We are in 🗽 NYC this Monday! Join the AI Eng NYC meetup, bring demos and vibes!
It is a bit of a meme that the first thing developer tooling founders think to build in AI is all the non-AI operational stuff outside the AI. There are well over 60 funded LLM Ops startups all with hoping to solve the new observability, cost tracking, security, and reliability problems that come with putting LLMs in production, not to mention new LLM oriented products from incumbent, established ops/o11y players like Datadog and Weights & Biases.
2 years in to the current hype cycle, the early winners have tended to be people with practical/research AI backgrounds rather than MLOps heavyweights or SWE tourists:
* LangSmith: We covered how Harrison Chase worked on AI at Robust Intelligence and Kensho, the alma maters of many great AI founders
* HumanLoop: We covered how Raza Habib worked at Google AI during his PhD
* BrainTrust: Today’s guest Ankur Goyal founded Impira pre-Transformers and was acquihired to run Figma AI before realizing how to solve the Ops problem.
There have been many VC think pieces and market maps describing what people thought were the essential pieces of the AI Engineering stack, but what was true for 2022-2023 has aged poorly. The basic insight that Ankur had is the same thesis that Hamel Husain is pushing in his World’s Fair talk and podcast with Raza and swyx:
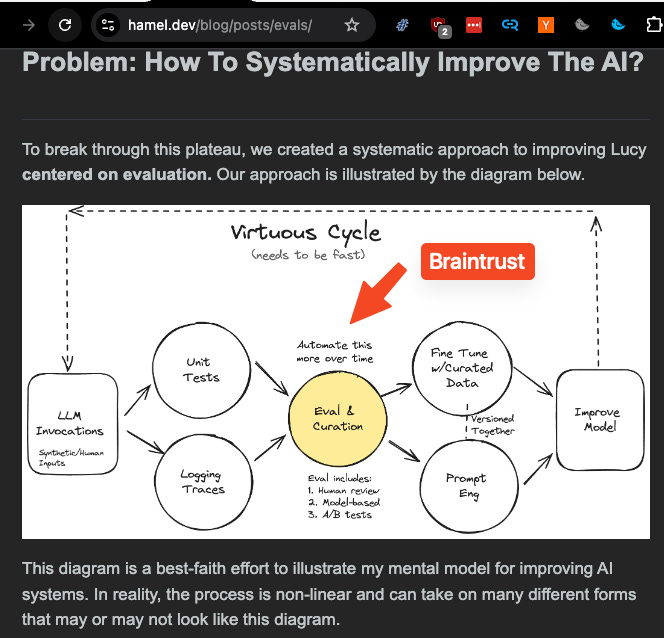
Evals are the centerpiece of systematic AI Engineering.
REALLY believing in this is harder than it looks with the benefit of hindsight. It’s not like people didn’t know evals were important. Basically every LLM Ops feature list has them. It’s an obvious next step AFTER managing your prompts and logging your LLM calls. In fact, up til we met Braintrust, we were working on an expanded version of the Impossible Triangle Theory of the LLM Ops War that we first articulated in the Humanloop writeup:
The single biggest criticism of the Rise of the AI Engineer piece is that we neglected to split out the role of product evals (as opposed to model evals) in the now infamous “API line” chart:
With hindsight, we were very focused on the differentiating 0 to 1 phase that AI Engineers can bring to an existing team of ML engineers. As swyx says on the Day 2 keynote of AI Engineer, 2024 added a whole new set of concerns as AI Engineering grew up:
A closer examination of Hamel’s product-oriented virtuous cycle and this infra-oriented SDLC would have eventually revealed that Evals, even more than logging, was the first point where teams start to get really serious about shipping to production, and therefore a great place to make an entry into the marketplace, which is exactly what Braintrust did.
Also notice what’s NOT on this chart: shifting to shadow open source models, and finetuning them… per Ankur, Fine-tuning is not a viable standalone product:
“The thing I would say is not debatable is whether or not fine-tuning is a business outcome or not. So let's think about the other components of your triangle. Ops/observability, that is a business… Frameworks, evals, databases [are a business, but] Fine-tuning is a very compelling method that achieves an outcome. The outcome is not fine-tuning, it is can I automatically optimize my use case to perform better if I throw data at the problem? And fine-tuning is one of multiple ways to achieve that.”
OpenAI vs Open AI Market Share
We last speculated about the market shifts in the End of OpenAI Hegemony and the Winds of AI Winter, and Ankur’s perspective is super valuable given his customer list:
Some surprises based on what he is seeing:
* Prior to Claude 3, OpenAI had near 100% market share. This tracks with what Harrison told us last year.
* Claude 3.5 Sonnet and also notably Haiku have made serious dents
* Open source model adoption is <5% and DECLINING. Contra to Eugene Cheah’s ideal marketing pitch, virtually none of Braintrust’s customers are really finetuning open source models for cost, control, or privacy. This is partially caused by…
* Open source model hosts, aka Inference providers, aren’t as mature as OpenAI’s API platform. Kudos to Michelle’s team as if they needed any more praise!
* Adoption of Big Lab models via their Big Cloud Partners, aka Claude through AWS, or OpenAI through Azure, is low. Surprising! It seems that there are issues with accessing the latest models via the Cloud partners.
swyx [01:36:51]: What % of your workload is open source?
Ankur Goyal [01:36:55]: Because of how we're deployed, I don't have like an exact number for you. Among customers running in production, it's less than 5%.
