Today's episode is with Paul Klein, founder of Browserbase. We talked about building browser infrastructure for AI agents, the future of agent authentication, and their open source framework Stagehand.
* [00:00:00] Introductions
* [00:04:46] AI-specific challenges in browser infrastructure
* [00:07:05] Multimodality in AI-Powered Browsing
* [00:12:26] Running headless browsers at scale
* [00:18:46] Geolocation when proxying
* [00:21:25] CAPTCHAs and Agent Auth
* [00:28:21] Building “User take over” functionality
* [00:33:43] Stagehand: AI web browsing framework
* [00:38:58] OpenAI's Operator and computer use agents
* [00:44:44] Surprising use cases of Browserbase
* [00:47:18] Future of browser automation and market competition
* [00:53:11] Being a solo founder
Transcript
Alessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.
swyx [00:00:12]: Hey, and today we are very blessed to have our friends, Paul Klein, for the fourth, the fourth, CEO of Browserbase. Welcome.
Paul [00:00:21]: Thanks guys. Yeah, I'm happy to be here. I've been lucky to know both of you for like a couple of years now, I think. So it's just like we're hanging out, you know, with three ginormous microphones in front of our face. It's totally normal hangout.
swyx [00:00:34]: Yeah. We've actually mentioned you on the podcast, I think, more often than any other Solaris tenant. Just because like you're one of the, you know, best performing, I think, LLM tool companies that have started up in the last couple of years.
Paul [00:00:50]: Yeah, I mean, it's been a whirlwind of a year, like Browserbase is actually pretty close to our first birthday. So we are one years old. And going from, you know, starting a company as a solo founder to... To, you know, having a team of 20 people, you know, a series A, but also being able to support hundreds of AI companies that are building AI applications that go out and automate the web. It's just been like, really cool. It's been happening a little too fast. I think like collectively as an AI industry, let's just take a week off together. I took my first vacation actually two weeks ago, and Operator came out on the first day, and then a week later, DeepSeat came out. And I'm like on vacation trying to chill. I'm like, we got to build with this stuff, right? So it's been a breakneck year. But I'm super happy to be here and like talk more about all the stuff we're seeing. And I'd love to hear kind of what you guys are excited about too, and share with it, you know?
swyx [00:01:39]: Where to start? So people, you've done a bunch of podcasts. I think I strongly recommend Jack Bridger's Scaling DevTools, as well as Turner Novak's The Peel. And, you know, I'm sure there's others. So you covered your Twilio story in the past, talked about StreamClub, you got acquired to Mux, and then you left to start Browserbase. So maybe we just start with what is Browserbase? Yeah.
Paul [00:02:02]: Browserbase is the web browser for your AI. We're building headless browser infrastructure, which are browsers that run in a server environment that's accessible to developers via APIs and SDKs. It's really hard to run a web browser in the cloud. You guys are probably running Chrome on your computers, and that's using a lot of resources, right? So if you want to run a web browser or thousands of web browsers, you can't just spin up a bunch of lambdas. You actually need to use a secure containerized environment. You have to scale it up and down. It's a stateful system. And that infrastructure is, like, super painful. And I know that firsthand, because at my last company, StreamClub, I was CTO, and I was building our own internal headless browser infrastructure. That's actually why we sold the company, is because Mux really wanted to buy our headless browser infrastructure that we'd built. And it's just a super hard problem. And I actually told my co-founders, I would never start another company unless it was a browser infrastructure company. And it turns out that's really necessary in the age of AI, when AI can actually go out and interact with websites, click on buttons, fill in forms. You need AI to do all of that work in an actual browser running somewhere on a server. And BrowserBase powers that.
swyx [00:03:08]: While you're talking about it, it occurred to me, not that you're going to be acquired or anything, but it occurred to me that it would be really funny if you became the Nikita Beer of headless browser companies. You just have one trick, and you make browser companies that get acquired.
Paul [00:03:23]: I truly do only have one trick. I'm screwed if it's not for headless browsers. I'm not a Go programmer. You know, I'm in AI grant. You know, browsers is an AI grant. But we were the only company in that AI grant batch that used zero dollars on AI spend. You know, we're purely an infrastructure company. So as much as people want to ask me about reinforcement learning, I might not be the best guy to talk about that. But if you want to ask about headless browser infrastructure at scale, I can talk your ear off. So that's really my area of expertise. And it's a pretty niche thing. Like, nobody has done what we're doing at scale before. So we're happy to be the experts.
swyx [00:03:59]: You do have an AI thing, stagehand. We can talk about the sort of core of browser-based first, and then maybe stagehand. Yeah, stagehand is kind of the web browsing framework. Yeah.
What is Browserbase? Headless Browser Infrastructure Explained
Alessio [00:04:10]: Yeah. Yeah. And maybe how you got to browser-based and what problems you saw. So one of the first things I worked on as a software engineer was integration testing. Sauce Labs was kind of like the main thing at the time. And then we had Selenium, we had Playbrite, we had all these different browser things. But it's always been super hard to do. So obviously you've worked on this before. When you started browser-based, what were the challenges? What were the AI-specific challenges that you saw versus, there's kind of like all the usual running browser at scale in the cloud, which has been a problem for years. What are like the AI unique things that you saw that like traditional purchase just didn't cover? Yeah.
AI-specific challenges in browser infrastructure
Paul [00:04:46]: First and foremost, I think back to like the first thing I did as a developer, like as a kid when I was writing code, I wanted to write code that did stuff for me. You know, I wanted to write code to automate my life. And I do that probably by using curl or beautiful soup to fetch data from a web browser. And I think I still do that now that I'm in the cloud. And the other thing that I think is a huge challenge for me is that you can't just create a web site and parse that data. And we all know that now like, you know, taking HTML and plugging that into an LLM, you can extract insights, you can summarize. So it was very clear that now like dynamic web scraping became very possible with the rise of large language models or a lot easier. And that was like a clear reason why there's been more usage of headless browsers, which are necessary because a lot of modern websites don't expose all of their page content via a simple HTTP request. You know, they actually do require you to run this type of code for a specific time. JavaScript on the page to hydrate this. Airbnb is a great example. You go to airbnb.com. A lot of that content on the page isn't there until after they run the initial hydration. So you can't just scrape it with a curl. You need to have some JavaScript run. And a browser is that JavaScript engine that's going to actually run all those requests on the page. So web data retrieval was definitely one driver of starting BrowserBase and the rise of being able to summarize that within LLM. Also, I was familiar with if I wanted to automate a website, I could write one script and that would work for one website. It was very static and deterministic. But the web is non-deterministic. The web is always changing. And until we had LLMs, there was no way to write scripts that you could write once that would run on any website. That would change with the structure of the website. Click the login button. It could mean something different on many different websites. And LLMs allow us to generate code on the fly to actually control that. So I think that rise of writing the generic automation scripts that can work on many different websites, to me, made it clear that browsers are going to be a lot more useful because now you can automate a lot more things without writing. If you wanted to write a script to book a demo call on 100 websites, previously, you had to write 100 scripts. Now you write one script that uses LLMs to generate that script. That's why we built our web browsing framework, StageHand, which does a lot of that work for you. But those two things, web data collection and then enhanced automation of many different websites, it just felt like big drivers for more browser infrastructure that would be required to power these kinds of features.
