We are excited to be the first podcast in the world to release an in-depth interview on the new SOTA in commercially licensed open source models - MosiacML MPT-7B!
The Latent Space crew will be at the NYC Lux AI Summit next week, and have two meetups in June. As usual, all events are on the Community page! We are also inviting beta testers for the upcoming AI for Engineers course. See you soon!
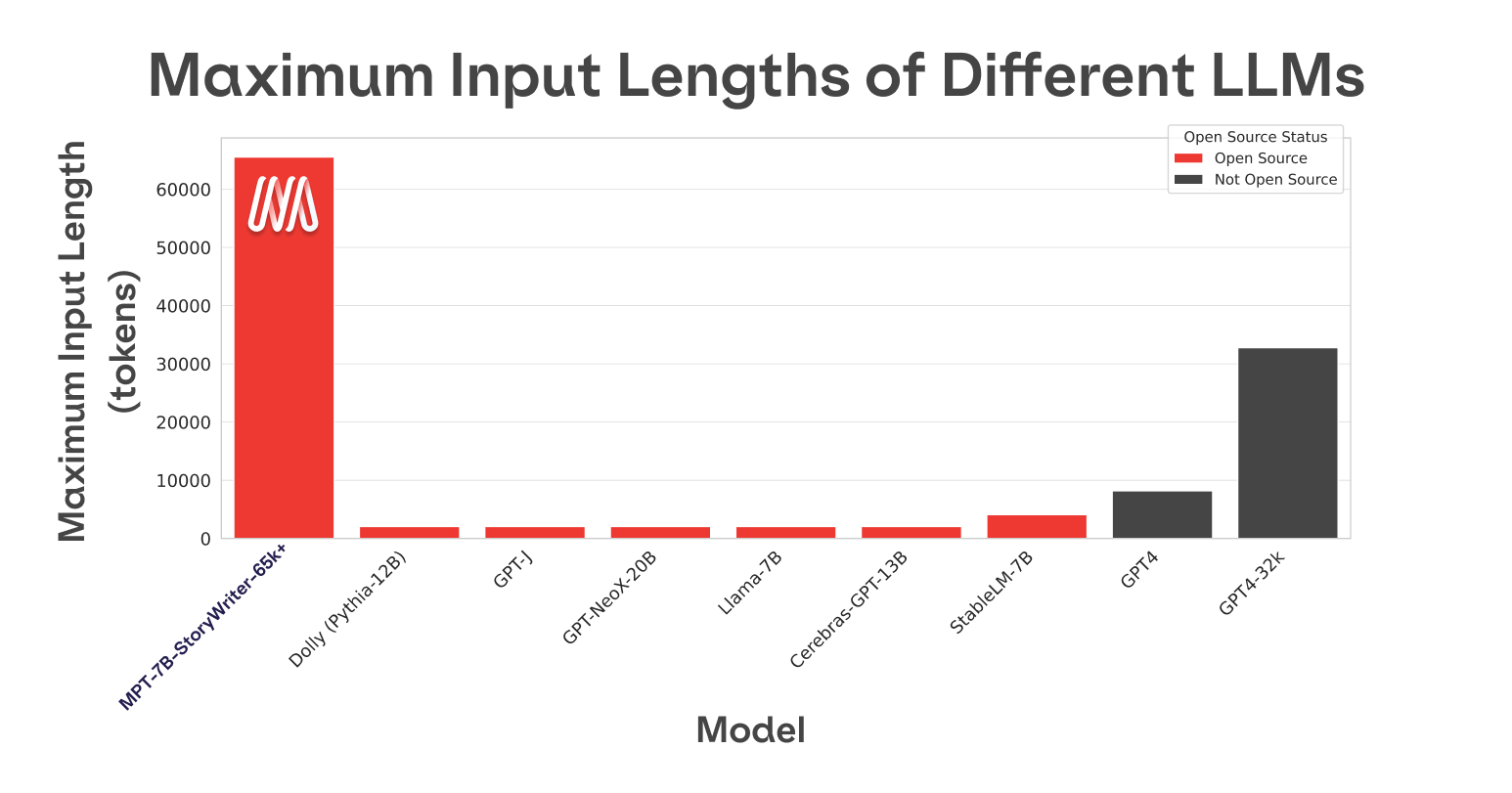
One of GPT3’s biggest limitations is context length - you can only send it up to 4000 tokens (3k words, 6 pages) before it throws a hard error, requiring you to bring in LangChain and other retrieval techniques to process long documents and prompts. But MosaicML recently open sourced MPT-7B, the newest addition to their Foundation Series, with context length going up to 84,000 tokens (63k words, 126 pages):
This transformer model, trained from scratch on 1 trillion tokens of text and code (compared to 300B for Pythia and OpenLLaMA, and 800B for StableLM), matches the quality of LLaMA-7B. It was trained on the MosaicML platform in 9.5 days on 440 GPUs with no human intervention, costing approximately $200,000. Unlike many open models, MPT-7B is licensed for commercial use and it’s optimized for fast training and inference through FlashAttention and FasterTransformer.
They also released 3 finetuned models starting from the base MPT-7B:
* MPT-7B-Instruct: finetuned on dolly_hhrlhf, a dataset built on top of dolly-5k (see our Dolly episode for more details).
* MPT-7B-Chat: finetuned on the ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct datasets.
* MPT-7B-StoryWriter-65k+: it was finetuned with a context length of 65k tokens on a filtered fiction subset of the books3 dataset. While 65k is the advertised size, the team has gotten up to 84k tokens in response when running on a single node A100-80GB GPUs. ALiBi is the dark magic that makes this possible. Turns out The Great Gatsby is only about 68k tokens, so the team used the model to create new epilogues for it!
On top of the model checkpoints, the team also open-sourced the entire codebase for pretraining, finetuning, and evaluating MPT via their new MosaicML LLM Foundry. The table we showed above was created using LLM Foundry in-context-learning eval framework itself!
In this episode, we chatted with the leads of MPT-7B at Mosaic: Jonathan Frankle, Chief Scientist, and Abhinav Venigalla, Research Scientist who spearheaded the MPT-7B training run. We talked about some of the innovations they’ve brought into the training process to remove the need for 2am on-call PagerDutys, why the LLM dataset mix is such an important yet dark art, and why some of the traditional multiple-choice benchmarks might not be very helpful for the type of technology we are building.