Full Video Episode
Check out the Braintrust demo on YouTube! (and like and subscribe etc)
Show Notes
* Ankur’s companies
* MemSQL/SingleStore → now Nikita Shamgunov of Neon
* Impira
* Papers mentioned
* AlexNet
* Ankur and Olmo’s talk at AIEWF
* People
* Elad Gil
* Prior episodes
* HumanLoop episode
Timestamps
* [00:00:00] Introduction and background on Ankur career
* [00:00:49] SingleStore and HTAP databases
* [00:08:19] Founding Impira and lessons learned
* [00:13:33] Unstructured vs Structured Data
* [00:25:41] Overview of Braintrust and its features
* [00:40:42] Industry observations and trends in AI tooling
* [00:58:37] Workload types and AI use cases in production
* [01:06:37] World's Fair AI conference discussion
* [01:11:09] AI infrastructure market landscape
* [01:24:59] OpenAI vs Anthropic vs other model providers
* [01:38:11] GPU inference market discussion
* [01:45:39] Hypothetical AI projects outside of Braintrust
* [01:50:25] Potentially joining OpenAI
* [01:52:37] Insights on effective networking and relationships in tech
Transcript
swyx [00:00:00]: Ankur Goyal, welcome to Latent Space.
Ankur Goyal [00:00:06]: Thanks for having me.
swyx [00:00:07]: Thanks for coming all the way over to our studio.
Ankur Goyal [00:00:10]: It was a long hike.
swyx [00:00:11]: A long trek. Yeah. You got T-boned by traffic. Yeah. You were the first VP of Eng at Signal Store. Yeah. Then you started Impira. You ran it for six years, got acquired into Figma, where you were at for eight months, and you just celebrated your one-year anniversary at Braintrust. I did, yeah. What a journey. I kind of want to go through each in turn because I have a personal relationship with Signal Store just because I have been a follower and fan of databases for a while. HTAP is always a dream of every database guy. It's still the dream. When HTAP, and Signal Store I think is the leading HTAP. Yeah. What's that journey like? And then maybe we'll cover the rest later.
Ankur Goyal [00:00:49]: Sounds good.
swyx [00:00:50]: We can start Signal Store first. Yeah, yeah.
Ankur Goyal [00:00:52]: In college, as a first-generation Indian kid, I basically had two options. I had already told my parents I wasn't going to be a doctor. They're both doctors, so only two options left. Do a PhD or work at a big company. After my sophomore year, I worked at Microsoft, and it just wasn't for me. I realized that the work I was doing was impactful. I was working on Bing and the distributed compute infrastructure at Bing, which is actually now part of Azure. There were hundreds of engineers using the infrastructure that we were working on, but the level of intensity was too low. It felt like you got work-life balance and impact, but very little creativity, very little room to do interesting things. I was like, okay, let me cross that off the list. The only option left is to do research. I did research the next summer, and I realized, again, no one's working that hard. Maybe the times have changed, but at that point, there's a lot of creativity. You're just bouncing around fun ideas and working on stuff and really great work-life balance, but no one would actually use the stuff that we built, and that was not super energizing for me. I had this existential crisis, and I moved out to San Francisco because I had a friend who was here and crashed on his couch and was talking to him and just very, very confused. He said, you should talk to a recruiter, which felt like really weird advice. I'm not even sure I would give that advice to someone nowadays, but I met this really great guy named John, and he introduced me to like 30 different companies. I realized that there's actually a lot of interesting stuff happening in startups, and maybe I could find this kind of company that let me be very creative and work really hard and have a lot of impact, and I don't give a s**t about work-life balance. I talked to all these companies, and I remember I met MemSQL when it was three people and interviewed, and I thought I just totally failed the interview, but I had never had so much fun in my life. I remember I was at 10th and Harrison, and I stood at the bus station, and I called my parents and said, I'm sorry, I'm dropping out of school. I thought I wouldn't get the offer, but I just realized that if there's something like this company, then this is where I need to be. Luckily, things worked out, and I got an offer, and I joined as employee number two, and I worked there for almost six years, and it was an incredible experience. Learned a lot about systems, got to work with amazing customers. There are a lot of things that I took for granted that I later learned at Impira that I had taken for granted, and the most exciting thing is I got to run the engineering team, which was a great opportunity to learn about tech on a larger stage, recruit a lot of great people, and I think, for me personally, set me up to do a lot of interesting things after.
swyx [00:03:41]: Yeah, there's so many ways I can take that. The most curious, I think, for general audiences is, is the dream real of SingleStore? Should, obviously, more people be using it? I think there's a lot of marketing from SingleStore that makes sense, but there's a lot of doubt in people's minds. What do you think you've seen that is the most convincing as to when is it suitable for people to adopt SingleStore and when is it not?
Ankur Goyal [00:04:06]: Bear in mind that I'm now eight years removed from SingleStore, so they've done a lot of stuff since I left, but maybe the meta thing, I would say, or the meta learning for me is that, even if you build the most sophisticated or advanced technology in a particular space, it doesn't mean that it's something that everyone can use. I think one of the trade-offs with SingleStore, specifically, is that you have to be willing to invest in hardware and software cost that achieves the dream. At least, when we were doing it, it was way cheaper than Oracle Exadata or SAP HANA, which were kind of the prevailing alternatives. So, not ultra-expensive, but SingleStore is not the kind of thing that, when you're building a weekend project that will scale to millions, you would just spin up SingleStore and start using. I think it's just expensive. It's packaged in a way that is expensive because the size of the market and the type of customer that's able to drive value almost requires the price to work that way. You can actually see Nikita almost overcompensating for it now with Neon and attacking the market from a different angle.
swyx [00:05:11]: This is Nikita Shamgunov, the actual original founder. Yes. Yeah, yeah, yeah.