Alessio [00:07:05]: And was multimodality also a big thing?
Paul [00:07:08]: Now you can use the LLMs to look, even though the text in the dome might not be as friendly. Maybe my hot take is I was always kind of like, I didn't think vision would be as big of a driver. For UI automation, I felt like, you know, HTML is structured text and large language models are good with structured text. But it's clear that these computer use models are often vision driven, and they've been really pushing things forward. So definitely being multimodal, like rendering the page is required to take a screenshot to give that to a computer use model to take actions on a website. And it's just another win for browser. But I'll be honest, that wasn't what I was thinking early on. I didn't even think that we'd get here so fast with multimodality. I think we're going to have to get back to multimodal and vision models.
swyx [00:07:50]: This is one of those things where I forgot to mention in my intro that I'm an investor in Browserbase. And I remember that when you pitched to me, like a lot of the stuff that we have today, we like wasn't on the original conversation. But I did have my original thesis was something that we've talked about on the podcast before, which is take the GPT store, the custom GPT store, all the every single checkbox and plugin is effectively a startup. And this was the browser one. I think the main hesitation, I think I actually took a while to get back to you. The main hesitation was that there were others. Like you're not the first hit list browser startup. It's not even your first hit list browser startup. There's always a question of like, will you be the category winner in a place where there's a bunch of incumbents, to be honest, that are bigger than you? They're just not targeted at the AI space. They don't have the backing of Nat Friedman. And there's a bunch of like, you're here in Silicon Valley. They're not. I don't know.
Paul [00:08:47]: I don't know if that's, that was it, but like, there was a, yeah, I mean, like, I think I tried all the other ones and I was like, really disappointed. Like my background is from working at great developer tools, companies, and nothing had like the Vercel like experience. Um, like our biggest competitor actually is partly owned by private equity and they just jacked up their prices quite a bit. And the dashboard hasn't changed in five years. And I actually used them at my last company and tried them and I was like, oh man, like there really just needs to be something that's like the experience of these great infrastructure companies, like Stripe, like clerk, like Vercel that I use in love, but oriented towards this kind of like more specific category, which is browser infrastructure, which is really technically complex. Like a lot of stuff can go wrong on the internet when you're running a browser. The internet is very vast. There's a lot of different configurations. Like there's still websites that only work with internet explorer out there. How do you handle that when you're running your own browser infrastructure? These are the problems that we have to think about and solve at BrowserBase. And it's, it's certainly a labor of love, but I built this for me, first and foremost, I know it's super cheesy and everyone says that for like their startups, but it really, truly was for me. If you look at like the talks I've done even before BrowserBase, and I'm just like really excited to try and build a category defining infrastructure company. And it's, it's rare to have a new category of infrastructure exists. We're here in the Chroma offices and like, you know, vector databases is a new category of infrastructure. Is it, is it, I mean, we can, we're in their office, so, you know, we can, we can debate that one later. That is one.
Multimodality in AI-Powered Browsing
swyx [00:10:16]: That's one of the industry debates.
Paul [00:10:17]: I guess we go back to the LLMOS talk that Karpathy gave way long ago. And like the browser box was very clearly there and it seemed like the people who were building in this space also agreed that browsers are a core primitive of infrastructure for the LLMOS that's going to exist in the future. And nobody was building something there that I wanted to use. So I had to go build it myself.
swyx [00:10:38]: Yeah. I mean, exactly that talk that, that honestly, that diagram, every box is a startup and there's the code box and then there's the. The browser box. I think at some point they will start clashing there. There's always the question of the, are you a point solution or are you the sort of all in one? And I think the point solutions tend to win quickly, but then the only ones have a very tight cohesive experience. Yeah. Let's talk about just the hard problems of browser base you have on your website, which is beautiful. Thank you. Was there an agency that you used for that? Yeah. Herb.paris.
Paul [00:11:11]: They're amazing. Herb.paris. Yeah. It's H-E-R-V-E. I highly recommend for developers. Developer tools, founders to work with consumer agencies because they end up building beautiful things and the Parisians know how to build beautiful interfaces. So I got to give prep.
swyx [00:11:24]: And chat apps, apparently are, they are very fast. Oh yeah. The Mistral chat. Yeah. Mistral. Yeah.
Paul [00:11:31]: Late chat.
swyx [00:11:31]: Late chat. And then your videos as well, it was professionally shot, right? The series A video. Yeah.
Alessio [00:11:36]: Nico did the videos. He's amazing. Not the initial video that you shot at the new one. First one was Austin.
Paul [00:11:41]: Another, another video pretty surprised. But yeah, I mean, like, I think when you think about how you talk about your company. You have to think about the way you present yourself. It's, you know, as a developer, you think you evaluate a company based on like the API reliability and the P 95, but a lot of developers say, is the website good? Is the message clear? Do I like trust this founder? I'm building my whole feature on. So I've tried to nail that as well as like the reliability of the infrastructure. You're right. It's very hard. And there's a lot of kind of foot guns that you run into when running headless browsers at scale. Right.
Competing with Existing Headless Browser Solutions
swyx [00:12:10]: So let's pick one. You have eight features here. Seamless integration. Scalability. Fast or speed. Secure. Observable. Stealth. That's interesting. Extensible and developer first. What comes to your mind as like the top two, three hardest ones? Yeah.