Show Notes
* Cerebras
* ALiBi
* List of naughty words for C4
https://twitter.com/code_star/status/1661386844250963972
* BF16 FP
p.s. yes, MPT-7B really is codenamed LLongboi!
Timestamps
* Introductions [00:00:00]
* Intro to Mosaic [00:03:20]
* Training and Creating the Models [00:05:45]
* Data Choices and the Importance of Repetition [00:08:45]
* The Central Question: What Mix of Data Sets Should You Use? [00:10:00]
* Evaluation Challenges of LLMs [0:13:00]
* Flash Attention [00:16:00]
* Fine-tuning for Creativity [00:19:50]
* Open Source Licenses and Ethical Considerations [00:23:00]
* Training Stability Enhancement [00:25:15]
* Data Readiness & Training Preparation [00:30:00]
* Dynamic Real-time Model Evaluation [00:34:00]
* Open Science for Affordable AI Research [00:36:00]
* The Open Approach [00:40:15]
* The Future of Mosaic [00:44:11]
* Speed and Efficiency [00:48:01]
* Trends and Transformers [00:54:00]
* Lightning Round and Closing [1:00:55]
Transcript
Alessio: [00:00:00] Hey everyone. Welcome to the Latent Space podcast. This is Alessio partner and CTO-in-Residence at Decibel Partners. I'm joined by my co-host, Swyx, writer and editor of Latent Space.
Swyx: Hey, and today we have Jonathan and Abhi from Mosaic ML. Welcome to our studio.
Jonathan: Guys thank you so much for having us. Thanks so much.
Swyx: How's it feel?
Jonathan: Honestly, I've been doing a lot of podcasts during the pandemic, and it has not been the same.
Swyx: No, not the same actually. So you have on your bio that you're primarily based in Boston,
Jonathan: New York. New York, yeah. My Twitter bio was a probability distribution over locations.
Swyx: Exactly, exactly. So I DMd you because I was obviously very interested in MPT-7B and DMd you, I was like, for the 0.2% of the time that you're in San Francisco, can you come please come to a podcast studio and you're like, I'm there next week.
Jonathan: Yeah, it worked out perfectly.
Swyx: We're really lucky to have you, I'll read off a few intros that people should know about you and then you can fill in the blanks.
So Jonathan, you did your BS and MS at Princeton in programming languages and then found your way into ML for your PhD at MiT where you made a real splash with the lottery ticket hypothesis in 2018, which people can check up on. I think you've done a few podcasts about it over the years, which has been highly influential, and we'll talk about sparse models at Mosaic. You have also had some side [00:01:30] quest. You taught programming for lawyers and you did some law and privacy stuff in, in DC and also did some cryptography stuff. Um, and you've been an assistant professor at Harvard before earning your PhD.
Jonathan: I've yet to start.
Swyx: You, you yet to start. Okay. But you just got your PhD.
Jonathan:. I technically just got my PhD. I was at Mosaic which delayed my defense by about two years. It was, I was at 99% done for two years. Got the job at Harvard, Mosaic started, and I had better things to do than write my dissertation for two years.
Swyx: You know, you know, this is very out of order.
Jonathan: Like, oh, completely out of order, completely backwards. Go talk to my advisor about that. He's also an advisor at Mosaic and has been from the beginning. And, you know, go talk to him about finishing on time.
Swyx: Great, great, great. And just to fill it out, Abhi, you did your BS and MS and MIT, you were a researcher at Cerebras, and you're now a research scientist at Mosaic. Just before we go into Mosaic stuff, I'm actually very curious about Cereus and, uh, just that, that space in general. Um, what are they doing that people should know about?
Abhinav: Yeah, absolutely. Um, I think the biggest thing about CEREUS is that they're really building, you know, kind of the NextGen computing platform beyond, like GPUs.
Um, they're trying to build a system that uses an entire wafer, you know, rather than cutting up a wafer into smaller chips and trying to train a model on that entire system, or actually more recently on many such wafers. Um, so it's, and it's really extraordinary. I think it's like the first time ever that kind of wafer scale computing has ever really worked. And so it's a really exciting time to be there, trying to figure out how we can map ML workloads to work, um, on a much, much bigger chip.
Swyx: And do you use like [00:03:00] a different programming language or framework to do that? Or is that like..
Abhinav: Yeah, so I mean, things have changed a bit since I was there.
I think, um, you can actually run just normal tensor flow and pie torch on there. Um, so they've built a kind of software stack that compiles it down. So it actually just kind of works naturally. But yeah.
Jonathan : Compiled versions of Python is a hot topic at the moment with Mojo as well.
Swyx: And then Mosaic, you, you spearheaded the MPT-7B effort.
INTRO TO MOSAIC [00:03:20]
Abhinav: Uh, yeah. Yeah, so it's kind of like, it's been maybe six months, 12 months in the making. We kind of started working on LMs sort of back in the summer of last year. Um, and then we came with this blog post where we kind of profiled a lot of LMs and saw, hey, the cost of training is actually a lot lower than what people might think.
Um, and then since then, you know, being inspired by kind of, you know, meta’s release, so the LLaMA models and lots of other open source work, we kind of started working towards, well, what if we were to release a really good kind of 7 billion parameter model? And that's what MPT is.
**Alessio:**You know, we mentioned some of the podcasts you had done, Jonathan, I think in one of them you mentioned Mosaic was not planning on building a model and releasing and obviously you eventually did. So what are some of the things that got you there that maybe obviously LLaMA you mentioned was an inspiration. You now have both the training and like inference products that you offer. Was this more of a research challenge in a way, uh, that you wanted to do?
Or how did the idea come to be?
Jonathan: I think there were a couple of things. So we still don't have a first class model. We're not an open AI where, you know, our businesses come to use our one great model. Our business is built around customers creating their own models. But at the end of the day, if customers are gonna create their own models, we have to have the tools to help them do that, and to have the tools to help them do that and know that they work we have to create our own models to start.
We have to know that we can do something great if customers are gonna do something great. And one too many people may have challenged me on Twitter about the fact that, you know, mosaic claims all these amazing numbers, but, you know, I believe not to, you know, call out Ross Whiteman here, but, you know, I believe he said at some point, you know, show us the pudding.
Um, and so Ross, you know, please let me know how the pudding tastes. But in all seriousness, like I think there is something, this is a demo in some sense. This is to say we did this in 9.5 days for a really reasonable cost, straight through 200, an intervention. 200 K. Yep. Um, you can do this too.