Ankur Goyal [00:05:15]: So, now he's doing the opposite. He's built the world's best free tier and is building hyper-inexpensive Postgres. But because the number of people that can use SingleStore is smaller than the number of people that can use free Postgres, yet the amount that they're willing to pay for that use case is higher, SingleStore is packaged in a way that just makes it harder to use. I know I'm not directly answering your question, but for me, that was one of those sort of utopian things. It's the technology analog to, if two people love each other, why can't they be together? SingleStore, in many ways, is the best database technology, and it's the best in a number of ways. But it's just really hard to use. I think Snowflake is going through that right now as well. As someone who works in observability, I dearly miss the variant type that I used to use in Snowflake. It is, without any question, at least in my experience, the best implementation of semi-structured data and sort of solves the problem of storing it very, very efficiently and querying it efficiently, almost as efficiently as if you specified the schema exactly, but giving you total flexibility. So it's just a marvel of engineering, but it's packaged behind Snowflake, which means that the minimum query time is quite high. I have to have a Snowflake enterprise license, right? I can't deploy it on a laptop, I can't deploy it in a customer's premises, or whatever. So you're sort of constrained to the packaging by which one can interface with Snowflake in the first place. And I think every observability product in some sort of platonic ideal would be built on top of Snowflake's variant implementation and have better performance, it would be cheaper, the customer experience would be better. But alas, it's just not economically feasible right now for that to be the case.
swyx [00:07:03]: Do you buy what Honeycomb says about needing to build their own super wide column store?
Ankur Goyal [00:07:09]: I do, given that they can't use Snowflake. If the variant type were exposed in a way that allowed more people to use it, and by the way, I'm just sort of zeroing in on Snowflake in this case. Redshift has something called Super, which is fairly similar. Clickhouse is also working on something similar, and that might actually be the thing that lets more people use it. DuckDB does not. It has a struct type, which is dynamically constructed, but it has all the downsides of traditional structured data types. For example, if you infer a bunch of rows with the struct type, and then you present the n plus first row, and it doesn't have the same schema as the first n rows, then you need to change the schema for all the preceding rows, which is the main problem that the variant type solves. It's possible that on the extreme end, there's something specific to what Honeycomb does that wouldn't directly map to the variant type. And I don't know enough about Honeycomb, and I think they're a fantastic company, so I don't mean to pick on them or anything, but I would just imagine that if one were starting the next Honeycomb, and the variant type were available in a way that they could consume, it might accelerate them dramatically or even be the terminal solution.
swyx [00:08:19]: I think being so early in single store also taught you, among all these engineering lessons, you also learned a lot of business lessons that you took with you into Impira. And Impira, that was your first, maybe, I don't know if it's your exact first experience, but your first AI company.
Ankur Goyal [00:08:35]: Yeah, it was. Tell the story. There's a bunch of things I learned and a bunch of things I didn't learn. The idea behind Impira originally was I saw when AlexNet came out that you were suddenly able to do things with data that you could never do before. And I think I was way too early into this observation. When I started Impira, the idea was what if we make using unstructured data as easy as it is to use structured data? And maybe ML models are the glue that enables that. And I think deep learning presented the opportunity to do that because you could just kind of throw data at the problem. Now in practice, it turns out that pre-LLMs, I think the models were not powerful enough. And more importantly, people didn't have the ability to capture enough data to make them work well enough for a lot of use cases. So it was tough. However, that was the original idea. And I think some of the things I learned were how to work with really great companies. We worked with a number of top financial services companies. We worked with public enterprises. And there's a lot of nuance and sophistication that goes into making that successful. I'll tell you the things I didn't learn though, which I learned the hard way. So one of them is when I was the VP of engineering, I would go into sales meetings and the customer would be super excited to talk to me. And I was like, oh my god, I must be the best salesperson ever. And after I finished the meeting, the sales people would just be like, yeah, okay, you know what, it looks like the technical POC succeeded and we're going to deal with some stuff. It might take some time, but they'll probably be a customer. And then I didn't do anything. And a few weeks later or a few months later, they were a customer.
swyx [00:10:09]: Money shows up. Exactly. And like,
Ankur Goyal [00:10:11]: oh my god, I must have the Midas touch, right? I go into the meeting. I've been that guy. I sort of speak a little bit and they become a customer. I had no idea how hard it was to get people to take meetings with you in the first place. And then once you actually sort of figure that out, the actual mechanics of closing customers at scale, dealing with revenue retention, all this other stuff, it's so freaking hard. I learned a lot about that. I thought it was just an invaluable experience at Empira to sort of experience
swyx [00:10:41]: that myself firsthand. Did you have a main salesperson or a sales advisor?
Ankur Goyal [00:10:45]: Yes, a few different things. One, I lucked into, it turns out, my wife, Alana, who I started dating right as I was starting Empira. Her father, who is just super close now, is a seasoned, very, very seasoned and successful sales leader. So he's currently the president of CloudFlare. At the time, he was the president of Palo Alto Networks, and he joined just right before the IPO and was managing a few billion dollars of revenue at the time. And so I would say I learned a lot from him. I also hired someone named Jason, who I worked with at MemSQL, and he's just an exceptional account executive. So he closed probably like 90 or 95% of our business over our years at Empira. And he's just exceptionally good. I think one of the really fun lessons, we were trying to close a deal with Stitch Fix at Empira early on. It was right around my birthday, and so I was hanging out with my father-in-law and talking to him about it. And he was like, look, you're super smart. Empira sounds really exciting. Everything you're talking about, a mediocre account executive can just do and do much better than what you're saying. If you're dealing with these kinds of problems, you should just find someone who can do this a lot better than you can. And that was one of those, again, very humbling things that you sort of...
swyx [00:11:57]: Like he's telling you to delegate? I think in this case, he's actually saying,
Ankur Goyal [00:12:01]: yeah, you're making a bunch of rookie errors in trying to close a contract that any mediocre or better salesperson will be able to do for you or in partnership with you. That was really interesting to learn. But the biggest thing that I learned, which was, I'd say, very humbling, is that at MemSQL, I worked with customers that were very technical. And I always got along with the customers. I always found myself motivated when they complained about something to solve the problems. And then most importantly, when they complained about something, I could relate to it personally. At Empira, I took kind of the popular advice, which is that developers are in a terrible market. So we sold to line of business. And there are a number of benefits to that. We were able to sell six- or seven-figure deals much more easily than we could at SingleStore or now we can at Braintrust. However, I learned firsthand that if you don't have a very deep, intuitive understanding of your customer, everything becomes harder. You need to throw product managers at the problem. Your own ability to see your customers is much weaker. And depending on who you are, it might actually be very difficult. And for me, it was so difficult that I think it made it challenging for us to one, stay focused on a particular segment, and then two, out-compete or do better than people that maybe had inferior technology that we did, but really deeply understood what the customer needed. I would say if you just asked me what was the main humbling lesson that I faced
swyx [00:13:33]: with it, it was that. I have a question on this market because I think after Impera, there's a cohort of new Imperas coming out. Datalab, I don't
Ankur Goyal [00:13:41]: know if you saw that. I get a phone call about one every week.
swyx [00:13:45]: What have you learned about this unstructured data to structured data market? Everyone thinks now you can just throw an LLM at it. Obviously, it's going to be better than what you had.