Running headless browsers at scale
Paul [00:12:26]: I think just running headless browsers at scale is like the hardest one. And maybe can I nerd out for a second? Is that okay? I heard this is a technical audience, so I'll talk to the other nerds. Whoa. They were listening. Yeah. They're upset. They're ready. The AGI is angry. Okay. So. So how do you run a browser in the cloud? Let's start with that, right? So let's say you're using a popular browser automation framework like Puppeteer, Playwright, and Selenium. Maybe you've written a code, some code locally on your computer that opens up Google. It finds the search bar and then types in, you know, search for Latent Space and hits the search button. That script works great locally. You can see the little browser open up. You want to take that to production. You want to run the script in a cloud environment. So when your laptop is closed, your browser is doing something. The browser is doing something. Well, I, we use Amazon. You can see the little browser open up. You know, the first thing I'd reach for is probably like some sort of serverless infrastructure. I would probably try and deploy on a Lambda. But Chrome itself is too big to run on a Lambda. It's over 250 megabytes. So you can't easily start it on a Lambda. So you maybe have to use something like Lambda layers to squeeze it in there. Maybe use a different Chromium build that's lighter. And you get it on the Lambda. Great. It works. But it runs super slowly. It's because Lambdas are very like resource limited. They only run like with one vCPU. You can run one process at a time. Remember, Chromium is super beefy. It's barely running on my MacBook Air. I'm still downloading it from a pre-run. Yeah, from the test earlier, right? I'm joking. But it's big, you know? So like Lambda, it just won't work really well. Maybe it'll work, but you need something faster. Your users want something faster. Okay. Well, let's put it on a beefier instance. Let's get an EC2 server running. Let's throw Chromium on there. Great. Okay. I can, that works well with one user. But what if I want to run like 10 Chromium instances, one for each of my users? Okay. Well, I might need two EC2 instances. Maybe 10. All of a sudden, you have multiple EC2 instances. This sounds like a problem for Kubernetes and Docker, right? Now, all of a sudden, you're using ECS or EKS, the Kubernetes or container solutions by Amazon. You're spending up and down containers, and you're spending a whole engineer's time on kind of maintaining this stateful distributed system. Those are some of the worst systems to run because when it's a stateful distributed system, it means that you are bound by the connections to that thing. You have to keep the browser open while someone is working with it, right? That's just a painful architecture to run. And there's all this other little gotchas with Chromium, like Chromium, which is the open source version of Chrome, by the way. You have to install all these fonts. You want emojis working in your browsers because your vision model is looking for the emoji. You need to make sure you have the emoji fonts. You need to make sure you have all the right extensions configured, like, oh, do you want ad blocking? How do you configure that? How do you actually record all these browser sessions? Like it's a headless browser. You can't look at it. So you need to have some sort of observability. Maybe you're recording videos and storing those somewhere. It all kind of adds up to be this just giant monster piece of your project when all you wanted to do was run a lot of browsers in production for this little script to go to google.com and search. And when I see a complex distributed system, I see an opportunity to build a great infrastructure company. And we really abstract that away with Browserbase where our customers can use these existing frameworks, Playwright, Publisher, Selenium, or our own stagehand and connect to our browsers in a serverless-like way. And control them, and then just disconnect when they're done. And they don't have to think about the complex distributed system behind all of that. They just get a browser running anywhere, anytime. Really easy to connect to.
swyx [00:15:55]: I'm sure you have questions. My standard question with anything, so essentially you're a serverless browser company, and there's been other serverless things that I'm familiar with in the past, serverless GPUs, serverless website hosting. That's where I come from with Netlify. One question is just like, you promised to spin up thousands of servers. You promised to spin up thousands of browsers in milliseconds. I feel like there's no real solution that does that yet. And I'm just kind of curious how. The only solution I know, which is to kind of keep a kind of warm pool of servers around, which is expensive, but maybe not so expensive because it's just CPUs. So I'm just like, you know. Yeah.
Browsers as a Core Primitive in AI Infrastructure
Paul [00:16:36]: You nailed it, right? I mean, how do you offer a serverless-like experience with something that is clearly not serverless, right? And the answer is, you need to be able to run... We run many browsers on single nodes. We use Kubernetes at browser base. So we have many pods that are being scheduled. We have to predictably schedule them up or down. Yes, thousands of browsers in milliseconds is the best case scenario. If you hit us with 10,000 requests, you may hit a slower cold start, right? So we've done a lot of work on predictive scaling and being able to kind of route stuff to different regions where we have multiple regions of browser base where we have different pools available. You can also pick the region you want to go to based on like lower latency, round trip, time latency. It's very important with these types of things. There's a lot of requests going over the wire. So for us, like having a VM like Firecracker powering everything under the hood allows us to be super nimble and spin things up or down really quickly with strong multi-tenancy. But in the end, this is like the complex infrastructural challenges that we have to kind of deal with at browser base. And we have a lot more stuff on our roadmap to allow customers to have more levers to pull to exchange, do you want really fast browser startup times or do you want really low costs? And if you're willing to be more flexible on that, we may be able to kind of like work better for your use cases.
swyx [00:17:44]: Since you used Firecracker, shouldn't Fargate do that for you or did you have to go lower level than that? We had to go lower level than that.
Paul [00:17:51]: I find this a lot with Fargate customers, which is alarming for Fargate. We used to be a giant Fargate customer. Actually, the first version of browser base was ECS and Fargate. And unfortunately, it's a great product. I think we were actually the largest Fargate customer in our region for a little while. No, what? Yeah, seriously. And unfortunately, it's a great product, but I think if you're an infrastructure company, you actually have to have a deeper level of control over these primitives. I think it's the same thing is true with databases. We've used other database providers and I think-
swyx [00:18:21]: Yeah, serverless Postgres.
Paul [00:18:23]: Shocker. When you're an infrastructure company, you're on the hook if any provider has an outage. And I can't tell my customers like, hey, we went down because so-and-so went down. That's not acceptable. So for us, we've really moved to bringing things internally. It's kind of opposite of what we preach. We tell our customers, don't build this in-house, but then we're like, we build a lot of stuff in-house. But I think it just really depends on what is in the critical path. We try and have deep ownership of that.