Swyx: Uh, and just to reference the numbers that you're putting out, this is the, the last year you were making a lot of noise for trading GPT 3 under 450 K, which is your, your initial estimate.
Um, and then it went down to a 100 K and stable diffusion 160 k going down to less than 50 K as well.
Jonathan: So I will be careful about that 100 K number. That's certainly the challenge I've given Abhi to hit. Oh, I wouldn't make the promise that we’ve hit yet, but you know, it's certainly a target that we have.
And I, you know, Abhi may kill me for saying this. I don't think it's crazy.
TRAINING AND CREATING THE MODELS [00:05:45]
Swyx: So we definitely want to get into like estimation math, right? Like what, what needs to happen for those big order magnitude changes to in, in infrastructure costs. But, uh, let's kind of stick to the MPT-7B story. Yeah. Tell us everything.
Like you have, uh, three different models. One of them. State of the art essentially on context length. Let's talk about the process of training them, the, uh, the decisions that you made. Um, I can go into, you know, individual details, but I just wanna let you let you rip.
Abhinav: Yeah, so I mean, I think, uh, we started off with the base model, which is kind of for all practical purposes, a recreation of LLaMA 7B.
Um, so it's a 7 billion perimeter model trained on the trillion tokens. Um, and our goal was like, you know, we should do it efficiently. We should be able to do it like, kind of hands free so we don't have to babysit the runs as they're doing them. And it could be kind of a, a launching point for these fine tune models and those fine tune models, you know, on, on the one hand they're kind of really fun for the community, like the story writer model, which has like a 65,000 length context window and you can even kind of extrapolate beyond that. Um, but they're, they're also kind of just tr inspirations really. So you could kind of start with an MPT-7B base and then build your own custom, you know, downstream. If you want a long context code model, you could do that with our platform. If you wanted one that was for a particular language, you could do that too.
But yeah, so we picked kind of the three variance chat and instruct and story writer just kind of like inspirations looking at what people were doing in the community today. Yeah.
Alessio: And what's the beginning of the math to come up with? You know, how many tokens you wanna turn it on? How many parameters do you want in a bottle? 7 billion and 30 billion seem to be kind of like two of the magic numbers going around right now.
Abhinav: Yeah, definitely. Definitely. Yeah, I think like there's sort of these scaling laws which kind of tell you how to best spend your training compute if that's all you cared about. So if you wanna spend $200,000 exactly in the most efficient way, there'd be a recipe for doing that.
Um, and that we usually go by the Chinchilla laws. Now for these models, we actually didn't quite do that because we wanted to make sure that people could actually run these at home and that they [00:07:30] were good for inference. So we trained them kind of beyond those chinchilla points so that we're almost over-training them.
I think there's like a joke going on online that they're like long boy and that that came up internally because we were training them for really, really long durations. So that 7B model, the chinchilla point might be 140 billion tokens. Instead, we trained a trillion, so almost seven times longer than you normally would.
Swyx: So longboi was the code name. So is it, is it the trading method? Is it the scaling law that you're trying to coin or is it the code name for the 64 billion?
Jonathan: Uh, 64. It was just an internal joke for the, for training on way more tokens than you would via chinchilla. Okay. Um, we can coin it long boy and it, it really stuck, but just to, you know, long boys filled with two ELs at the beginning.
Yeah. Cause you know, we wanted the lLLaMA thing in there as well.
Jonathan: Yeah, yeah, yeah. Our darn CEO we have to rein him in that guy, you know, you can't, yeah. I'm gonna take away his Twitter password at some point. Um, but you know, he had to let that one out publicly. And then I believe there was a YouTube video where someone happened to see it mentioned before the model came out and called it the Long G boy or something like that.
Like, so you know, now it's out there in the world. It's out there. It's like Sydnee can't put it back in
Swyx: There's a beautiful picture which I think Naveen tweeted out, which, um, shows a long boy on a whiteboard.
Jonathan: That was the origin of Long Boy. In fact, the legs of the lLLaMA were the two Ls and the long boy.
DATA CHOICES AND THE IMPORTANCE OF REPETITION [00:08:45]
Swyx: Well, talk to me about your data choices, right? Like this is your passion project. Like what can you tell us about it?
Jonathan: Yeah, I think Abhi wanted to kill me by the end for trying to use all the GPUs on data and none of them on actually training the model.
Um, at the end of the day, We know that you need to train these models and [00:09:00] lots of data, but there are a bunch of things we don't know.
Number one is what kinds of different data sources matter. The other is how much does repetition really matter? And really kind of repetition can be broken down into how much does quality versus quantity matter. Suppose I had the world's best 10 billion tokens of data. Would it be better to train on that a hundred times or better to train on a trillion tokens of low quality, fresh data?
And obviously there's, there's a middle point in between. That's probably the sweet spot. But how do you even know what good quality data is? And. So, yeah, this is, nobody knows, and I think the more time I spent, we have a whole data team, so me and several other people, the more time that we spent on this, you know, I came away thinking, gosh, we know nothing.
Gosh, if I were back in academia right now, I would definitely go and, you know, write a paper about this because I have no idea what's going on.
Swyx: You would write a paper about it. I'm interested in such a paper. I haven't come across any that exists. Could you frame the central question of such a paper?
THE CENTRAL QUESTION: WHAT MIX OF DATA SETS SHOULD YOU USE? [00:10:00]
Jonathan: Yeah. The central question is what mix of data sets should you use? Okay. Actually I've, you know, you had mentioned my law school stuff. I went back to Georgetown Law where I used to teach, um, in the midst of creating this model, and I actually sat down with a class of law students and asked them, I gave them our exact data sets, our data mixes, um, like how many tokens we had, and I said, Create the best data set for your model.
Knowing they knew nothing about large language models, they just know that data goes in and it's going to affect the behavior. Um, and I was like, create a mix and they basically covered all the different trade-offs. Um, you probably want a lot of English language [00:10:30] text to start with. You get that from the web, but do you want it to be multilingual?
If so, you're gonna have a lot less English text. Maybe it'll be worse. Do you wanna have code in there? There are all these beliefs that code leads to models being better at logical reasoning, of which I've seen zero evidence. Rep. It's not, um, I mean, really made a great code model, but code models leading to better chain of thought reasoning on the part of language or code being in the training set leading to better chain of thought reasoning.
