s Twitter feeds.
It’s,
Nader: it’s on billboards
Kyle: here now. Yeah. Very, very strange. Driving, driving, seeing just an inference ad on 1 0 1 inference at scale is becoming a lot more important. Uh, we have these moments like, you know, open claw where you have these [00:27:00] agents that take lots and lots of tokens, but produce, incredible results.
There are many different aspects of test time scaling so that, you know, you can use more inference to generate a better result than if you were to use like a short amount of inference. There’s reasoning, there’s quiring, there’s, adding agency to the model, allowing it to call tools and use skills.
Dyno sort came about at Nvidia. Because myself and a couple others were, were sort of talking about the, these concepts that like, you know, you have inference engines like VLMS, shelan, tenor, TLM and they have like one single copy. They, they, they sort of think about like things as like one single copy, like one replica, right?
Why Scale Out Wins
Kyle: Like one version of the model. But when you’re actually serving things at scale, you can’t just scale up that replica because you end up with like performance problems. There’s a scaling limit to scaling up replicas. So you actually have to scale out to use a, maybe some Kubernetes type terminology.
We kind of realized that there was like. A lot of potential optimization that we could do in scaling out and building systems for data [00:28:00] center scale inference. So Dynamo is this data center scale inference engine that sits on top of the frameworks like VLM Shilling and 10 T lm and just makes things go faster because you can leverage the economy of scale.
The fact that you have KV cash, which we can define a little bit later, uh, in all these machines that is like unique and you wanna figure out like the ways to maximize your cash hits or you want to employ new techniques in inference like disaggregation, which Dynamo had introduced to the world in, in, in March, not introduced, it was a academic talk, but beforehand.
But we are, you know, one of the first frameworks to start, supporting it. And we wanna like, sort of combine all these techniques into sort of a modular framework that allows you to. Accelerate your inference at scale.
Nader: By the way, Kyle and I became friends on my first date, Nvidia, and I always loved, ‘cause like he always teaches me
swyx: new things.
Yeah. By the way, this is why I wanted to put two of you together. I was like, yeah, this is, this is gonna be
Kyle: good. It’s very, it’s very different, you know, like we’ve, we, we’ve, we’ve talked to each other a bunch [00:29:00] actually, you asked like, why, why can’t we scale up?
Nader: Yeah.
Scale Up Limits Explained
Nader: model, you said model replicas.
Kyle: Yeah. So you, so scale up means assigning more
swyx: heavier?
Kyle: Yeah, heavier. Like making things heavier. Yeah, adding more GPUs. Adding more CPUs. Scale out is just like having a barrier saying, I’m gonna duplicate my representation of the model or a representation of this microservice or something, and I’m gonna like, replicate it Many times.
Handle, load. And the reason that you can’t scale, scale up, uh, past some points is like, you know, there, there, there are sort of hardware bounds and algorithmic bounds on, on that type of scaling. So I’ll give you a good example that’s like very trivial. Let’s say you’re on an H 100. The Maxim ENV link domain for H 100, for most Ds H one hundreds is heus, right?
So if you scaled up past that, you’re gonna have to figure out ways to handle the fact that now for the GPUs to communicate, you have to do it over Infin band, which is still very fast, but is not as fast as ENV link.
swyx: Is it like one order of magnitude, like hundreds or,
Kyle: it’s about an order of magnitude?
Yeah. Okay. Um, so
swyx: not terrible.
Kyle: [00:30:00] Yeah. I, I need to, I need to remember the, the data sheet here, like, I think it’s like about 500 gigabytes. Uh, a second unidirectional for ENV link, and about 50 gigabytes a second unidirectional for Infin Band. I, it, it depends on the, the generation.
swyx: I just wanna set this up for people who are not familiar with these kinds of like layers and the trash speed
Vibhu: and all that.
Of course.
From Laptop to Multi Node
Vibhu: Also, maybe even just going like a few steps back before that, like most people are very familiar with. You see a, you know, you can use on your laptop, whatever these steel viol, lm you can just run inference there. All, there’s all, you can, you
can run it on that
Vibhu: laptop. You can run on laptop.