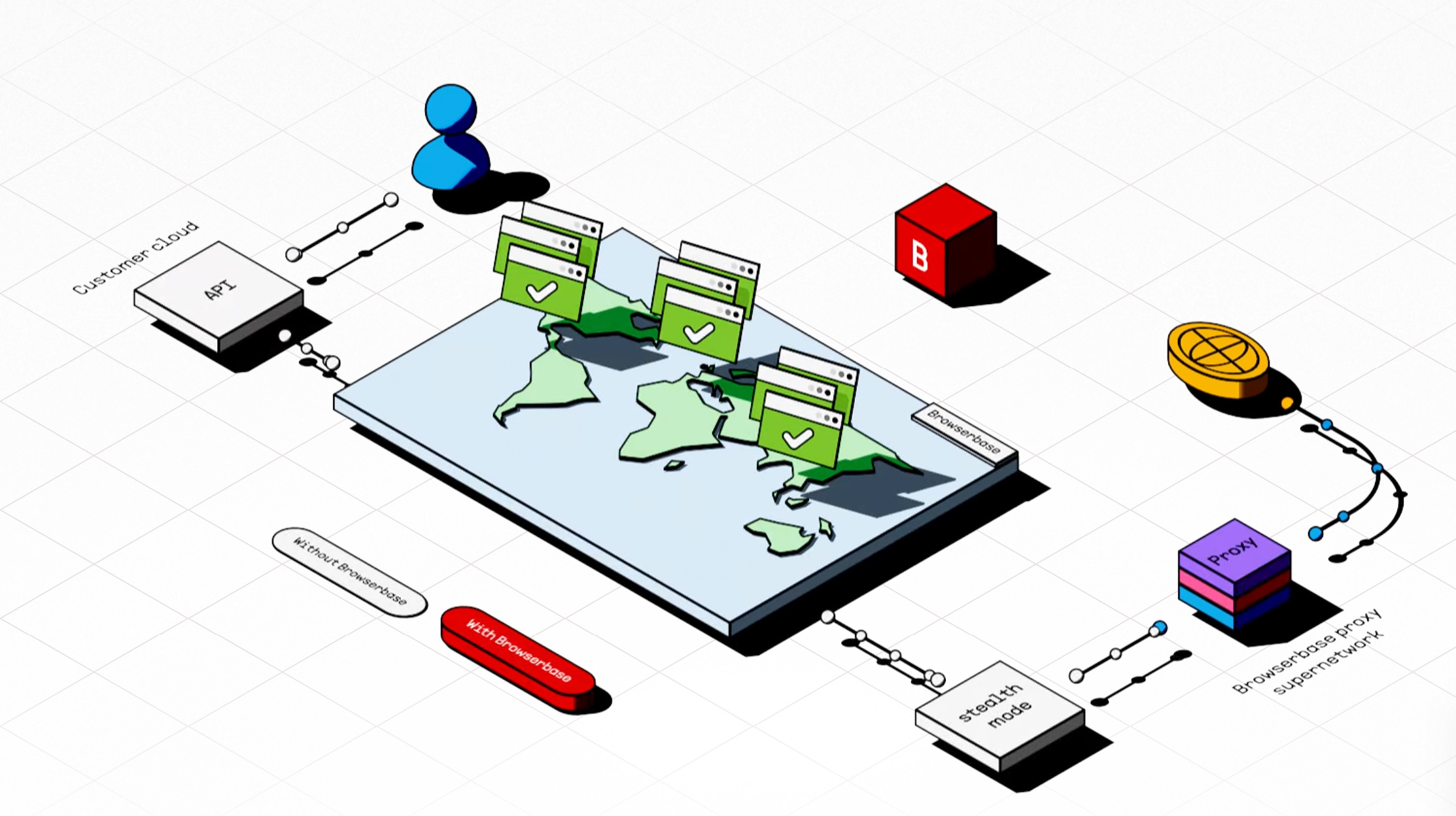
Alessio [00:18:46]: On the distributed location side, how does that work for the web where you might get sort of different content in different locations, but the customer is expecting, you know, if you're in the US, I'm expecting the US version. But if you're spinning up my browser in France, I might get the French version. Yeah.
Paul [00:19:02]: Yeah. That's a good question. Well, generally, like on the localization, there is a thing called locale in the browser. You can set like what your locale is. If you're like in the ENUS browser or not, but some things do IP, IP based routing. And in that case, you may want to have a proxy. Like let's say you're running something in the, in Europe, but you want to make sure you're showing up from the US. You may want to use one of our proxy features so you can turn on proxies to say like, make sure these connections always come from the United States, which is necessary too, because when you're browsing the web, you're coming from like a, you know, data center IP, and that can make things a lot harder to browse web. So we do have kind of like this proxy super network. Yeah. We have a proxy for you based on where you're going, so you can reliably automate the web. But if you get scheduled in Europe, that doesn't happen as much. We try and schedule you as close to, you know, your origin that you're trying to go to. But generally you have control over the regions you can put your browsers in. So you can specify West one or East one or Europe. We only have one region of Europe right now, actually. Yeah.
Alessio [00:19:55]: What's harder, the browser or the proxy? I feel like to me, it feels like actually proxying reliably at scale. It's much harder than spending up browsers at scale. I'm curious. It's all hard.
Paul [00:20:06]: It's layers of hard, right? Yeah. I think it's different levels of hard. I think the thing with the proxy infrastructure is that we work with many different web proxy providers and some are better than others. Some have good days, some have bad days. And our customers who've built browser infrastructure on their own, they have to go and deal with sketchy actors. Like first they figure out their own browser infrastructure and then they got to go buy a proxy. And it's like you can pay in Bitcoin and it just kind of feels a little sus, right? It's like you're buying drugs when you're trying to get a proxy online. We have like deep relationships with these counterparties. We're able to audit them and say, is this proxy being sourced ethically? Like it's not running on someone's TV somewhere. Is it free range? Yeah. Free range organic proxies, right? Right. We do a level of diligence. We're SOC 2. So we have to understand what is going on here. But then we're able to make sure that like we route around proxy providers not working. There's proxy providers who will just, the proxy will stop working all of a sudden. And then if you don't have redundant proxying on your own browsers, that's hard down for you or you may get some serious impacts there. With us, like we intelligently know, hey, this proxy is not working. Let's go to this one. And you can kind of build a network of multiple providers to really guarantee the best uptime for our customers. Yeah. So you don't own any proxies? We don't own any proxies. You're right. The team has been saying who wants to like take home a little proxy server, but not yet. We're not there yet. You know?
swyx [00:21:25]: It's a very mature market. I don't think you should build that yourself. Like you should just be a super customer of them. Yeah. Scraping, I think, is the main use case for that. I guess. Well, that leads us into CAPTCHAs and also off, but let's talk about CAPTCHAs. You had a little spiel that you wanted to talk about CAPTCHA stuff.