Ankur Goyal [00:13:53]: I think the fundamental challenge is not a technology problem. It is the fact that if you're a business, let's say you're the CEO of a company that is in the insurance space and you have a number of inefficient processes that would benefit from unstructured to structured data. You have the opportunity to create a new consumer user experience that totally circumvents the unstructured data and is a much better user experience for the end customer. Maybe it's an iPhone app that does the insurance underwriting survey by having a phone conversation with the user and filling out the form or something instead. The second option potentially unlocked a totally new segment of users and maybe cost you like 10 times as much money. The first segment is this pain. It affects your cogs. It's annoying. There's a solution that works which is throwing people at the problem but it could be a lot better. Which one are you going to prioritize? I think as a technologist, maybe this is the third lesson, you tend to think that if a problem is technically solvable and you can justify the ROI or whatever, then it's worth solving. You also tend to not think about how things are outside of your control. If you empathize with a CEO or a CTO who's sort of considering these two projects, I can tell you straight up, they're going to pick the second project. They're going to prioritize the future. They don't want the unstructured data to exist in the first place. That is the hardest part. It is very hard to motivate an organization to prioritize the problem. You're always going to be a second or third tier priority. There's revenue in that because it does affect people's day-to-day lives. There are some people who care enough to try to solve it. I would say this in very stark contrast to Braintrust where if you look at the logos on our website, almost all of the CEOs or CTOs or founders are daily active users of the product themselves. Every company that has a software product is trying to incorporate AI in a meaningful way. It's so meaningful that literally the exec team is
swyx [00:16:03]: using the product every day. Just to not bury the lead, the logos are Instacart, Stripe, Zapier, Airtable, Notion, Replit, Brex, Versa, Alcota, and the browser company of New York. I don't want to jump the gun to Braintrust. I don't think you've actually told the Impira acquisition story publicly that I can tell. It's on the surface. I think I first met you slightly before the acquisition. I was like, what the hell is Figma acquiring this kind of company? You're not a design tool. Any details you can
Ankur Goyal [00:16:33]: share? I would say the super candid thing that we realized, just for timing context, I probably personally realized this during the summer of 2022 and then the acquisition happened in December of 2022. Just for temporal context, NTT came out in November of 2022. At Impira, I think our primary technical advantage was the fact that if you were extracting data from PDF documents, which ended up being the flavor of unstructured data that we focused on, back then you had to assemble thousands of examples of a particular type of document to get a deep neural network to learn how to extract data from it accurately. We had figured out how to make that really small, maybe two or three examples through a variety of old-school ML techniques and maybe some fancy deep learning stuff. But we had this really cool technology that we were proud of. It was actually primarily computer vision-based because at that time, computer vision was a more mature field. If you think of a document as one-part visual signals and one-part text signals, the visual signals were more readily available to extract information from. What happened is text starting with BERT and then accelerating through and including chat GPT just totally cannibalized that. I remember I was in New York and I was playing with BERT on HuggingFace, which had made it really easy at that point to actually do that. They had this little square in the right-hand panel of a model. I just started copy-pasting documents into a question-answering fine-tune using BERT and seeing whether it could extract the invoice number and this other stuff. I was somewhat mind-boggled by how often it would get it right.
swyx [00:18:25]: That was really scary. Hang on, this is a vision-based BERT? Nope. So this was raw PDF
Ankur Goyal [00:18:31]: parsing? Yep. No, no PDF parsing.
swyx [00:18:33]: Just taking the PDF, command-A,
Ankur Goyal [00:18:35]: copy-paste. So there's no visual signal. By the way, I know we don't want to talk about brain trust yet, but this is also how these technologies were formed because I had a lot of trouble convincing our team that this was real. Part of that naturally, not to anyone's fault, is just the pride that you have in what you've done so far. There's no way something that's not trained or whatever for our use case is going to be as good, which is in many ways true. But part of it is just I had no simple way of proving that it was going to be better. There's no tooling. I could just run something and show I remember on the flight, before the flight, I downloaded the weights and then on the flight when I didn't have internet, I was playing around with a bunch of documents and anecdotally it was like, oh my god, this is amazing. And then that summer we went deep into Layout LM, Microsoft. I personally got super into Hugging Face and I think for two or three months was the top non-employee contributor to Hugging Face, which was a lot of fun. We created the document QA model type and a bunch of stuff. And then we fine-tuned a bunch of stuff and contributed it as well. I love that team. Clem is now an investor in Braintrust, so it started forming that relationship. And I realized, and again, this is all pre-Chat GPT, I realized like, oh my god, this stuff is clearly going to cannibalize all the stuff that we've built. And we quickly retooled Impira’s product to use Layout LM as kind of the base model and in almost all cases we didn't have to use our new but somewhat more complex technology to extract stuff. And then I started playing with GPT-3 and that just totally blew my mind. Again, Layout LM is visual, right? So almost the same exact exercise, like I took the PDF contents, pasted it into Chat GPT, no visual structure, and it just destroyed Layout LM. And I was like, oh my god, what is stable here? And I even remember going through the psychological justification of like, oh, but GPT-3 is expensive and blah, blah, blah, blah, blah.
swyx [00:20:37]: So nobody would call it in quantity, right?