Then you get to, okay, uh, models got pretty big, right? JLM five, they doubled the size, so mm-hmm. Uh, what do you do when you have to go from, okay, I can get 128 gigs of memory. I can run it on a spark. Then you have to go multi GPU. Yeah. Okay. Multi GPU, there’s some support there. Now, if I’m a company and I don’t have like.
I’m not hiring the best researchers for this. Right. But I need to go [00:31:00] multi-node, right? I have a lot of servers. Okay, now there’s efficiency problems, right? You can have multiple eight H 100 nodes, but, you know, is that as a, like, how do you do that efficiently?
Kyle: Yeah. How do you like represent them? How do you choose how to represent the model?
Yeah, exactly right. That’s a, that’s like a hard question. Everyone asks, how do you size oh, I wanna run GLM five, which just came out new model. There have been like four of them in the past week, by the way, like a bunch of new models.
swyx: You know why? Right? Deep seek.
Kyle: No comment. Oh. Yeah, but Ggl, LM five, right?
We, we have this, new model. It’s, it’s like a large size, and you have to figure out how to both scale up and scale out, right? Because you have to find the right representation that you care about. Everyone does this differently. Let’s be very clear. Everyone figures this out in their own path.
Nader: I feel like a lot of AI or ML even is like, is like this. I think people think, you know, I, I was, there was some tweet a few months ago that was like, why hasn’t fine tuning as a service taken off? You know, that might be me. It might have been you. Yeah. But people want it to be such an easy recipe to follow.
But even like if you look at an ML model and specific
Kyle: to you Yeah,
Nader: yeah.
Kyle: And the [00:32:00] model,
Nader: the situation, and there’s just so much tinkering, right? Like when you see a model that has however many experts in the ME model, it’s like, why that many experts? I don’t, they, you know, they tried a bunch of things and that one seemed to do better.
I think when it comes to how you’re serving inference, you know, you have a bunch of decisions to make and there you can always argue that you can take something and make it more optimal. But I think it’s this internal calibration and appetite for continued calibration.
Vibhu: Yeah. And that doesn’t mean like, you know, people aren’t taking a shot at this, like tinker from thinking machines, you know?
Yeah. RL as a service. Yeah, totally. It’s, it also gets even harder when you try to do big model training, right? We’re not the best at training Moes, uh, when they’re pre-trained. Like we saw this with LAMA three, right? They’re trained in such a sparse way that meta knows there’s gonna be a bunch of inference done on these, right?
They’ll open source it, but it’s very trained for what meta infrastructure wants, right? They wanna, they wanna inference it a lot. Now the question to basically think about is, okay, say you wanna serve a chat application, a coding copilot, right? You’re doing a layer of rl, you’re serving a model for X amount of people.
Is it a chat model, a coding model? Dynamo, you know, back to that,
Kyle: it’s [00:33:00] like, yeah, sorry. So you we, we sort of like jumped off of, you know, jumped, uh, on that topic. Everyone has like, their own, own journey.
Cost Quality Latency Tradeoffs
Kyle: And I, I like to think of it as defined by like, what is the model you need? What is the accuracy you need?
Actually I talked to NA about this earlier. There’s three axes you care about. What is the quality that you’re able to produce? So like, are you accurate enough or can you complete the task with enough, performance, high enough performance. Yeah, yeah. Uh, there’s cost. Can you serve the model or serve your workflow?
Because it’s not just the model anymore, it’s the workflow. It’s the multi turn with an agent cheaply enough. And then can you serve it fast enough? And we’re seeing all three of these, like, play out, like we saw, we saw new models from OpenAI that you know, are faster. You have like these new fast versions of models.
You can change the amount of thinking to change the amount of quality, right? Produce more tokens, but at a higher cost in a, in a higher latency. And really like when you start this journey of like trying to figure out how you wanna host a model, you, you, you think about three things. What is the model I need to serve?