Challenges of Scaling Browser Infrastructure
Paul [00:21:43]: Oh, yeah. I was just, I think a lot of people ask, if you're thinking about proxies, you're thinking about CAPTCHAs too. I think it's the same thing. You can go buy CAPTCHA solvers online, but it's the same buying experience. It's some sketchy website, you have to integrate it. It's not fun to buy these things and you can't really trust that the docs are bad. What Browserbase does is we integrate a bunch of different CAPTCHAs. We do some stuff in-house, but generally we just integrate with a bunch of known vendors and continually monitor and maintain these things and say, is this working or not? Can we route around it or not? These are CAPTCHA solvers. CAPTCHA solvers, yeah. Not CAPTCHA providers, CAPTCHA solvers. Yeah, sorry. CAPTCHA solvers. We really try and make sure all of that works for you. I think as a dev, if I'm buying infrastructure, I want it all to work all the time and it's important for us to provide that experience by making sure everything does work and monitoring it on our own. Yeah. Right now, the world of CAPTCHAs is tricky. I think AI agents in particular are very much ahead of the internet infrastructure. CAPTCHAs are designed to block all types of bots, but there are now good bots and bad bots. I think in the future, CAPTCHAs will be able to identify who a good bot is, hopefully via some sort of KYC. For us, we've been very lucky. We have very little to no known abuse of Browserbase because we really look into who we work with. And for certain types of CAPTCHA solving, we only allow them on certain types of plans because we want to make sure that we can know what people are doing, what their use cases are. And that's really allowed us to try and be an arbiter of good bots, which is our long term goal. I want to build great relationships with people like Cloudflare so we can agree, hey, here are these acceptable bots. We'll identify them for you and make sure we flag when they come to your website. This is a good bot, you know?
Alessio [00:23:23]: I see. And Cloudflare said they want to do more of this. So they're going to set by default, if they think you're an AI bot, they're going to reject. I'm curious if you think this is something that is going to be at the browser level or I mean, the DNS level with Cloudflare seems more where it should belong. But I'm curious how you think about it.
Paul [00:23:40]: I think the web's going to change. You know, I think that the Internet as we have it right now is going to change. And we all need to just accept that the cat is out of the bag. And instead of kind of like wishing the Internet was like it was in the 2000s, we can have free content line that wouldn't be scraped. It's just it's not going to happen. And instead, we should think about like, one, how can we change? How can we change the models of, you know, information being published online so people can adequately commercialize it? But two, how do we rebuild applications that expect that AI agents are going to log in on their behalf? Those are the things that are going to allow us to kind of like identify good and bad bots. And I think the team at Clerk has been doing a really good job with this on the authentication side. I actually think that auth is the biggest thing that will prevent agents from accessing stuff, not captchas. And I think there will be agent auth in the future. I don't know if it's going to happen from an individual company, but actually authentication providers that have a, you know, hidden login as agent feature, which will then you put in your email, you'll get a push notification, say like, hey, your browser-based agent wants to log into your Airbnb. You can approve that and then the agent can proceed. That really circumvents the need for captchas or logging in as you and sharing your password. I think agent auth is going to be one way we identify good bots going forward. And I think a lot of this captcha solving stuff is really short-term problems as the internet kind of reorients itself around how it's going to work with agents browsing the web, just like people do. Yeah.
Managing Distributed Browser Locations and Proxies
swyx [00:24:59]: Stitch recently was on Hacker News for talking about agent experience, AX, which is a thing that Netlify is also trying to clone and coin and talk about. And we've talked about this on our previous episodes before in a sense that I actually think that's like maybe the only part of the tech stack that needs to be kind of reinvented for agents. Everything else can stay the same, CLIs, APIs, whatever. But auth, yeah, we need agent auth. And it's mostly like short-lived, like it should not, it should be a distinct, identity from the human, but paired. I almost think like in the same way that every social network should have your main profile and then your alt accounts or your Finsta, it's almost like, you know, every, every human token should be paired with the agent token and the agent token can go and do stuff on behalf of the human token, but not be presumed to be the human. Yeah.
Paul [00:25:48]: It's like, it's, it's actually very similar to OAuth is what I'm thinking. And, you know, Thread from Stitch is an investor, Colin from Clerk, Octaventures, all investors in browser-based because like, I hope they solve this because they'll make browser-based submission more possible. So we don't have to overcome all these hurdles, but I think it will be an OAuth-like flow where an agent will ask to log in as you, you'll approve the scopes. Like it can book an apartment on Airbnb, but it can't like message anybody. And then, you know, the agent will have some sort of like role-based access control within an application. Yeah. I'm excited for that.
swyx [00:26:16]: The tricky part is just, there's one, one layer of delegation here, which is like, you're authoring my user's user or something like that. I don't know if that's tricky or not. Does that make sense? Yeah.
Paul [00:26:25]: You know, actually at Twilio, I worked on the login identity and access. Management teams, right? So like I built Twilio's login page.
swyx [00:26:31]: You were an intern on that team and then you became the lead in two years? Yeah.
Paul [00:26:34]: Yeah. I started as an intern in 2016 and then I was the tech lead of that team. How? That's not normal. I didn't have a life. He's not normal. Look at this guy. I didn't have a girlfriend. I just loved my job. I don't know. I applied to 500 internships for my first job and I got rejected from every single one of them except for Twilio and then eventually Amazon. And they took a shot on me and like, I was getting paid money to write code, which was my dream. Yeah. Yeah. I'm very lucky that like this coding thing worked out because I was going to be doing it regardless. And yeah, I was able to kind of spend a lot of time on a team that was growing at a company that was growing. So it informed a lot of this stuff here. I think these are problems that have been solved with like the SAML protocol with SSO. I think it's a really interesting stuff with like WebAuthn, like these different types of authentication, like schemes that you can use to authenticate people. The tooling is all there. It just needs to be tweaked a little bit to work for agents. And I think the fact that there are companies that are already. Providing authentication as a service really sets it up. Well, the thing that's hard is like reinventing the internet for agents. We don't want to rebuild the internet. That's an impossible task. And I think people often say like, well, we'll have this second layer of APIs built for agents. I'm like, we will for the top use cases, but instead of we can just tweak the internet as is, which is on the authentication side, I think we're going to be the dumb ones going forward. Unfortunately, I think AI is going to be able to do a lot of the tasks that we do online, which means that it will be able to go to websites, click buttons on our behalf and log in on our behalf too. So with this kind of like web agent future happening, I think with some small structural changes, like you said, it feels like it could all slot in really nicely with the existing internet.