Ankur Goyal [00:20:41]: Yeah, exactly. But as I was doing that, because I had literally just gone through that, I was able to kind of zoom out
swyx [00:20:47]: and be like, you're an idiot.
Ankur Goyal [00:20:49]: And so I realized, wow, okay, this stuff is going to change very, very dramatically. And I looked at our commercial traction, I looked at our exhaustion level, I looked at the team and I thought a lot about what would be best and I thought about all the stuff I'd been talking about, like how much did I personally enjoy working on this problem? Is this the problem that I want to raise more capital and work on with a high degree of integrity for the next 5, 10, 15 years? And I realized the answer was no. And so we started pursuing, we had some inbound interest already, given now Chat GPT, this stuff was starting to pick up. I guess Chat GPT still hadn't come out, but GPT-3 was gaining and there weren't that many AI teams or ML teams at the time. So we also started to get some inbound and I kind of realized like, okay, this is probably a better path. And so we talked to a bunch of companies and ran a process. Ilad was insanely
swyx [00:21:47]: helpful.
Ankur Goyal [00:21:49]: He was an investor in Empira. Yeah, I met him at a pizza shop in 2016 or 2017 and then we went on one of those famous really long walks the next day. We started near Salesforce Tower and we ended in Noe Valley. And Ilad walks at the speed of light. I think it was like 30 or 40, it was crazy. And then he invested. And then I guess we'll talk more about him in a little bit. I was talking to him on the phone pretty much every day through that process. And Figma had a number of positive qualities to it. One is that there was a sense of stability because of the acquisition, Figma's another is the problem... By Adobe?
swyx [00:22:31]: Yeah. Oh, oops.
Ankur Goyal [00:22:33]: The problem domain was not exactly the same as what we were solving, but was actually quite similar in that it is a combination of textual language signal, but it's multimodal. So our team was pretty excited about that problem and had some experience. And then we met the whole team and we just thought these people are great. And that's true, they're great people. And so we felt really excited about working there.
swyx [00:22:57]: But is there a question of, because the company was shut down effectively after, you're basically letting down your customers? Yeah. How does that... I mean, obviously you don't have to cover this, so we can cut this out if it's too comfortable. But I think that's a question that people have when they go through acquisition offers.
Ankur Goyal [00:23:15]: Yeah, yeah. No, I mean, it was hard. It was really hard. I would say that there's two scenarios. There's one where it doesn't seem hard for a founder, and I think in those scenarios, it ends up being much harder for everyone else. And then in the other scenario, it is devastating for the founder. In that scenario, I think it works out to be less devastating for everyone else. And I can tell you, it was extremely devastating. I was very, very sad for
swyx [00:23:45]: three, four months. To be acquired, but also to be shutting down.
Ankur Goyal [00:23:49]: Yeah, I mean, just winding a lot of things down. Winding a lot of things down. I think our customers were very understanding, and we worked with them. To be honest, if we had more traction than we did, then it would have been harder. But there were a lot of document processing solutions. The space is very competitive. And so I think I'm hoping, although I'm not 100% sure about this, but I'm hoping we didn't leave anyone totally out to pasture. And we did very, very generous refunds and worked quite closely with people and wrote code
swyx [00:24:23]: to help them where we could.
Ankur Goyal [00:24:25]: But it's not easy. It's one of those things where I think as an entrepreneur, you sometimes resist making what is clearly the right decision because it feels very uncomfortable. And you have to accept that it's your job to make the right decision. And I would say for me, this is one of N formative experiences where viscerally the gap between what feels like the right decision and what is clearly the right decision, and you have to embrace what is clearly the right decision, and then map back and fix the feelings along the way. And this was definitely one of those cases.
swyx [00:25:03]: Thank you for sharing that. That's something that not many people get to hear. And I'm sure a lot of people are going through that right now, bringing up Clem. He mentions very publicly that he gets so many inbounds acquisition offers. I don't know what you call it. Please buy me offers. And I think people are kind of doing that math in this AI winter that we're somewhat going through. Maybe we'll spend a little bit on Figma. Figma AI. I've watched closely the past two configs. A lot going on. You were only there for eight months. What would you say is interesting going on at Figma, at least from the time that you were there and whatever you see now as an outsider?
Ankur Goyal [00:25:41]: Last year was an interesting time for Figma. One, Figma was going through an acquisition. Two, Figma was trying to think about what is Figma beyond being a design tool. And three, Figma is kind of like Apple, a company that is really optimized around a periodic, annual release cycle rather than something that's continuous. If you look at some of the really early AI adopters, like Notion for example, Notion is shipping stuff constantly. It's a new thing.
swyx [00:26:13]: We were consulted on that. Because Ivan liked World's Fair.
Ankur Goyal [00:26:17]: I'll be there if anyone is there. Hit me up. Very iterative company. Ivan and Simon and a couple others hacked the first versions of Notion AI
swyx [00:26:27]: at a retreat.
Ankur Goyal [00:26:29]: In a hotel room. I think with those three pieces of context in mind, it's a little bit challenging for Figma. Very high product bar. Of the software products that are out there right now, one of, if not the best, just quality product. It's not janky, you sort of rely on it to work type of products. It's quite hard to introduce AI into that. And then the other thing I would just add to that is that visual AI is very new and it's very amorphous. Vectors are very difficult because they're a data inefficient representation. The vector format in something like Figma chews up many, many, many, many, many more tokens than HTML and JSX. So it's a very difficult medium to just sort of throw into an LLM compared to writing problems or coding problems. And so it's not trivial for Figma to release like, oh, this company has blah-blah AI and Acme AI and whatever. It's not super trivial for Figma to do that. I think for me personally, I really enjoyed everyone that I worked with and everyone that I met. I am a creature of shipping. I wake up every morning nowadays to several complaints or questions from people and I just like pounding through stuff and shipping stuff and making people happy and iterating with them. And it was just literally challenging for me to do that in that environment. That's why it ended up not being the best fit for me personally. But I think it's going to be interesting what they do. Within the framework that they're designed to, as a company, to ship stuff when they do sort of make that big leap, I think it could be very compelling.
swyx [00:28:11]: I think there's a lot of value in being the chosen tool for an industry because then you just get a lot of community patience for figuring stuff out. The unique problem that Figma has is it caters to designers who hate AI right now. When you mention AI, they're like, oh, I'm going to...
