AI News for 2/26/2026-2/27/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (263 channels, and 12529 messages) for you. Estimated reading time saved (at 200wpm): 1189 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Against the backdrop of nonstop positioning with the Department of War (Anthropic refusing terms vs OpenAI doing a deal), OpenAI finally closed the much debated Big Round that had been started since December. In the post, they make several interesting new disclosures:
-
Weekly Codex users have more than tripled since the start of the year to 1.6M
- was 1M on Feb 4 (!!?!?!)
-
More than 9 million paying business users rely on ChatGPT for work
-
ChatGPT is where people start with AI, with more than 900M weekly active users, and we now have more than 50 million consumer subscribers (monetization continuing to accelerate in Jan/Feb)
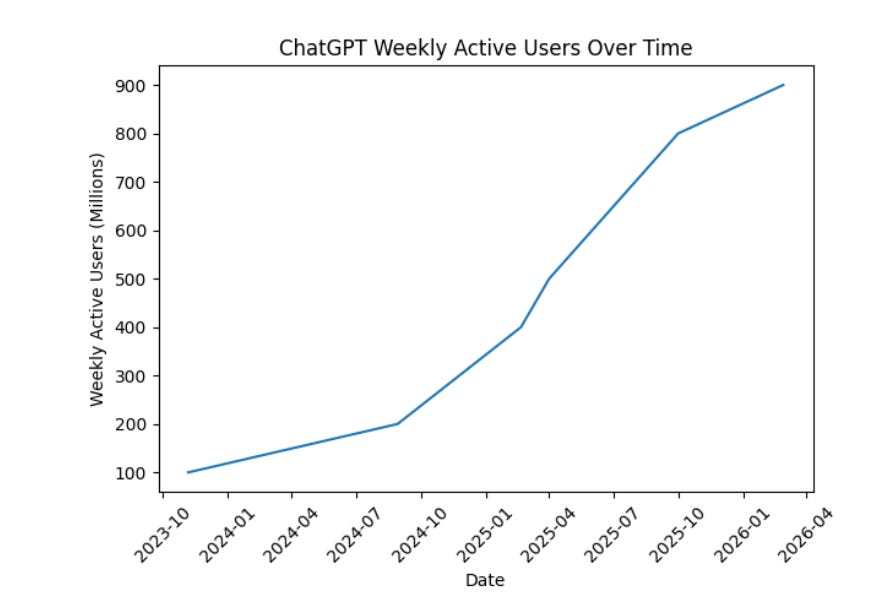
All this justifies $110B in new investment at a $730B pre-money valuation:
-
$30B from SoftBank (“advancing our own ASI strategy”),
-
$30B from NVIDIA (including the use of 3 GW of dedicated inference capacity and 2 GW of training on Vera Rubin systems) - down from “up to $100B”, still with circular funding concerns
-
$50B from Amazon with increased partnership (analysis) involving:
- an initial $15 billion investment and followed by another $35 billion in the coming months when certain conditions are met — leaving Amazon with a large stake in both OpenAI and Anthropic
- “Stateful Runtime Environment” powered by OpenAI on Amazon Bedrock
- AWS will be the exclusive third-party cloud provider for OpenAI Frontier
- 2 gigawatts of Trainium capacity through AWS infrastructure worth “$100 billion over 8 years”, spanning both Trainium3 and next-gen Trainium4 chips
Close watchers might notice the absence of Microsoft, which continues the existing reduced partnership and gets the stateless APIs.