Handling CAPTCHAs and Agent Authentication
swyx [00:28:08]: There's one more thing, which is the, your live view iframe, which lets you take, take control. Yeah. Obviously very key for operator now, but like, was, is there anything interesting technically there or that the people like, well, people always want this.
Paul [00:28:21]: It was really hard to build, you know, like, so, okay. Headless browsers, you don't see them, right. They're running. They're running in a cloud somewhere. You can't like look at them. And I just want to really make, it's a weird name. I wish we came up with a better name for this thing, but you can't see them. Right. But customers don't trust AI agents, right. At least the first pass. So what we do with our live view is that, you know, when you use browser base, you can actually embed a live view of the browser running in the cloud for your customer to see it working. And that's what the first reason is the build trust, like, okay, so I have this script. That's going to go automate a website. I can embed it into my web application via an iframe and my customer can watch. I think. And then we added two way communication. So now not only can you watch the browser kind of being operated by AI, if you want to pause and actually click around type within this iframe that's controlling a browser, that's also possible. And this is all thanks to some of the lower level protocol, which is called the Chrome DevTools protocol. It has a API called start screencast, and you can also send mouse clicks and button clicks to a remote browser. And this is all embeddable within iframes. You have a browser within a browser, yo. And then you simulate the screen, the click on the other side. Exactly. And this is really nice often for, like, let's say, a capture that can't be solved. You saw this with Operator, you know, Operator actually uses a different approach. They use VNC. So, you know, you're able to see, like, you're seeing the whole window here. What we're doing is something a little lower level with the Chrome DevTools protocol. It's just PNGs being streamed over the wire. But the same thing is true, right? Like, hey, I'm running a window. Pause. Can you do something in this window? Human. Okay, great. Resume. Like sometimes 2FA tokens. Like if you get that text message, you might need a person to type that in. Web agents need human-in-the-loop type workflows still. You still need a person to interact with the browser. And building a UI to proxy that is kind of hard. You may as well just show them the whole browser and say, hey, can you finish this up for me? And then let the AI proceed on afterwards. Is there a future where I stream my current desktop to browser base? I don't think so. I think we're very much cloud infrastructure. Yeah. You know, but I think a lot of the stuff we're doing, we do want to, like, build tools. Like, you know, we'll talk about the stage and, you know, web agent framework in a second. But, like, there's a case where a lot of people are going desktop first for, you know, consumer use. And I think cloud is doing a lot of this, where I expect to see, you know, MCPs really oriented around the cloud desktop app for a reason, right? Like, I think a lot of these tools are going to run on your computer because it makes... I think it's breaking out. People are putting it on a server. Oh, really? Okay. Well, sweet. We'll see. We'll see that. I was surprised, though, wasn't I? I think that the browser company, too, with Dia Browser, it runs on your machine. You know, it's going to be...
swyx [00:30:50]: What is it?
Paul [00:30:51]: So, Dia Browser, as far as I understand... I used to use Arc. Yeah. I haven't used Arc. But I'm a big fan of the browser company. I think they're doing a lot of cool stuff in consumer. As far as I understand, it's a browser where you have a sidebar where you can, like, chat with it and it can control the local browser on your machine. So, if you imagine, like, what a consumer web agent is, which it lives alongside your browser, I think Google Chrome has Project Marina, I think. I almost call it Project Marinara for some reason. I don't know why. It's...
swyx [00:31:17]: No, I think it's someone really likes the Waterworld. Oh, I see. The classic Kevin Costner. Yeah.
Paul [00:31:22]: Okay. Project Marinara is a similar thing to the Dia Browser, in my mind, as far as I understand it. You have a browser that has an AI interface that will take over your mouse and keyboard and control the browser for you. Great for consumer use cases. But if you're building applications that rely on a browser and it's more part of a greater, like, AI app experience, you probably need something that's more like infrastructure, not a consumer app.
swyx [00:31:44]: Just because I have explored a little bit in this area, do people want branching? So, I have the state. Of whatever my browser's in. And then I want, like, 100 clones of this state. Do people do that? Or...
Paul [00:31:56]: People don't do it currently. Yeah. But it's definitely something we're thinking about. I think the idea of forking a browser is really cool. Technically, kind of hard. We're starting to see this in code execution, where people are, like, forking some, like, code execution, like, processes or forking some tool calls or branching tool calls. Haven't seen it at the browser level yet. But it makes sense. Like, if an AI agent is, like, using a website and it's not sure what path it wants to take to crawl this website. To find the information it's looking for. It would make sense for it to explore both paths in parallel. And that'd be a very, like... A road not taken. Yeah. And hopefully find the right answer. And then say, okay, this was actually the right one. And memorize that. And go there in the future. On the roadmap. For sure. Don't make my roadmap, please. You know?
Alessio [00:32:37]: How do you actually do that? Yeah. How do you fork? I feel like the browser is so stateful for so many things.
swyx [00:32:42]: Serialize the state. Restore the state. I don't know.
Paul [00:32:44]: So, it's one of the reasons why we haven't done it yet. It's hard. You know? Like, to truly fork, it's actually quite difficult. The naive way is to open the same page in a new tab and then, like, hope that it's at the same thing. But if you have a form halfway filled, you may have to, like, take the whole, you know, container. Pause it. All the memory. Duplicate it. Restart it from there. It could be very slow. So, we haven't found a thing. Like, the easy thing to fork is just, like, copy the page object. You know? But I think there needs to be something a little bit more robust there. Yeah.
swyx [00:33:12]: So, MorphLabs has this infinite branch thing. Like, wrote a custom fork of Linux or something that let them save the system state and clone it. MorphLabs, hit me up. I'll be a customer. Yeah. That's the only. I think that's the only way to do it. Yeah. Like, unless Chrome has some special API for you. Yeah.