Ankur Goyal [00:28:27]: The thing is, in my limited experience and working with designers myself, I think designers do not want AI to design things for them. But there's a lot of things that aren't in the traditional designer toolkit that AI can solve. And I think the biggest one is generating code. So in my mind, there's this very interesting convergence happening between UI engineering and design. And I think Figma can play an incredibly important part in that transformation which, rather than being threatening, is empowering to designers and probably helps designers contribute and collaborate with engineers more effectively, which is a little bit different than the focus around actually designing things in the editor.
swyx [00:29:09]: Yeah, I think everyone's keen on that. Dev mode was, I think, the first segue into that. So we're going to go into Braintrust now, about 20-something minutes into the podcast. So what was your idea for Braintrust? Tell the full origin story.
Ankur Goyal [00:29:23]: At Impira, while we were having an existential revelation, if you will, we realized that the debates we were having about what model and this and that were really hard to actually prove anything with. So we argued for like two or three months and then prototyped an eval system on top of Snowflake and some scripts, and then shipped the new model like two weeks later. And it wasn't perfect. There were a bunch of things that were less good than what we had before, but in aggregate, it was just way better. And that was a holy s**t moment for me. I kind of realized there's this, sometimes in engineering organizations or maybe organizations more generally, there are what feel like irrational bottlenecks. It's like, why are we doing this? Why are we talking about this? Whatever. This was one of those obvious irrational bottlenecks.
swyx [00:30:13]: Can you articulate the bottleneck again? Was it simply
Ankur Goyal [00:30:17]: evals? Yeah, the bottleneck is there's approach A, and it has these trade-offs. And approach B has these other trade-offs. Which approach should we use? And if people don't very clearly align on one of the two approaches, then you end up going in circles. This approach, hey, check out this example. It's better at this example. Or, I was able to achieve it with this document, but it doesn't work with all of our customer cases, right? And so you end up going in circles. If you introduce evals into the mix, then you sort of change the discussion from being hypothetical or one example and another example into being something that's extremely straightforward and almost scientific. Like, okay, great. Let's get an initial estimate of how good LayoutLM is compared to our hand-built computer vision model. Oh, it looks like there are these 10 cases, invoices that we've never been able to process that now we can suddenly process, but we regress ourselves on these three. Let's think about how to engineer a solution to actually improve these three, and then measure it for you. And so it gives you a framework to have that. And I think, aside from the fact that it literally lets you run the sort of scientific process of improving an AI application, organizationally, it gives you a clear set of tools, I think, to get people to agree. And I think in the absence of evals, what I saw at Empira, and I see with almost all of our customers before they start using BrainTrust, is this kind of stalemate between people on which prompt to use or which model to use or which technique to use, that once you embrace engineering around evals, it just
swyx [00:31:51]: goes away. Yeah. We just did an episode with Hamil Hussain here, and the cynic in that statement would be like, this is not new. All ML engineering deploying models to production always involves evals. Yeah. You discovered it, and you built your own solution, but everyone in the industry has their own solution. Why the conviction that there's a company here?
Ankur Goyal [00:32:13]: I think the fundamental thing is, prior to BERT, I was, as a traditional software engineer, incapable of participating in what happens behind the scenes in ML development. Ignore the CEO or founder title, just imagine I'm a software engineer who's very empathetic about the product. All of my information about what's going to work and what's not going to work is communicated through the black box of interpretation by ML people. So I'm told that this thing is better than that thing, or it'll take us three months to improve this other thing. What is incredibly empowering about these, I would just maybe say that the quality that transformers bring to the table, and even BERT does this, but GPT 3 and then 4 very emphatically do it, is that software engineers can now participate in this discussion. But all the tools that ML people have built over the years to help them navigate evals and data generally are very hard to use for software engineers. I remember when I was first acclimating to this problem, I had to learn how to use Hugging Face and Weights and Biases. And my friend Yanda was at Weights and Biases at the time, and I was talking to him about this, and he was like, yeah, well, prior to Weights and Biases, all data scientists had was software engineering tools, and it felt really uncomfortable to them. And Weights and Biases brought software engineering to them. And then I think the opposite happened. For software engineers, it's just really hard to use these tools. And so I was having this really difficult time wrapping my head around what seemingly simple stuff is. And last summer, I was talking to a lot about this, and I think primarily just venting about it. And he was like, well, you're not the only software engineer who's starting to work on AI now. And that is when we realized that the real gap is that software engineers who have a particular way of thinking, a particular set of biases, a particular type of workflow that they run, are going to be the ones who are doing AI engineering, and that the tools that were built for ML are fantastic in terms of the scientific inspiration, the metrics they track, the level of quality that they inspire, but they're just not usable for software engineers. And that's really where the opportunity is.
swyx [00:34:35]: I was talking with Sarah Guo at the same time, and that led to the rise of the AI engineer and everything that I've done. So very much similar philosophy there. I think it's just interesting that software engineering and ML engineering should not be that different. It's still engineering at the same... You're still making computers boop. Why?