How many times do I need to call it? What is the input sequence link was [00:34:00] the, what does the workflow look like on top of it? What is the SLA, what is the latency SLA that I need to achieve? Because there’s usually some, this is usually like a constant, you, you know, the SLA that you need to hit and then like you try and find the lowest cost version that hits all of these constraints.
Usually, you know, you, you start with those things and you say you, you kind of do like a bit of experimentation across some common configurations. You change the tensor parallel size, which is a form of parallelism
Vibhu: I take, it goes even deeper first. Gotta think what model.
Kyle: Yes, course,
of
Kyle: course. It’s like, it’s like a multi-step design process because as you said, you can, you can choose a smaller model and then do more test time scaling and it’ll equate the quality of a larger model because you’re doing the test time scaling or you’re adding a harness or something.
So yes, it, it goes way deeper than that. But from the performance perspective, like once you get to the model you need, you need to host, you look at that and you say, Hey. I have this model, I need to serve it at the speed. What is the right configuration for that?
Nader: You guys see the recent, uh, there was a paper I just saw like a few days ago that, uh, if you run [00:35:00] the same prompt twice, you’re getting like double Just try it
again.
Nader: Yeah, exactly.
Vibhu: And you get a lot. Yeah. But the, the key thing there is you give the context of the failed try, right? Yeah. So it takes a shot. And this has been like, you know, basic guidance for quite a while. Just try again. ‘cause you know, trying, just try again. Did you try again? All advice
Nader: in life.
Vibhu: Just, it’s a paper from Google, if I’m not mistaken, right?
Yeah,
Vibhu: yeah. I think it, it’s like a seven bas little short paper. Yeah. Yeah. The title’s very cute. And it’s just like, yeah, just try again. Give it ask context,
Kyle: multi-shot. You just like, say like, hey, like, you know, like take, take a little bit more, take a little bit more information, try and fail. Fail.
Vibhu: And that basic concept has gone pretty deep.
There’s like, um, self distillation, rl where you, you do self distillation, you do rl and you have past failure and you know, that gives some signal so people take, try it again. Not strong enough.
swyx: Uh, for, for listeners, uh, who listen to here, uh, vivo actually, and I, and we run a second YouTube channel for our paper club where, oh, that’s awesome.
Vivo just covered this. Yeah. Awesome. Self desolation and all that’s, that’s why he, to speed [00:36:00] on it.
Nader: I’ll to check it out.
swyx: Yeah. It, it’s just a good practice, like everyone needs, like a paper club where like you just read papers together and the social pressure just kind of forces you to just,
Nader: we, we,
there’s
Nader: like a big inference.
Kyle: Reading
Nader: group at a video. I feel so bad every time. I I, he put it on like, on our, he shared it.
swyx: One, one of
Nader: your guys,
swyx: uh, is, is big in that, I forget es han Yeah, yeah,
Kyle: es Han’s on my team. Actually. Funny. There’s a, there’s a, there’s a employee transfer between us. Han worked for Nater at Brev, and now he, he’s on my team.
He was
Nader: our head of ai. And then, yeah, once we got in, and
swyx: because I’m always looking for like, okay, can, can I start at another podcast that only does that thing? Yeah. And, uh, Esan was like, I was trying to like nudge Esan into like, is there something here? I mean, I don’t think there’s, there’s new infant techniques every day.
So it’s like, it’s like
Kyle: you would, you would actually be surprised, um, the amount of blog posts you see. And if
swyx: there’s a period where it was like, Medusa hydra, what Eagle, like, you
Kyle: know, now we have new forms of decode, uh, we have new forms of specula, of decoding or new,
swyx: what,
Kyle: what are you
Vibhu: excited? And it’s exciting when you guys put out something like Tron.
‘cause I remember the paper on this Tron three, [00:37:00] uh, the amount of like post train, the on tokens that the GPU rich can just train on. And it, it was a hybrid state space model, right? Yeah.
Kyle: It’s co-designed for the hardware.
Vibhu: Yeah, go design for the hardware. And one of the things was always, you know, the state space models don’t scale as well when you do a conversion or whatever the performance.