Paul [00:33:29]: There's probably something we'll reverse engineer one day. I don't know. Yeah.
Alessio [00:33:32]: Let's talk about StageHand, the AI web browsing framework. You have three core components, Observe, Extract, and Act. Pretty clean landing page. What was the idea behind making a framework? Yeah.
Stagehand: AI web browsing framework
Paul [00:33:43]: So, there's three frameworks that are very popular or already exist, right? Puppeteer, Playwright, Selenium. Those are for building hard-coded scripts to control websites. And as soon as I started to play with LLMs plus browsing, I caught myself, you know, code-genning Playwright code to control a website. I would, like, take the DOM. I'd pass it to an LLM. I'd say, can you generate the Playwright code to click the appropriate button here? And it would do that. And I was like, this really should be part of the frameworks themselves. And I became really obsessed with SDKs that take natural language as part of, like, the API input. And that's what StageHand is. StageHand exposes three APIs, and it's a super set of Playwright. So, if you go to a page, you may want to take an action, click on the button, fill in the form, etc. That's what the act command is for. You may want to extract some data. This one takes a natural language, like, extract the winner of the Super Bowl from this page. You can give it a Zod schema, so it returns a structured output. And then maybe you're building an API. You can do an agent loop, and you want to kind of see what actions are possible on this page before taking one. You can do observe. So, you can observe the actions on the page, and it will generate a list of actions. You can guide it, like, give me actions on this page related to buying an item. And you can, like, buy it now, add to cart, view shipping options, and pass that to an LLM, an agent loop, to say, what's the appropriate action given this high-level goal? So, StageHand isn't a web agent. It's a framework for building web agents. And we think that agent loops are actually pretty close to the application layer because every application probably has different goals or different ways it wants to take steps. I don't think I've seen a generic. Maybe you guys are the experts here. I haven't seen, like, a really good AI agent framework here. Everyone kind of has their own special sauce, right? I see a lot of developers building their own agent loops, and they're using tools. And I view StageHand as the browser tool. So, we expose act, extract, observe. Your agent can call these tools. And from that, you don't have to worry about it. You don't have to worry about generating playwright code performantly. You don't have to worry about running it. You can kind of just integrate these three tool calls into your agent loop and reliably automate the web.
swyx [00:35:48]: A special shout-out to Anirudh, who I met at your dinner, who I think listens to the pod. Yeah. Hey, Anirudh.
Paul [00:35:54]: Anirudh's a man. He's a StageHand guy.
swyx [00:35:56]: I mean, the interesting thing about each of these APIs is they're kind of each startup. Like, specifically extract, you know, Firecrawler is extract. There's, like, Expand AI. There's a whole bunch of, like, extract companies. They just focus on extract. I'm curious. Like, I feel like you guys are going to collide at some point. Like, right now, it's friendly. Everyone's in a blue ocean. At some point, it's going to be valuable enough that there's some turf battle here. I don't think you have a dog in a fight. I think you can mock extract to use an external service if they're better at it than you. But it's just an observation that, like, in the same way that I see each option, each checkbox in the side of custom GBTs becoming a startup or each box in the Karpathy chart being a startup. Like, this is also becoming a thing. Yeah.
Paul [00:36:41]: I mean, like, so the way StageHand works is that it's MIT-licensed, completely open source. You bring your own API key to your LLM of choice. You could choose your LLM. We don't make any money off of the extract or really. We only really make money if you choose to run it with our browser. You don't have to. You can actually use your own browser, a local browser. You know, StageHand is completely open source for that reason. And, yeah, like, I think if you're building really complex web scraping workflows, I don't know if StageHand is the tool for you. I think it's really more if you're building an AI agent that needs a few general tools or if it's doing a lot of, like, web automation-intensive work. But if you're building a scraping company, StageHand is not your thing. You probably want something that's going to, like, get HTML content, you know, convert that to Markdown, query it. That's not what StageHand does. StageHand is more about reliability. I think we focus a lot on reliability and less so on cost optimization and speed at this point.
swyx [00:37:33]: I actually feel like StageHand, so the way that StageHand works, it's like, you know, page.act, click on the quick start. Yeah. It's kind of the integration test for the code that you would have to write anyway, like the Puppeteer code that you have to write anyway. And when the page structure changes, because it always does, then this is still the test. This is still the test that I would have to write. Yeah. So it's kind of like a testing framework that doesn't need implementation detail.
Paul [00:37:56]: Well, yeah. I mean, Puppeteer, Playwright, and Slenderman were all designed as testing frameworks, right? Yeah. And now people are, like, hacking them together to automate the web. I would say, and, like, maybe this is, like, me being too specific. But, like, when I write tests, if the page structure changes. Without me knowing, I want that test to fail. So I don't know if, like, AI, like, regenerating that. Like, people are using StageHand for testing. But it's more for, like, usability testing, not, like, testing of, like, does the front end, like, has it changed or not. Okay. But generally where we've seen people, like, really, like, take off is, like, if they're using, you know, something. If they want to build a feature in their application that's kind of like Operator or Deep Research, they're using StageHand to kind of power that tool calling in their own agent loop. Okay. Cool.
swyx [00:38:37]: So let's go into Operator, the first big agent launch of the year from OpenAI. Seems like they have a whole bunch scheduled. You were on break and your phone blew up. What's your just general view of computer use agents is what they're calling it. The overall category before we go into Open Operator, just the overall promise of Operator. I will observe that I tried it once. It was okay. And I never tried it again.