Ankur Goyal [00:34:53]: Well, I mean, there's a bunch of dualities to this. There's the world of continuous mathematics and discrete mathematics. I think ML people think like continuous mathematicians and software engineers, like myself, who are obsessed with algebra. We like to think in terms of discrete math. What I often talk to people about is, I feel like there are people for whom NumPy is incredibly intuitive, and there are people for whom it is incredibly non-intuitive. For me, it is incredibly non-intuitive. I was actually talking to Hamel the other day. He was talking about how there's an eval tool that he likes, and I should check it out. And I was like, this thing, what? Are you freaking kidding me? It's terrible. Yeah, but it has data frames. I was like, yes, exactly. You don't like data frames? I don't like data frames. It's super hard for me to think about manipulating data frames and extracting a column or a row out of data frames. And by the way, this is someone who's worked on databases for more than a decade. It's just very, very programmer-wise. It's very non-ergonomic for me to manipulate a data frame.
swyx [00:35:55]: And what's your preference then?
Ankur Goyal [00:35:57]: For loops.
swyx [00:35:59]: Okay. Well, maybe you should capture a statement of what is BrainTrust today because there's a little bit of the origin story. And you've had a journey over the past year, and obviously now with Series A, which will, like, woohoo, congrats. Put a little intro for the Series A stuff. What is BrainTrust today?
Ankur Goyal [00:36:15]: BrainTrust is an end-to-end developer platform for building AI products. And I would say our core belief is that if you embrace evaluation as the sort of core workflow in AI engineering, meaning every time you make a change, you evaluate it, and you use that to drive the next set of changes that you make, then you're able to build much, much better AI software. That's kind of our core thesis. And we started probably as no surprise by building, I would say, by far the world's best evaluation product, especially for software engineers and now for product managers and others. I think there's a lot of data scientists now who like BrainTrust, but I would say early on, a lot of, like, ML and data science people hated BrainTrust. It felt, like, really weird to them. Things have changed a little bit, but really, like, making evals something that software engineers, product managers can immediately do, I think that's where we started. And now people have pulled us into doing more. So the first thing that people said is, like, okay, great, I can do evals. How do I get the data to do evals? And so what we realized, anyone who's spent some time in evals knows that one of the biggest pain points is ETLing data from your logs into a dataset format that you can use to do evals. And so what we realized is, okay, great, when you're doing evals, you have to instrument your code to capture information about what's happening and then render the eval. What if we just capture that information while you're actually running your application? There's a few benefits to that. One, it's in the same familiar trace and span format that you use for evals. But the other thing is that you've almost accidentally solved the ETL problem. And so if you structure your code so that the same function abstraction that you define to evaluate on equals the abstraction that you actually use to run your application, then when you log your application itself, you actually log it in exactly the right format to do evals. And that turned out to be a killer feature in Braintrust. You can just turn on logging, and now you have an instant flywheel of data that you can collect in datasets and use for evals. And what's cool is that customers, they might start using us for evals, and then they just reuse all the work that they did, and they flip a switch, and boom, they have logs. Or they start using us for logging, and then they flip a switch, and boom, they have data that they can use and the code already written to do evals. The other thing that we realized is that Braintrust went from being kind of a dashboard into being more of a debugger, and now it's turning into kind of an IDE. And by that I mean, at first you ran an eval, and you'd look at our web UI and sort of see a chart or something that tells you how your eval did. But then you wanted to interrogate that and say, okay, great, 8% better. Is that 8% better on everything, or is that 15% better and 7% worse? And where it's 7% worse, what are the cases that regressed? How do I look at the individual cases? They might be worse on this metric. Are they better on that metric? What are the cases that differ? Let me dig in detail. And that sort of turned us into a debugger. And then people said, okay, great, now I want to take action on that. I want to save the prompt or change the model and then click a button and try it again. And that's kind of pulled us into building this very, very souped-up playground. And we started by calling it the Playground, and it started as my wish list of things that annoyed me about the OpenAI Playground. First and foremost, it's durable. So every time you type something, it just immediately saves it. If you lose the browser or whatever, it's all saved. You can share it, and it's collaborative, kind of like Google Docs, Notion, Figma, etc. And so you can work on it with colleagues in real time, and that's a lot of fun. It lets you compare multiple prompts and models side-by-side with data. And now you can actually run evals in the Playground. You can save the prompts that you create in the Playground and deploy them into your code base. And so it's become very, very advanced. And I remember actually, we had an intro call with Brex last year, who's now a customer. And one of the engineers on the call said, he saw the Playground and he said, I want this to be my IDE. It's not there yet. Here's a list of 20 complaints, but I want this to be my IDE. I remember when he told me that, I had this very strong reaction, like, what the F? We're building an eval observability thing, we're not building an IDE. But I think he turned out to be right, and that's a lot of what we've done over the past few months and what we're looking to in the future.
swyx [00:40:42]: How literally can you take it? Can you fork VS Code? It's not off the table.
Ankur Goyal [00:40:48]: We're friends with the cursor people and now part of the same portfolio. And sometimes people say, AI and engineering, are you cursor? Are you competitive? And what I think is like, cursor is taking AI and making traditional software engineering insanely good with AI. And we're taking some of the best things about traditional software engineering and bringing them to building AI software. And so, we're almost like yin and yang in some ways with development. But forking VS Code and doing crazy stuff is not off the table. It's all ideas that we're cooking at this point.
swyx [00:41:27]: Interesting. I think that when people say analogies, they should often take it to the extreme and see what that generates in terms of ideas. And when people say IDE, literally go there. Because I think a lot of people treat their playground and they say figuratively IDE, they don't mean it. And they should. They should mean it.