And you guys are like, no, just keep draining. And Nitron shows a lot of that. Yeah.
Nader: Also, something cool about Nitron it was released in layers, if you will, very similar to Dynamo. It’s, it’s, it’s essentially it was released as you can, the pre-training, post-training data sets are released. Yeah. The recipes on how to do it are released.
The model itself is released. It’s full model. You just benefit from us turning on the GPUs. But there are companies like, uh, ServiceNow took the dataset and they trained their own model and we were super excited and like, you know, celebrated that work.
Zoom
Vibhu: different. Zoom is, zoom is CGI, I think, uh, you know, also just to add like a lot of models don’t put out based models and if there’s that, why is fine tuning not taken off?
You know, you can do your own training. Yeah,
Kyle: sure.
Vibhu: You guys put out based model, I think you put out everything.
Nader: I believe I know [00:38:00]
swyx: about base. Basically
Vibhu: without base
swyx: basic can be cancelable.
Vibhu: Yeah. Base can be cancelable.
swyx: Yeah.
Vibhu: Safety training.
swyx: Did we get a full picture of dymo? I, I don’t know if we, what,
Nader: what I’d love is you, you mentioned the three axes like break it down of like, you know, what’s prefilled decode and like what are the optimizations that we can get with Dynamo?
Kyle: Yeah. That, that’s, that’s, that’s a great point. So to summarize on that three axis problem, right, there are three things that determine whether or not something can be done with inference, cost, quality, latency, right? Dynamo is supposed to be there to provide you like the runtime that allows you to pull levers to, you know, mix it up and move around the parade of frontier or the preto surface that determines is this actually possible with inference And AI today
Nader: gives you the knobs.
Kyle: Yeah, exactly. It gives you the knobs.
Disaggregation Prefill vs Decode
Kyle: Uh, and one thing that like we, we use a lot in contemporary inference and is, you know, starting to like pick up from, you know, in, in general knowledge is this co concept of disaggregation. So historically. Models would be hosted with a single inference engine. And that inference engine [00:39:00] would ping pong between two phases.
There’s prefill where you’re reading the sequence generating KV cache, which is basically just a set of vectors that represent the sequence. And then using that KV cache to generate new tokens, which is called Decode. And some brilliant researchers across multiple different papers essentially made the realization that if you separate these two phases, you actually gain some benefits.
Those benefits are basically a you don’t have to worry about step synchronous scheduling. So the way that an inference engine works is you do one step and then you finish it, and then you schedule, you start scheduling the next step there. It’s not like fully asynchronous. And the problem with that is you would have, uh, essentially pre-fill and decode are, are actually very different in terms of both their resource requirements and their sometimes their runtime.
So you would have like prefill that would like block decode steps because you, you’d still be pre-filing and you couldn’t schedule because you know the step has to end. So you remove that scheduling issue and then you also allow you, or you yourself, to like [00:40:00] split the work into two different ki types of pools.
So pre-fill typically, and, and this changes as, as model architecture changes. Pre-fill is, right now, compute bound most of the time with the sequence is sufficiently long. It’s compute bound. On the decode side because you’re doing a full Passover, all the weights and the entire sequence, every time you do a decode step and you’re, you don’t have the quadratic computation of KV cache, it’s usually memory bound because you’re retrieving a linear amount of memory and you’re doing a linear amount of compute as opposed to prefill where you retrieve a linear amount of memory and then use a quadratic.
You know,
Nader: it’s funny, someone exo Labs did a really cool demo where for the DGX Spark, which has a lot more compute, you can do the pre the compute hungry prefill on a DG X spark and then do the decode on a, on a Mac. Yeah. And so
Vibhu: that’s faster.
Nader: Yeah. Yeah.
Kyle: So you could, you can do that. You can do machine strat stratification.
Nader: Yeah.
Kyle: And like with our future generation generations of hardware, we actually announced, like with Reuben, this [00:41:00] new accelerator that is prefilled specific. It’s called Reuben, CPX. So
Kubernetes Scaling with Grove
... [Content truncated due to size limits]