People claim this all the time, but I've still never seen any real evidence beyond that. You know, one of the generations of the GPT three model started supposedly from Code Da Vinci. Yes. And so there's a belief that, you know, maybe that helped. But again, no evidence. You know, there's a belief that spending a lot of time on good sources like Wikipedia is good for the model.
Again, no evidence. At the end of the day, we tried a bunch of different data mixes and the answer was that there are some that are better or worse than others. We did find that the pile, for example, was a really solid data mix, but you know, there were stronger data mixes by our evaluation metrics. And I'll get back to the evaluation question in a minute cuz that's a really important one.
This data set called c4, which is what the original T five model was trained on, is weirdly good. And everybody, when I posted on this on Twitter, like Stella Beaterman from Luther mentioned this, I think someone else mentioned this as well. C4 does really well in the metrics and we have no idea why we de-duplicated it against our evaluation set.
So it's not like it memorized the data, it is just one web scrape from 2019. If you actually look at the T five paper and see how it was pre-processed, it looks very silly. Mm-hmm. They removed anything that had the word JavaScript in it because they didn't want to get like no JavaScript [00:12:00] warnings. They removed anything with curly braces cuz they didn't wanna get JavaScript in it.
They looked at this list of bad words, um, and removed anything that had those bad words. If you actually look at the list of bad words, words like gay are on that list. And so there's, you know, it is a very problematic, you know, list of words, but that was the cleaning that leads to a data set that seems to be unbeatable.
So that to me says that we know nothing about data. We, in fact used a data set called mc four as well, which is they supposedly did the same pre-processing of C4 just on more web calls. The English portion is much worse than C4 for reasons that completely escape us. So in the midst of all that, Basically I set two criteria.
One was I wanted to be at least as good as mc four English, like make sure that we're not making things actively worse. And mc four English is a nice step up over other stuff that's out there. And two was to go all in on diversity after that, making sure that we had some code, we had some scientific papers, we had Wikipedia, because people are gonna use this model for all sorts of different purposes.
But I think the most important thing, and I'm guessing abhi had a million opinions on this, is you're only as good as your evaluation. And we don't know how to evaluate models for the kind of generation we ask them to do. So past a certain point, you have to kinda shrug and say, well, my evaluation's not even measuring what I care about.
Mm-hmm. So let me just make reasonable choices.
EVALUATION CHALLENGES OF LLMs [0:13:00]
Swyx: So you're saying MMLU, big bench, that kind of stuff is not. Convincing for you
Jonathan: A lot of this stuff is you've got two kinds of tasks. Some of these are more of multiple choice style tasks where there is a right answer. Um, either you ask the model to spit out A, B, C, or D or you know, and if you're more [00:13:30] sophisticated, you look at the perplexity of each possible answer and pick the one that the model is most likely to generate.
But we don't ask these models to do multiple choice questions. We ask them to do open-ended generation. There are also open-ended generation tasks like summarization. You compare using things like a blue score or a rouge score, which are known to be very bad ways of comparing text. At the end of the day, there are a lot of great summaries of a paper.
There are a lot of great ways to do open form generation, and so humans are, to some extent, the gold standard. Humans are very expensive. It turns out we can't put them into our eval pipeline and just have the humans look at our model every, you know, 10 minutes? Not yet. Not yet. Maybe soon. Um, are you volunteering Abhi?
Abhinav: I, I, I just know we have a great eval team who's, uh, who's helping us build new metrics. So if they're listening,
Jonathan: But it's, you know, evaluation of large language models is incredibly hard and I don't think any of these metrics really truly capture. What we expect from the models in practice.
Swyx: Yeah. And we might draw wrong conclusions.
There's been a debate recently about the emergence phenomenon, whether or not it's a mirage, right? I don't know if you guys have opinions about that process.
Abhinav: Yeah, I think I've seen like this paper and all and all, even just kind of plots from different people where like, well maybe it's just a artifact of power, like log scaling or metrics or, you know, we're meshing accuracy, which is this a very like harsh zero one thing.
Yeah. Rather than kind of something more continuous. But yeah, similar to what Jonathan was saying about evals. Like there there's one issue of like you just like our diversity of eval metrics, like when we put these models up, even like the chat ones, the instruct ones, people are using 'em for such a variety of tasks.
There's just almost no way we get ahead of time, like measuring individual dimensions. And then also particularly like, you know, at the 7B scale, [00:15:00] um, these models still are not super great yet at the really hard tasks, like some of the hardest tasks in MMLU and stuff. So sometimes they're barely scoring like the above kind of random chance, you know, like on really, really hard tasks.
So potentially as we. You know, aim for higher and higher quality models. Some of these things will be more useful to us. But we kind of had to develop MPT 7B kind of flying a little bit blind on, on what we knew it was coming out and just going off of like, you know, a small set of common sensor reasoning tasks.
And of course, you know, just comparing, you know, those metrics versus other open source models.
Alessio: I think fast training in inference was like one of the goals, right? So there's always the trade off between doing the hardest thing and like. Doing all the other things quickly.
Abhinav: Yeah, absolutely. Yeah, I mean, I think like, you know, even at the 7B scale, you know, uh, people are trying to run these things on CPUs at home.
You know, people are trying to port these to their phones, basically prioritizing the fact that the small scale would lead to our adoption. That was like a big, um, big thing going on.
Alessio: Yeah. and you mentioned, um, flash attention and faster transformer as like two of the core things. Can you maybe explain some of the benefits and maybe why other models don't use it?
FLASH ATTENTION [00:16:00]
Abhinav: Yeah, absolutely. So flash attention is this basically faster implementation of full attention. Um, it's like a mathematical equivalent developed by like actually some of our collaborators, uh, at Stanford. Uh, the hazy research. Hazy research, yeah, exactly.
Jonathan: What is, what, what, what's the name hazy research mean?
Abhinav: I actually have no idea.
Swyx: I have no clue. All these labs have fun names. I always like the stories behind them.
Abhinav: Yeah, absolutely. We really, really liked flash attention. We, I think, had to integrate into repo even as [00:16:30] as early as September of last year. And it really just helps, you know, with training speed and also inference speed and we kind of bake that into model architecture.
And this is kind of unique amongst all the other hugging face models you see out there. So ours actually, you can toggle between normal torch attention, which will work anywhere and flash attention, which will work on GPUs right out of the box. And that way I think you get almost like a 2x speed up at training time and somewhere between like 50% to a hundred percent speed up at inference time as well.