Ankur Goyal [00:41:45]: So, we've had this playground in the product for a while. And the TLDR of it is that it lets you test prompts. They could be prompts that you save in Braintrust or prompts that you just type on the fly against a bunch of different models or your own fine-tuned models. And you can hook them into the datasets that you create in Braintrust to do your evals. So, I've just pulled this press-release dataset. And this is actually one of the first features we built. It's really easy to run stuff. And by the way, we're trying to see if we can build a prompt that summarizes the document well. But what's kind of happened over time is that people have pulled us to make this prompt playground more and more powerful. So, I kind of like to think of Braintrust as two ends of the spectrum. If you're writing code, you can create evals with infinite complexity. You don't even have to use large language models. You can use any models you want. You can write any scoring functions you want. And you can do that in the most complicated code bases in the world. And then we have this playground that dramatically simplifies things. It's so easy to use that non-technical people love to use it. Technical people enjoy using it as well. And we're sort of converging these things over time. So, one of the first things people asked about is if they could run evals in the playground. And we've supported running pre-built evals for a while. But we actually just added support for creating your own evals in the playground. And I'm going to show you some cool stuff. So, we'll start by adding this summary quality thing. And if we look at the definition of it, it's just a prompt that maps to a few different choices. And each one has a score. We can try it out and make sure that it works. And then, let's run it. So, now you can run not just the model itself, but also the summary quality score and see that it's not great. So, we have some room to improve it. The next thing you can do is let's try to tweak this prompt. So, let's say like in one to two lines. And let's run it again.
swyx [00:43:49]: One thing I noticed about the... you're using an LLM as a judge here. That prompt about one to two lines should actually go into the judge input. It is. Oh, okay. Was that it? Oh, this was generated?
Ankur Goyal [00:44:07]: No, no, no. This is how...
swyx [00:44:09]: I pre-wrote this ahead of time. So, you're matching up the prompt to the eval that you already knew.
Ankur Goyal [00:44:15]: Exactly. So, the idea is like it's useful to write the eval before you actually tweak the prompt so that you can measure the impact of the tweak. So, you can see that the impact is pretty clear, right? It goes from 54% to 100% now. This is a little bit of a toy example, but you kind of get the point. Now, here's an interesting case. If you look at this one, there's something that's obviously wrong with this. What is wrong with this new summary?
swyx [00:44:41]: It has an intro.
Ankur Goyal [00:44:43]: Yeah, exactly. So, let's actually add another evaluator. And this one is Python code. It's not a prompt. And it's very simple. It's just checking if the word sentence is here. And this is a really unique thing. As far as I know, we're the only product that does this. But this Python code is running in a sandbox. It's totally dynamic. So, for example, if we change this, it'll put the Boolean. Obviously, we don't want to save that. We can also try running it here. And so, it's really easy for you to... It's really easy for you to actually go and tweak stuff and play with it and create more interesting scores. So, let's save this. And then we'll run with this one as well. Awesome. And then let's try again. So, now let's say, just include summary. Anything else?
Ankur Goyal [00:45:47]: Amazing. So, the last thing I'll show you, and this is a little bit of an allude to what's next, is that the Playground experience is really powerful for doing this interactive editing. But we're already running at the limits of how much information we can see about the scores themselves and how much information is fitting here. And we actually have a great user experience that, until recently, you could only access by writing an eval in your code. But now you can actually go in here and kick off full brain trust experiments from the Playground. So, in addition to this, we'll actually add one more. We'll add the embedding similarity score. And we'll say, original summarizer,
swyx [00:46:31]: short
Ankur Goyal [00:46:33]: summary, and no sentence
swyx [00:46:37]: wording.
Ankur Goyal [00:46:39]: And then to create... And this is actually going to kick off full experiments.
swyx [00:46:43]: So,
Ankur Goyal [00:46:45]: if we go into one of these things,
Ankur Goyal [00:46:51]: now we're in the full brain trust UI. And one of the really cool things is that you can actually now not just compare one experiment, but compare multiple experiments. And so you can actually look at all of these experiments together and understand, like, okay, good. I did this thing which said, like, please keep it to one to two sentences. Looks like it improved the summary quality and sentence checker, of course, but it looks like it actually also did better on the similarity score, which is my main score to track how well the summary compares to a reference summary. And you can go in here and then very granularly look at the diff between two different versions of the summary and do this whole experience. So, this is something that we actually just shipped a couple weeks ago. And it's already really powerful. But what I wanted to show you is kind of what, like, even the next version or next iteration of this is. And by the time the podcast airs, what I'm about to show you will be live. So, we're almost done shipping it. But before I do that, any questions on this stuff? No, this is
swyx [00:47:53]: a really good demo. Okay, cool. So,
Ankur Goyal [00:47:55]: as soon as we showed people this kind of stuff, they said, well, you know, this is great, and I wish I could do everything with this experience, right? Like, imagine you could, like, create an agent or do rag, like, more interesting stuff with this kind of interactivity. And so, we were like, huh, it looks like we built support for you to do, you know, to run code. And it looks like we know how to actually run your prompts. I wonder if we can do something more interesting. So, we just added support for you to actually define your own tools. I'll sort of shell two different tool options for you. So, one is Browserbase, and the other is Exa. I think these are both really cool companies. And here, we're just writing, like, really simple TypeScript code that wraps the Browserbase API and then, similarly, really simple TypeScript code that wraps the Exa API. And then we give it a type definition. This will get used as a, um, as the schema for a tool call. And then we give it a little bit of metadata so Braintrust knows, you know, where to store it and what to name it and stuff. And then you just run a really simple command, npx braintrust push, and then you give it these files, and it will bundle up all the dependencies and push it into Braintrust. And now you can actually access these things from Braintrust. So, if we go to the search tool, we could say, you know, what is the tallest mountain...
swyx [00:49:19]: Oops. ... ... ...
Ankur Goyal [00:49:27]: And it'll actually run search by Exa. So, what I'm very excited to show you is that now you can actually do this stuff in the Playground, too. So, if we go to the Playground, um, let's try playing with this. So, uh, we'll create a new session.
swyx [00:49:45]: ... ... ... ...
Ankur Goyal [00:49:53]: And let's create a dataset.
swyx [00:49:57]: ... ...
Ankur Goyal [00:50:01]: Let's put one row in here, and we'll say,
swyx [00:50:03]: um,
... [Content truncated due to size limits]