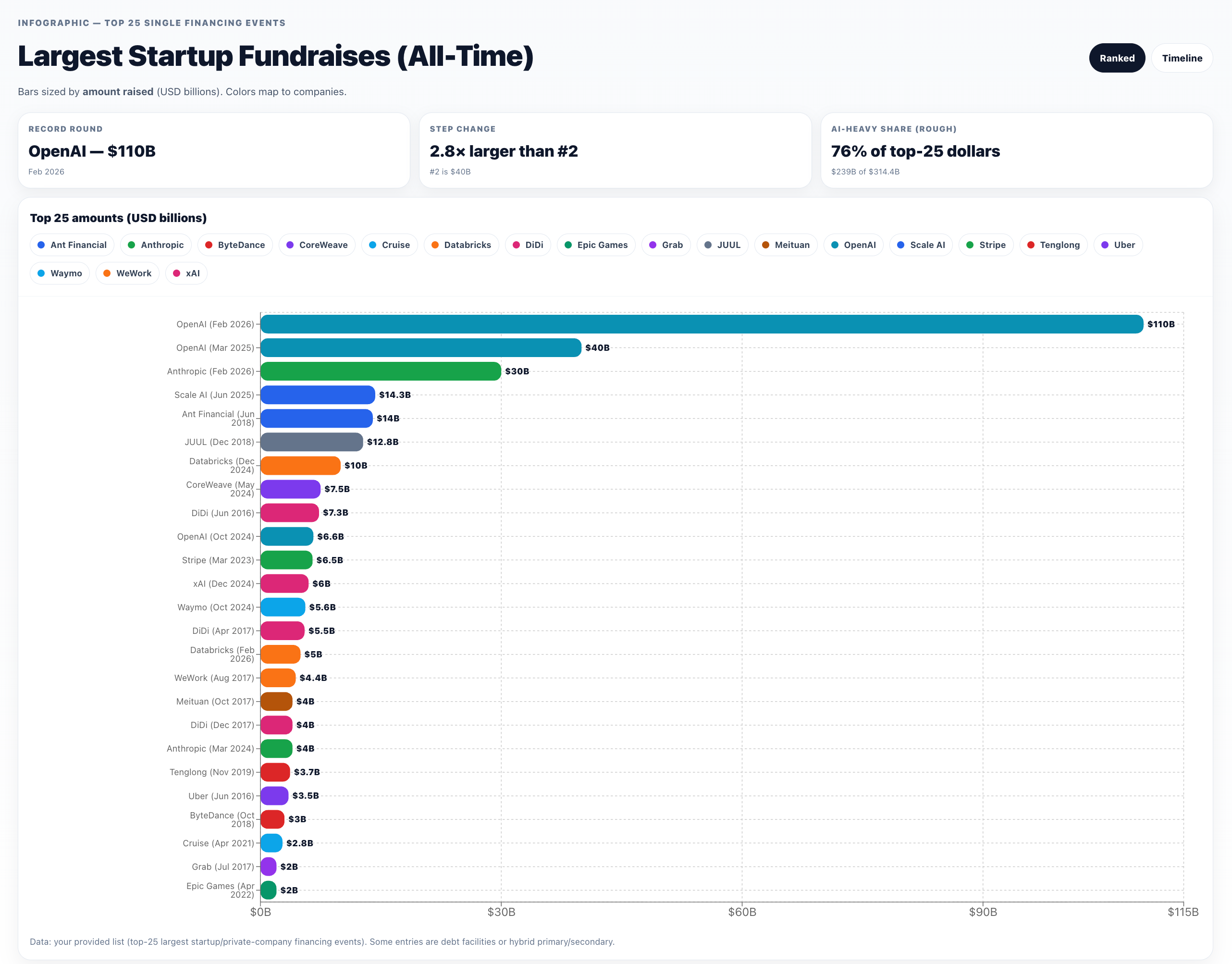
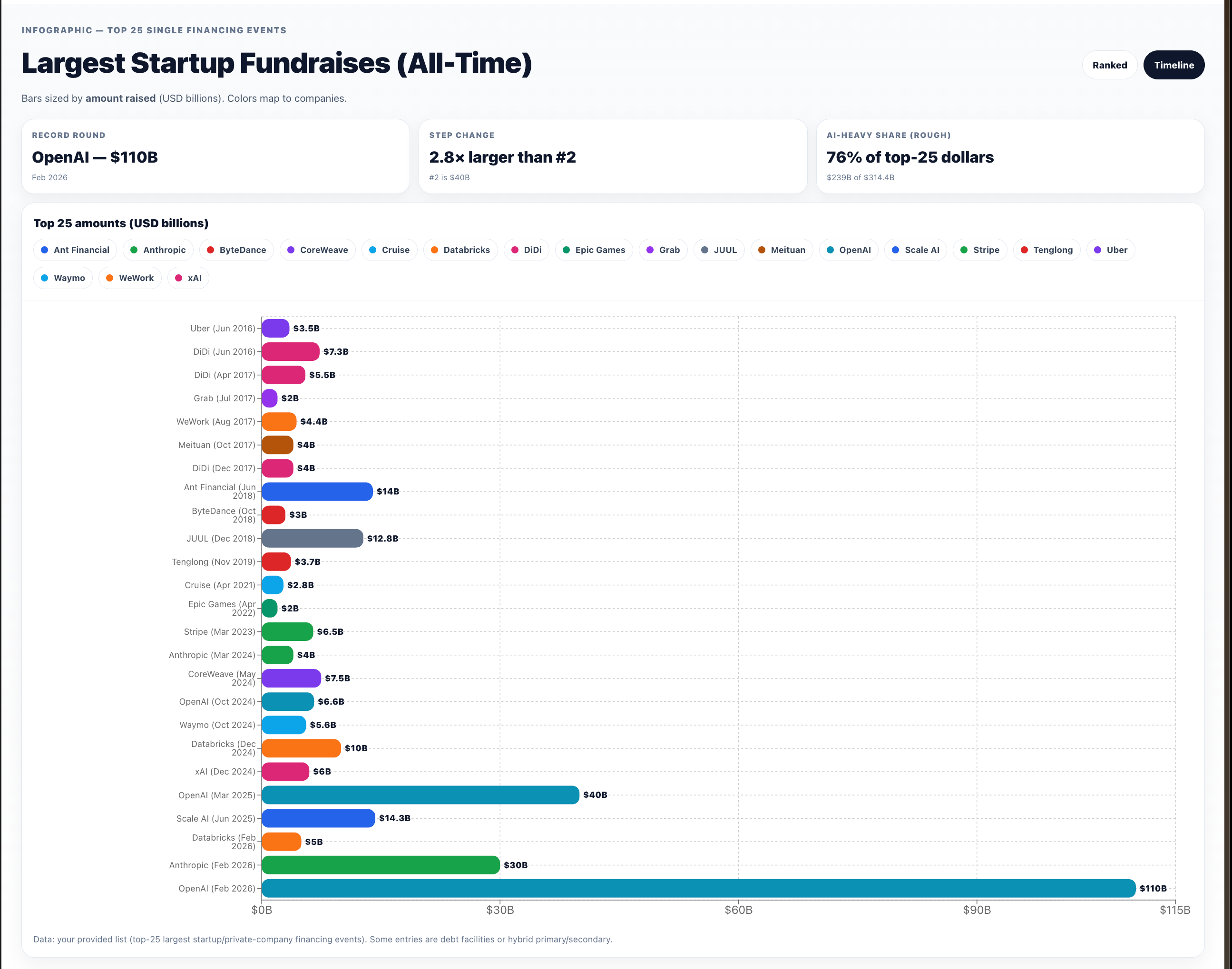
To put this in perspective, 118 countries/economies have a nominal GDP below $100B — roughly 61% of all world economies. Because the consecutive “largest fundraises in history” are too big to fit in a human head, here’s a chart worthy of wtfhappened2025.com:

and outside of AI, a 10 year history:

and here from OpenAI Deep Research + ChatGPT Canvas, sorted by descending amount:
or a timeline perspective:
AI Twitter Recap
Hypernetworks for instant LoRA “compilation”: Doc-to-LoRA + Text-to-LoRA
-
Doc-to-LoRA / Text-to-LoRA (Sakana AI): Sakana introduces two related methods that amortize customization cost by training a hypernetwork to generate LoRA adapters in a single forward pass, turning what would be fine-tuning / distillation / long-context prompting into “instant weight updates.” The core claim: instead of keeping everything in an expensive active context window, you can compile task descriptions or long documents into adapter weights with sub-second latency, enabling rapid adaptation and “durable memory”-like behavior (SakanaAILabs, hardmaru).