So again, this is just like, we really, really wanted people to use these and like, feel like an improvement and we, we have the team to, to help deliver that.
Swyx: Another part, um, of your choices was alibi position, encodings, which people are very interested in, maybe a lot of people just, uh, to sort of take in, in coatings as, as a given.
But there's actually a lot of active research and honestly, it's a lot of, um, it's very opaque as well. Like people don't know how to evaluate encodings, including position encodings, but may, may, could you explain, um, alibi and, um, your choice?
Abhinav: Yeah, for sure. The alibi and uh, kind of flash attention thing all kind of goes together in interesting ways.
And even with training stability too. What alibi does really is that it eliminates the need to have positional embeddings in your model. Where previously, if you're a token position one, you have a particular embedding that you add, and you can't really go beyond your max position, which usually is like about 2000.
With alibies, they get rid of that. Instead, just add a bias to the attention map itself. That's kind of like this slope. And if at inference time you wanna go much, much larger, they just kind of stretch that slope out to a longer, longer number of positions. And because the slope is kind of continuous and you can interpret it, it all works out now.
Now one of [00:18:00] the, the funny things we found is like with flash attention, it saved so much memory and like improved performance so much that even as early as I kind of last year, like we were profiling models with, with very long context lines up to like, you know, the 65 k that you seen in release, we just never really got around to using it cuz we didn't really know what we might use it for.
And also it's very hard to train stably. So we started experimenting with alibi integration, then we suddenly found that, oh wow, stability improves dramatically and now we can actually work together with alibi in a long context lens. That's how we got to like our story writer model where we can stably train these models out to very, very long context lenses and, and use them performantly.
Jonathan: Yeah.
Swyx: And it's also why you don't have a firm number. Most people now have a firm number on the context line. Now you're just like, eh, 65 to 85
Abhinav: Oh yeah, there's, there's a, there's a big age to be 64 K or 65 k. 65 k plus.
Swyx: Just do powers of twos. So 64 isn't, you know.
Jonathan: Right, right. Yeah. Yeah. But we could, I mean, technically the context length is infinite.
If you give me enough memory, um, you know, we can just keep going forever. We had a debate over what number to say is the longest that we could handle. We picked 84 cakes. It's the longest I expect people to see easily in practice. But, you know, we played around for even longer than that and I don't see why we couldn't go longer.
Swyx: Yeah. Um, and so for those who haven't read the blog posts, you put the Great Gatsby in there and, uh, asked it to write an epilogue, which seemed pretty impressive.
Jonathan: Yeah. There are a bunch of epilogues floating around internally at Mosaic. Yeah. That wasn't my favorite. I think we all have our own favorites.
Yeah. But there are a bunch of really, really good ones. There was one where, you know, it's Gatsby's funeral and then Nick starts talking to Gatsby's Ghost, and Gatsby's father shows up and, you know, then he's [00:19:30] at the police station with Tom. It was very plot heavy, like this is what comes next. And a bunch of that were just very Fitzgerald-esque, like, you know, beautiful writing.
Um, but it was cool to just see that Wow, the model seemed to actually be working with. You know, all this input. Yeah, yeah. Like it's, it's exciting. You can think of a lot of things you could do with that kind of context length.
FINE-TUNING FOR CREATIVITY [00:19:50]
Swyx: Is there a trick to fine tuning for a creative task rather than, um, factual task?
Jonathan: I don't know what that is, but probably, yeah, I think, you know, the person, um, Alex who did this, he did fine tune the model explicitly on books. The goal was to try to get a model that was really a story writer. But, you know, beyond that, I'm not entirely sure. Actually, it's a great question. Well, no, I'll ask you back.
How would you measure that?
Swyx: Uh, God, human feedback is the solve to all things. Um, I think there is a labeling question, right? Uh, in computer vision, we had a really, really good episode with Robo Flow on the segment. Anything model where you, you actually start human feedback on like very, I think it's something like 0.5% of the, the overall, uh, final, uh, uh, labels that you had.
But then you sort augment them and then you, you fully automate them, um, which I think could be applied to text. It seems intuitive and probably people like snorkel have already raised ahead on this stuff, but I just haven't seen this applied in the language domain yet.
Jonathan: It, I mean there are a lot of things that seem like they make a lot of sense in machine learning that never work and a lot of things that make zero sense that seem to work.
So, you know, I've given up trying to even predict. Yeah, yeah. Until I see the data or try it, I just kind shg my shoulders and you know, you hope for the best. Bring data or else, right? Yeah, [00:21:00] exactly. Yeah, yeah, yeah.
Alessio: The fine tuning of books. Books three is like one of the big data sets and there was the whole.
Twitter thing about trade comments and like, you know, you know, I used to be a community moderator@agenius.com and we've run into a lot of things is, well, if you're explaining lyrics, do you have the right to redistribute the lyrics? I know you ended up changing the license on the model from a commercial use Permitted.
Swyx: Yeah let's let them. I'm not sure they did.
Jonathan: So we flipped it for about a couple hours.
Swyx: Um, okay. Can we, can we introduce the story from the start Just for people who are under the loop.
Jonathan: Yeah. So I can tell the story very simply. So, you know, the book three data set does contain a lot of books. And it is, you know, as I discovered, um, it is a data set that provokes very strong feelings from a lot of folks.
Um, that was one, one guy from one person in particular, in fact. Um, and that's about it. But it turns out one person who wants a lot of attention can, you know, get enough attention that we're talking about it now. And so we had a, we had a discussion internally after that conversation and we talked about flipping the license and, you know, very late at night I thought, you know, maybe it's a good thing to do.
And decided, you know, actually probably better to just, you know, Stan Pat's license is still Apache too. And one of the conversations we had was kind of, we hadn't thought about this cuz we had our heads down, but the Hollywood writer Strike took place basically the moment we released the model. Mm-hmm.
Um, we were releasing a model that could do AI generated creative content. And that is one of the big sticking points during the strike. Oh, the optics are not good. So the optics aren't good and that's not what we want to convey. This is really, this is a demo of the ability to do really long sequence lengths and.
Boy, you know, [00:22:30] that's, that's not timing that we appreciated. And so we talked a lot internally that night about like, oh, we've had time to read the news. We've had time to take a breath. We don't really love this. Came to the conclusion that it's better to just leave it as it is now and learn the lesson for the future.