OpenAI's Operator and computer use agents
Paul [00:38:58]: That tracks with my experience, too. Like, I'm a huge fan of the OpenAI team. Like, I think that I do not view Operator as the company. I'm not a company killer for browser base at all. I think it actually shows people what's possible. I think, like, computer use models make a lot of sense. And I'm actually most excited about computer use models is, like, their ability to, like, really take screenshots and reasoning and output steps. I think that using mouse click or mouse coordinates, I've seen that proved to be less reliable than I would like. And I just wonder if that's the right form factor. What we've done with our framework is anchor it to the DOM itself, anchor it to the actual item. So, like, if it's clicking on something, it's clicking on that thing, you know? Like, it's more accurate. No matter where it is. Yeah, exactly. Because it really ties in nicely. And it can handle, like, the whole viewport in one go, whereas, like, Operator can only handle what it sees. Can you hover? Is hovering a thing that you can do? I don't know if we expose it as a tool directly, but I'm sure there's, like, an API for hovering. Like, move mouse to this position. Yeah, yeah, yeah. I think you can trigger hover, like, via, like, the JavaScript on the DOM itself. But, no, I think, like, when we saw computer use, everyone's eyes lit up because they realized, like, wow, like, AI is going to actually automate work for people. And I think seeing that kind of happen from both of the labs, and I'm sure we're going to see more labs launch computer use models, I'm excited to see all the stuff that people build with it. I think that I'd love to see computer use power, like, controlling a browser on browser base. And I think, like, Open Operator, which was, like, our open source version of OpenAI's Operator, was our first take on, like, how can we integrate these models into browser base? And we handle the infrastructure and let the labs do the models. I don't have a sense that Operator will be released as an API. I don't know. Maybe it will. I'm curious to see how well that works because I think it's going to be really hard for a company like OpenAI to do things like support CAPTCHA solving or, like, have proxies. Like, I think it's hard for them structurally. Imagine this New York Times headline, OpenAI CAPTCHA solving. Like, that would be a pretty bad headline, this New York Times headline. Browser base solves CAPTCHAs. No one cares. No one cares. And, like, our investors are bored. Like, we're all okay with this, you know? We're building this company knowing that the CAPTCHA solving is short-lived until we figure out how to authenticate good bots. I think it's really hard for a company like OpenAI, who has this brand that's so, so good, to balance with, like, the icky parts of web automation, which it can be kind of complex to solve. I'm sure OpenAI knows who to call whenever they need you. Yeah, right. I'm sure they'll have a great partnership.
Alessio [00:41:23]: And is Open Operator just, like, a marketing thing for you? Like, how do you think about resource allocation? So, you can spin this up very quickly. And now there's all this, like, open deep research, just open all these things that people are building. We started it, you know. You're the original Open. We're the original Open operator, you know? Is it just, hey, look, this is a demo, but, like, we'll help you build out an actual product for yourself? Like, are you interested in going more of a product route? That's kind of the OpenAI way, right? They started as a model provider and then…
Paul [00:41:53]: Yeah, we're not interested in going the product route yet. I view Open Operator as a model provider. It's a reference project, you know? Let's show people how to build these things using the infrastructure and models that are out there. And that's what it is. It's, like, Open Operator is very simple. It's an agent loop. It says, like, take a high-level goal, break it down into steps, use tool calling to accomplish those steps. It takes screenshots and feeds those screenshots into an LLM with the step to generate the right action. It uses stagehand under the hood to actually execute this action. It doesn't use a computer use model. And it, like, has a nice interface using the live view that we talked about, the iframe, to embed that into an application. So I felt like people on launch day wanted to figure out how to build their own version of this. And we turned that around really quickly to show them. And I hope we do that with other things like deep research. We don't have a deep research launch yet. I think David from AOMNI actually has an amazing open deep research that he launched. It has, like, 10K GitHub stars now. So he's crushing that. But I think if people want to build these features natively into their application, they need good reference projects. And I think Open Operator is a good example of that.
swyx [00:42:52]: I don't know. Actually, I'm actually pretty bullish on API-driven operator. Because that's the only way that you can sort of, like, once it's reliable enough, obviously. And now we're nowhere near. But, like, give it five years. It'll happen, you know. And then you can sort of spin this up and browsers are working in the background and you don't necessarily have to know. And it just is booking restaurants for you, whatever. I can definitely see that future happening. I had this on the landing page here. This might be a slightly out of order. But, you know, you have, like, sort of three use cases for browser base. Open Operator. Or this is the operator sort of use case. It's kind of like the workflow automation use case. And it completes with UiPath in the sort of RPA category. Would you agree with that? Yeah, I would agree with that. And then there's Agents we talked about already. And web scraping, which I imagine would be the bulk of your workload right now, right?
Paul [00:43:40]: No, not at all. I'd say actually, like, the majority is browser automation. We're kind of expensive for web scraping. Like, I think that if you're building a web scraping product, if you need to do occasional web scraping or you have to do web scraping that works every single time, you want to use browser automation. Yeah. You want to use browser-based. But if you're building web scraping workflows, what you should do is have a waterfall. You should have the first request is a curl to the website. See if you can get it without even using a browser. And then the second request may be, like, a scraping-specific API. There's, like, a thousand scraping APIs out there that you can use to try and get data. Scraping B. Scraping B is a great example, right? Yeah. And then, like, if those two don't work, bring out the heavy hitter. Like, browser-based will 100% work, right? It will load the page in a real browser, hydrate it. I see.
swyx [00:44:21]: Because a lot of people don't render to JS.
swyx [00:44:25]: Yeah, exactly.
Paul [00:44:26]: So, I mean, the three big use cases, right? Like, you know, automation, web data collection, and then, you know, if you're building anything agentic that needs, like, a browser tool, you want to use browser-based.
Alessio [00:44:35]: Is there any use case that, like, you were super surprised by that people might not even think about? Oh, yeah. Or is it, yeah, anything that you can share? The long tail is crazy. Yeah.
Surprising use cases of Browserbase
Paul [00:44:44]: One of the case studies on our website that I think is the most interesting is this company called Benny. So, the way that it works is if you're on food stamps in the United States, you can actually get rebates if you buy certain things. Yeah. You buy some vegetables. You submit your receipt to the government. They'll give you a little rebate back. Say, hey, thanks for buying vegetables. It's good for you. That process of submitting that receipt is very painful. And the way Benny works is you use their app to take a photo of your receipt, and then Benny will go submit that receipt for you and then deposit the money into your account. That's actually using no AI at all. It's all, like, hard-coded scripts. They maintain the scripts. They've been doing a great job. And they build this amazing consumer app. But it's an example of, like, all these, like, tedious workflows that people have to do to kind of go about their business. And they're doing it for the sake of their day-to-day lives. And I had never known about, like, food stamp rebates or the complex forms you have to do to fill them. But the world is powered by millions and millions of tedious forms, visas. You know, Emirate Lighthouse is a customer, right? You know, they do the O1 visa. Millions and millions of forms are taking away humans' time. And I hope that Browserbase can help power software that automates away the web forms that we don't need anymore. Yeah.
... [Content truncated due to size limits]