- Text-to-LoRA: specializes to unseen tasks from just a natural language description (SakanaAILabs).
- Doc-to-LoRA: internalizes factual documents; on needle-in-a-haystack, reports near-perfect accuracy on sequences ~5× longer than the base model context window, and even demonstrates a cross-modal trick: transferring visual information from a VLM into a text-only model via internalized weights (SakanaAILabs; recap thread omarsar0).
- Positioning vs long-context: explicitly framed as a way to reduce quadratic attention costs and avoid rereading long docs at every call—store knowledge in adapters rather than tokens (omarsar0).
-
Credit / prior art tension: One researcher complains that Hypersteer (hypernetworks producing steering vectors from text descriptions) did not get sufficient credit in later similar work (aryaman2020). There’s also broad community excitement / “hypernetworks are back” reactions (willdepue, zhansheng).
-
Open question raised: why not just use attention with an extremely long KV cache—i.e., is Doc-to-LoRA mainly about efficiency/serving cost? (hyhieu226)
OpenAI financing + deployment transparency tooling
- $110B funding round: OpenAI announces a $110B raise with backing from Amazon, NVIDIA, SoftBank, framed as scaling infra “to bring AI to everyone” (OpenAI, sama). A separate note from Epoch AI contextualizes the scale: The round would nearly triple total capital raised to date; The Information reportedly projects $157B cash burn through 2028, and this round + existing cash would roughly match that projection (EpochAIResearch).
- Deployment Safety Hub: OpenAI launches a searchable site to browse “system cards” (previously PDFs) as a more accessible interface to deployment safety documentation (dgrobinson).
US DoD (“Department of War”) vs Anthropic saga: supply-chain designation, backlash, and industry implications
- Anthropic draws a line; tech reacts: A central flashpoint is Anthropic’s public refusal to enable mass domestic surveillance and fully autonomous weapons (as characterized by posters reacting to Anthropic’s statement), which drew rare cross-competitor praise and heightened attention to “red lines” in frontier deployment (mmitchell_ai, ilyasut).
- Designation shock + legal scope debate: Posts circulate a claimed DoW move to designate Anthropic a “Supply-Chain Risk to National Security” and to pressure contractors/partners—sparking arguments about legality, precedent, and chilling effects (kimmonismus, deanwball). One legal clarification: DoD can restrict what contractors do on DoD contract work, but likely can’t legally ban contractors from using Anthropic in their private/commercial work (petereharrell).
- Economic/strategic fallout framing: The sharpest critiques argue this would damage US credibility as a business partner and potentially force hyperscalers/investors into impossible tradeoffs (deanwball); others note uncertainty until full details are known but still see a supply-chain designation as ill-fitting (jachiam0).
- Public sentiment spike: Posts highlight strong public outrage at the idea of a DoD-backed domestic surveillance program and punishment for refusal (quantian1, janleike). Many users signal “solidarity subscriptions” to Claude (willdepue, Yuchenj_UW).
- Anthropic statement and intent to litigate: Anthropic posts an official statement responding to Secretary Hegseth’s comments (AnthropicAI). Commentary highlights the line “challenge any supply chain risk designation in court” and emphasizes the dispute over restricting customers outside DoD contract scope (iScienceLuvr).
- Meta-point: Regardless of where one lands on Anthropic’s choices, many posts treat this as a governance precedent moment: who decides acceptable use, what due process exists, and how contracts interact with fast-moving model capabilities (kipperrii).