But certainly that was one of my takeaways is this stuff, you know, there's a societal context around this that it's easy to forget when you're in the trenches just trying to get the model to train. And you know, in hindsight, you know, I might've gone with a different thing than a story writer. I might've gone with, you know, coder because we seem to have no problem putting programmers out of work with these models.
Swyx: Oh yeah. Please, please, you know, take away this stuff from me.
OPEN SOURCE LICENSES AND ETHICAL CONSIDERATIONS [00:23:00]
Jonathan: Right. You know, so it's, I think, you know, really. The copyright concerns I leave to the lawyers. Um, that's really, if I learned one thing teaching at a law school, it was that I'm not a lawyer and all this stuff is a little complicated, especially open source licenses were not designed for this kind of world.
They were designed for a world of forcing people to be more open, not forcing people to be more closed. And I think, you know, that was part of the impetus here, was to try to use licenses to make things more closed. Um, which is, I think, against the grain of the open source ethos. So that struck me as a little bit strange, but I think the most important part is, you know, we wanna be thoughtful and we wanna do the right thing.
And in that case, you know, I hope with all that interesting licensing fund you saw, we're trying to be really thoughtful about this and it's hard. I learned a lot from that experience.
Swyx: There’s also, I think, an open question of fair use, right? Is training on words of fair use because you don't have a monopoly on words, but some certain arrangements of words you do.
And who is to say how much is memorization by a model versus actually learning and internalizing and then. Sometimes happening to land at the right, the [00:24:00] same result.
Jonathan: And if I've learned one lesson, I'm not gonna be the person to answer that question. Right, exactly. And so my position is, you know, we will try to make this stuff open and available.
Yeah. And, you know, let the community make decisions about what they are or aren't comfortable using. Um, and at the end of the day, you know, it still strikes me as a little bit weird that someone is trying to use these open source licenses to, you know, to close the ecosystem and not to make things more open.
That's very much against the ethos of why these licenses were created.
Swyx: So the official mosaic position, I guess is like, before you use TC MPC 7B for anything commercial, check your own lawyers now trust our lawyers, not mosaic’s lawyers.
Jonathan: Yeah, okay. Yeah. I'm, you know, our lawyers are not your lawyers.
Exactly. And, you know, make the best decision for yourself. We've tried to be respectful of the content creators and, you know, at the end of the day, This is complicated. And this is something that is a new law. It's a new law. It's a new law that hasn't been established yet. Um, but it's a place where we're gonna continue to try to do the right thing.
Um, and it's, I think, one of the commenters, you know, I really appreciated this said, you know, well, they're trying to do the right thing, but nobody knows what the right thing is to even do, you know, the, I guess the, the most right thing would've been to literally not release a model at all. But I don't think that would've been the best thing for the community either.
Swyx: Cool.Well, thanks. Well handled. Uh, we had to cover it, just cause
Jonathan: Oh, yes, no worries. A big piece of news. It's been on my mind a lot.
TRAINING STABILITY ENHANCEMENT [00:25:15]
Swyx: Yeah. Yeah. Well, you've been very thoughtful about it. Okay. So a lot of these other ideas in terms of architecture, flash, attention, alibi, and the other data sets were contributions from the rest of the let's just call it open community of, of machine learning advancements. Uh, but Mosaic in [00:25:30] particular had some stability improvements to mitigate loss spikes, quote unquote, uh, which, uh, I, I took to mean, uh, your existing set of tools, uh, maybe we just co kind of covered that. I don't wanna sort of put words in your mouth, but when you say things like, uh, please enjoy my empty logbook.
How much of an oversell is that? How much, you know, how much is that marketing versus how much is that reality?
Abhinav: Oh yeah. That, that one's real. Yeah. It's like fully end-to-end. Um, and I think.
Swyx: So maybe like what, what specific features of Mosaic malibu?
Abhinav: Totally, totally. Yeah. I think I'll break it into two parts.
One is like training stability, right? Knowing that your model's gonna basically get to the end of the training without loss spikes. Um, and I think, you know, at the 7B scale, you know, for some models like it ha it's not that big of a deal. As you train for longer and longer durations, we found that it's trickier and trickier to avoid these lost spikes.
And so we actually spent a long time figuring out, you know, what can we do about our initialization, about our optimizers, about the architecture that basically prevents these lost spikes. And you know, even in our training run, if you zoom in, you'll see small intermittent spikes, but they recover within a few hundred steps.
And so that's kind of the magical bit. Our line is one of defenses we recover from Las Vegas, like just naturally, right? Mm-hmm. Our line two defense was that we used determinism and basically really smart resumption strategies so that if something catastrophic happened, we can resume very quickly, like a few batches before.
And apply some of these like, uh, interventions. So we had these kinds of preparations, like a plan B, but we didn't have to use them at all for MPT 7B training. So, that was kind of like a lucky break. And the third part of like basically getting all the way to the empty law book is having the right training infrastructure.[00:27:00]
So this is basically what, like is, one of the big selling points of the platform is that when you try to train these models on hundreds of GPUs, not many people outside, you know, like deep industry research owners, but the GPUs fail like a lot. Um, I would say like almost once every thousand a 100 days.
So for us on like a big 512 cluster every two days, basically the run will fail. Um, and this is either due to GPUs, like falling off the bus, like that's, that's a real error we see, or kind of networking failures or something like that. And so in those situations, what people have normally done is they'll have an on-call team that's just sitting round the clock, 24-7 on slack, once something goes wrong.
And if then they'll basically like to try to inspect the cluster, take nodes out that are broken, restart it, and it's a huge pain. Like we ourselves did this for a few months. And as a result of that, because we're building such a platform, we basically step by step automated every single one of those processes.
So now when a run fails, we have this automatic kind of watch talk that's watching. It'll basically stop the job. Test the nodes cord in anyone's that are broken and relaunch it. And because our software's all deterministic has fast resumption stuff, it just continues on gracefully. So within that log you can see sometimes I think maybe at like 2:00 AM or something, the run failed and within a few minutes it's back up and running and all of us are just sleeping peacefully.
Jonathan: I do wanna say that was hard one. Mm-hmm. Um, certainly this is not how things were going, you know, many months ago, hardware failures we had on calls who were, you know, getting up at two in the morning to, you know, figure out which node had died for what reason, restart the job, have to cord the node. [00:28:30] Um, we were seeing catastrophic loss spikes really frequently, even at the 7B scale that we're just completely derailing runs.