Models + leaderboards: Qwen3.5 expansion and “open model” rankings
- Qwen3.5 new releases (Artificial Analysis summary): Alibaba expands Qwen3.5 with 27B dense, 122B A10B MoE, and 35B A3B MoE, all Apache 2.0, 262K context (extendable to 1M via YaRN per the post). Artificial Analysis reports Intelligence Index scores: 27B = 42, 122B A10B = 42, 35B A3B = 37, with notable agentic/task metrics like GDPval-AA 1205 for 27B, plus detailed tradeoffs (hallucination/accuracy and token usage—27B used 98M output tokens to run the index) (ArtificialAnlys).
- Arena leaderboards (Feb 2026): Arena posts Top Open Models for text and code. Text top-3: GLM-5 (1455), Qwen-3.5 397B A17B (1454), Kimi-K2.5 Thinking (1452) (arena). Code Arena top includes GLM-5 (1451) at #1, with Kimi-K2.5 and MiniMax-M2.5 tied at #2 (arena). Arena also highlights Arena-Rank, their open-source ranking package for reproducible leaderboards (arena).
- Perplexity open-sources bidirectional embedding models (claim): A thread claims Perplexity open-sourced bidirectional “Qwen3-retrained” embedding models (0.6B/4B; standard vs context-aware embeddings; MIT licensed) to improve document-level understanding for retrieval; treat as a third-party summary rather than primary release notes (LiorOnAI).
Systems, inference, kernels, and RL training: bandwidth, ROCm, and off-policy RL
- vLLM ROCm attention backends (AMD): vLLM announces 7 attention backends for vLLM on ROCm with KV-cache layout changes, batching tricks, and model-specific kernels; reported up to 4.4× decode throughput on AMD GPUs with an env var switch (
VLLM_ROCM_USE_AITER=1) (vllm_project). A follow-up details MLA KV compression claims (e.g., ~8K → 576 dims) and throughput wins on MI300X/MI325X/MI355X (vllm_project). - DeepSeek DualPath I/O paper (third-party explainer): A ZhihuFrontier summary describes a DeepSeek+THU+PKU paper proposing system-level redesign of Prefill/Decode to exploit idle storage NIC bandwidth on decode nodes via RDMA, aiming at KV-cache movement bottlenecks for agentic long-context inference; includes claimed speedups (e.g., 1.87× on DS-660B) with caveats for smaller models (ZhihuFrontier).
- Kernel/infra chatter (“quack”, Liger): A thread points to Dao-AILab’s quack writeup on memory hierarchy bandwidth, plus a note that Liger not using cluster-level reductions for xentropy could explain slower performance in some settings (fleetwood___).
- Off-policy RL for reasoning (Databricks MosaicAI): Databricks promotes OAPL (Optimal Advantage-based Policy Optimization with lagged inference policy) as a stable off-policy alternative that can match/beat GRPO while using ~3× fewer training generations, positioned as operationally simpler than strict on-policy loops (DbrxMosaicAI, jefrankle).
- ERL vs RLVR (Turing Post explainer): A long “workflow breakdown” contrasts standard RLVR (scalar verifiable rewards) with Experiential Reinforcement Learning (ERL) inserting within-episode reflection/retry + distillation; cites reported gains (e.g., +81% Sokoban) and tradeoffs (pipeline complexity/compute) (TheTuringPost).
- Mamba-2 / GDN initialization bug discussion: Albert Gu clarifies a viral plot debate: main takeaway is an init bug materially affecting some results; also notes nuanced interactions in hybrids (e.g., “stronger” components can make others “lazy,” with a related reference) (_albertgu, _albertgu).
Top tweets (by engagement, technical / industry-relevant)
- OpenAI raises $110B (sama, OpenAI)
- Sakana AI Doc-to-LoRA / Text-to-LoRA (SakanaAILabs, hardmaru)
- Anthropic–DoD supply-chain designation critique / governance precedent (deanwball, quantian1, janleike)
- Karpathy on coding workflow evolution (tab → agents → parallelism) (karpathy)
- Karpathy on “programming a research org” with multi-agent workflows; limitations observed (karpathy)
- Anthropic official statement (AnthropicAI)