And so this was step by step just ratcheting our way there. As Abhi said, to the point where, Many models are training at the moment and I'm sitting here in the studio and not worrying one bit about whether the runs are gonna continue. Yeah.
Swyx: I'm, I'm not so much of a data center hardware kind of guy, but isn't there existing software to do this for CPUs and like, what's different about this domain? Does this question make sense at all?
Jonathan: Yeah, so when I think about, like, I think back to all the Google fault tolerance papers I read, you know, as an undergrad or grad student mm-hmm. About, you know, building distributed systems. A lot of it is that, you know, Each CPU is doing, say, an individual unit of work.
You've got a database that's distributed across your cluster. You wanna make sure that one CPU failing can't, or one machine failing can't, you know, delete data. So you, you replicate it. You know, you have protocols like Paxos where you're literally, you've got state machines that are replicated with, you know, with leaders and backups and things like that.
And in this case, you were performing one giant computation where you cannot afford to lose any node. If you lose a node, you lose model state. If you lose a node, you can't continue. It may be that, that in the future we actually, you know, create new versions of a lot of our distributed training libraries that do have backups and where data is replicated so that if you lose a node, you can detect what node you've lost and just continue training without having to stop the run, you know?
Pull from a checkpoint. Yeah. Restart again on different hardware. But for now, we're certainly in a world where if anything dies, that's the end of the run and you have to go back and recover from it. [00:30:00]
DATA READINESS & TRAINING PREPARATION [00:30:00]
Abhinav: Yeah. Like I think a big part, a big word there is like synchronous data pluralism, right? So like, we're basically saying that on every step, every GP is gonna do some work.
They're gonna stay in sync with each other and average their, their gradients and continue. Now that there are algorithmic techniques to get around this, like you could say, oh, if a GP dies, just forget about it. All the data that's gonna see, we'll just forget about it. We're not gonna train on it.
But, we don't like to do that currently because, um, it makes us give up determinism, stuff like that. Maybe in the future, as you go to extreme scales, we'll start looking at some of those methods. But at the current time it's like, we want determinism. We wanted to have a run that we could perfectly replicate if we needed to.
And it was, the goal is figure out how to run it on a big cluster without humans having to babysit it. Babysit it.
Alessio: So as you mentioned, these models are kind of the starting point for a lot of your customers To start, you have a. Inference product. You have a training product. You previously had a composer product that is now kind of not rolled into, but you have like a super set of it, which is like the LLM foundry.
How are you seeing that change, you know, like from the usual LOP stack and like how people train things before versus now they're starting from, you know, one of these MPT models and coming from there. Like worship teams think about as they come to you and start their journey.
Jonathan: So I think there's a key distinction to make here, which is, you know, when you say starting from MPT models, you can mean two things.
One is actually starting from one of our checkpoints, which I think very few of our customers are actually going to do, and one is starting from our configuration. You can look at our friends at Rep for that, where, you know, MPT was in progress when Refl [00:31:30] came to us and said, Hey, we need a 3 billion parameter model by next week on all of our data.
We're like, well, here you go. This is what we're doing, and if it's good enough for us, um, hopefully it's good enough for you. And that's basically the message we wanna send to our customers. MPT is basically clearing a path all the way through where they know that they can come bring their data, they can use our training infrastructure, they can use all of our amazing orchestration and other tools that abhi just mentioned, for fault tolerance.
They can use Composer, which is, you know, still at the heart of our stack. And then the l l M Foundry is really the specific model configuration. They can come in and they know that thing is gonna train well because we've already done it multiple times.
Swyx: Let's dig in a little bit more on what should people have ready before they come talk to you? So data architecture, eval that they're looking, etc.
Abhinav: Yeah, I, I mean, I think we'll accept customers at any kind of stage in their pipeline. You know, like I'd say science, there's archetypes of people who have built products around like some of these API companies and reach a stage or maturity level where it's like we want our own custom models now, either for the purpose of reducing cost, right?
Like our inference services. Quite a bit cheaper than using APIs or because they want some kind of customization that you can't really get from the other API providers. I'd say the most important things to have before training a big model. You know, you wanna have good eval metrics, you know, some kind of score that you can track as you're training your models and scaling up, they can tell you you're progressing.
And it's really funny, like a lot of times customers will be really excited about training the models, right? It's really fun to like launch shelves on hundreds of gfs, just all around. It's super fun. But then they'll be like, but wait, what are we gonna measure? Not just the training loss, right? I mean, it's gotta be more than that.[00:33:00]
So eval metrics is like a, it's a good pre-req also, you know, your data, you know, either coming with your own pre-training or fine-tune data and having like a strategy to clean it or we can help clean it too. I think we're, we're building a lot of tooling around that. And I think once you have those two kinds of inputs and sort of the budget that you want, we can pretty much walk you through the rest of it, right?
Like that's kind of what we do. Recently we helped build CR FM's model for biomedical language a while back.
Jonathan: Um, we can. That's the center of research for foundation models.
Abhi: Exactly, exactly.
Jonathan: Spelling it out for people. Of course.
Abhinav: No, absolutely. Yeah, yeah. No, you've done more of these than I have.
Um, I think, uh, basically it's sort of, we can help you figure out what model I should train to scale up so that when I go for my big run company, your here run, it's, uh, it's predictable. You can feel confident that it's gonna work, and you'll kind of know what quality you're gonna get out before you have to spend like a few hundred thousand dollars.
DYNAMIC REAL-TIME MODEL EVALUATION [00:34:00]
Alessio: The rap Reza from rap was on the podcast last week and, uh, they had human eval and then that, uh, I'm Jon Eval, which is like vibe based.
Jonathan: And I, I do think the vibe based eval cannot be, you know, underrated really at the, I mean, at the end of the day we, we did stop our models and do vibe checks and we did, as we monitor our models, one of our evals was we just had a bunch of prompts and we would watch the answers as the model trained and see if they changed cuz honestly, You know, I don't really believe in any of these eval metrics to capture what we care about.
Mm-hmm. But when you ask it, uh, you know, I don't know. I think one of our prompts was to suggest games for a three-year-old and a seven-year-old. That would be fun to play. Like that was a lot more [00:34:30] valuable to me personally, to see how that answer evolved and changed over the course of training. So, you know, and human eval, just to clarify for folks, human human eval is an automated evaluation metric.
There's no humans in it at all. There's no humans in it at all. It's really badly named. I got so confused the first time that someone brought that to me and I was like, no, we're not bringing humans in. It's like, no, it's, it's automated. They just called it a bad name and there's only a hundred cents on it or something.
Abhinav: Yeah. Yeah. And, and it's for code specifically, right?
Jonathan: Yeah. Yeah. It's very weird. It's a, it's a weird, confusing name that I hate, but you know, when other metrics are called hella swag, like, you know, you do it, just gotta roll with it at this point.
Swyx: You're doing live evals now. So one, one of the tweets that I saw from you was that it is, uh, important that you do it paralyzed.
Uh, maybe you kind of wanna explain, uh, what, what you guys did.
Abhinav: Yeah, for sure. So with LLM Foundry, there's many pieces to it. There's obviously the core training piece, but there's also, you know, tools for evaluation of models. And we've kind of had one of the, I think it's like the, the fastest like evaluation framework.
Um, basically it's multi GPU compatible. It runs with Composer, it can support really, really big models. So basically our framework runs so fast that even Azure models are training. We can run these metrics live during the training. So like if you have a dashboard like weights and biases, you kind of watch all these evil metrics.
We have, like, 15 or 20 of them honestly, that we track during the run and add negligible overhead. So we can actually watch as our models go and feel confident. Like, it's not like we wait until the very last day to, to test if the models good or not
Jonathan: That's amazing. Yeah. I love that we've gotten this far into the conversation.
We still haven't talked about efficiency and speed. Those are usually our two watch words at Mosaic, which is, you know, that's great. That says that we're [00:36:00] doing a lot of other cool stuff, but at the end of the day, um, you know, Cost comes first. If you can't afford it, it doesn't matter. And so, you know, getting things down cheap enough that, you know, we can monitor in real time, getting things down cheap enough that we can even do it in the first place.
That's the basis for everything we do.
OPEN SCIENCE FOR AFFORDABLE AI RESEARCH [00:36:00]
Alessio: Do you think a lot of the questions that we have around, you know, what data sets we should use and things like that are just because training was so expensive before that, we just haven't run enough experiments to figure that out. And is that one of your goals is trying to make it cheaper so that we can actually get the answers?
Jonathan: Yeah, that's a big part of my personal conviction for being here. I think I'm, I'm still in my heart, the second year grad student who was jealous of all his friends who had GPUs and he didn't, and I couldn't train any models except in my laptop. And that, I mean, the lottery ticket experiments began on my laptop that I had to beg for one K 80 so that I could run amist.
And I'm still that person deep down in my heart. And I'm a believer that, you know, if we wanna do science and really understand these systems and understand how to make them work well, understand how they behave, understand what makes them safe and reliable. We need to make it cheap enough that we can actually do science, and science involves running dozens of experiments.
When I finally, you know, cleaned out my g c s bucket from my PhD, I deleted a million model checkpoints. I'm not kidding. There were over a million model checkpoints. That is the kind of science we need, you know, that's just what it takes. In the same way that if you're in a biology lab, you don't just grow one cell and say like, eh, the drug seems to work on that cell.
Like, there's a lot more science you have to do before you really know.
Abhinav: Yeah. And I think one of the special things about Mosaic's kind of [00:37:30] position as well is that we have such, so many customers all trying to train models that basically we have the incentive to like to devote all these resources and time to do this science.
Because when we learn which pieces actually work, which ones don't, we get to help many, many people, right? And so that kind of aggregation process I think is really important for us. I remember way back there was a paper about Google that basically would investigate batch sizes or something like that.
And it was this paper that must have cost a few million dollars during all the experience. And it was just like, wow, what a, what a benefit to the whole community. Now, like now we all get to learn from that and we get, we get to save. We don't have to spend those millions of dollars anymore. So I think, um, kind of mosaical science, like the insights we get on, on data, on pre-screening architecture, on all these different things, um, that's why customers come to us.
Swyx: Yeah, you guys did some really good stuff on PubMed, G B T as well. That's the first time I heard of you. Of you. And that's also published to the community.
Abhinav: Yeah, that one was really fun. We were like, well, no one's really trained, like fully from scratch domain specific models before. Like, what if we just did a biomed one?
Would it still work? And, uh, yeah, I'd be really excited. That did, um, we'll probably have some follow up soon, I think, later this summer.
Jonathan: Yeah. Yes. Stay tuned on that. Um, but I, I will say just in general, it's a really important value for us to be open in some sense. We have no incentive not to be open. You know, we make our money off of helping people train better.
There's no cost to us in sharing what we learn with the community. Cuz really at the end of the day, we make our money off of those custom models and great infrastructure and, and putting all the pieces together. That's honestly where the Mosaic name came from. Not off of like, oh, we've got, you know, this one cool secret trick [00:39:00] that we won't tell you, or, you know, closing up.
I sometimes, you know, in the past couple weeks I've talked to my friends at places like Brain or, you know, what used to be Brain Now Google DeepMind. Oh, I R I P Brain. Yeah. R i p Brian. I spent a lot of time there and it was really a formative time for me. Um, so I miss it, but. You know, I kind of feel like we're one of the biggest open research labs left in industry, which is a very sad state of affairs because we're not very big.
Um, but at least can you say how big the team is actually? Yeah. We were about 15 researchers, so we're, we're tiny compared to, you know, the huge army of researchers I remember at Brain or at fair, at Deep Mind back, you know, when I was there during their heydays. Um, you know, but everybody else is kind of, you know, closed up and isn't saying very much anymore.
Yeah. And we're gonna keep talking and we're gonna keep sharing and, you know, we will try to be that vanguard to the best of our ability. We're very small and I, I can't promise we're gonna do what those labs used to do in terms of scale or quantity of research, but we will share what we learn and we will try to create resources for the community.
Um, I, I dunno, I just, I believe in openness fundamentally. I'm an academic at heart and it's sad to me to watch that go away from a lot of the big labs.
THE OPEN APPROACH [00:40:15]
Alessio: We just had a live pod about the, you know, open AI snow mode, uh, post that came out and it was one of the first time I really dove into Laura and some of the this new technologies, like how are you thinking about what it's gonna take for like the open approach to really work?
Obviously today, GPT four is still, you know, part of like that state-of-the-art model for a [00:40:30] lot of tasks. Do you think some of the innovation and kind of returning methods that we have today are enough if enough people like you guys are like running these, these research groups that are open? Or do you think we still need a step function improvement there?
... [Content truncated due to size limits]