We have announced our first speaker, friend of the show Dylan Patel, and topic slates for Latent Space LIVE! at NeurIPS. Sign up for IRL/Livestream and to debate!
We are still taking questions for our next big recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!
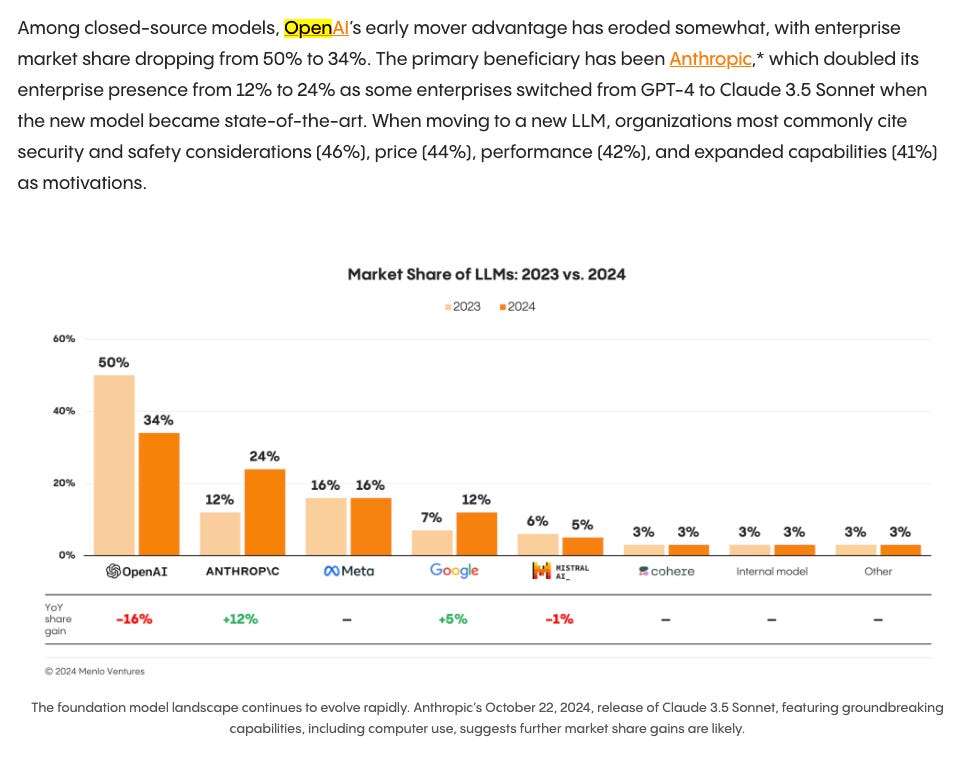
The vibe shift we observed in July - in favor of Claude 3.5 Sonnet, first introduced in June — has been remarkably long lived and persistent, surviving multiple subsequent updates of 4o, o1 and Gemini versions, for Anthropic’s Claude to end 2024 as the preferred model for AI Engineers and even being the exclusive choice for new code agents like bolt.new (our next guest on the pod!), which unlocked so much performance from Claude Sonnet that it went from $0 to $4m ARR in 4 weeks when it launched last month.
Anthropic has now raised an additional $4b from Amazon and made an incredibly well received update of Claude 3.5 Sonnet (and Haiku), making significant improvements in performance over its predecessors:
Solving SWE-Bench
As part of the October Sonnet release, Anthropic teased a blink-and-you’ll miss it result:
The updated Claude 3.5 Sonnet shows wide-ranging improvements on industry benchmarks, with particularly strong gains in agentic coding and tool use tasks. On coding, it improves performance on SWE-bench Verified from 33.4% to 49.0%, scoring higher than all publicly available models—including reasoning models like OpenAI o1-preview and specialized systems designed for agentic coding. It also improves performance on TAU-bench, an agentic tool use task, from 62.6% to 69.2% in the retail domain, and from 36.0% to 46.0% in the more challenging airline domain. The new Claude 3.5 Sonnet offers these advancements at the same price and speed as its predecessor.
This was followed up by a blogpost a week later from today’s guest, Erik Schluntz, the engineer who implemented and scored this SOTA result using a simple, non-overengineered version of the SWE-Agent framework (you can see the submissions here). We have previously covered the SWE-Bench story extensively:
* Speaking with SWEBench/SWEAgent authors at ICLR
* Speaking with Cosine Genie, the previous SOTA (43.8%) on SWEBench Verified (with brief update at DevDay 2024)
* Speaking with Shunyu Yao on SWEBench and the ReAct paradigm driving SWE-Agent
One of the notable inclusions in this blogpost are the tools that Erik decided to give Claude, e.g. the “Edit Tool”:
The tools teased in the SWEBench submission/blogpost were then polished up and released with Computer Use…
And you can also see even more computer use tools given in the new Model Context Protocol servers:
Claude Computer Use
Because it is one of the best received AI releases of the year, we recommend watching the 2 minute Computer Use intro (and related demos) in its entirety:
Eric also worked on Claude’s function calling, tool use, and computer use APIs, so we discuss that in the episode.
Erik [00:53:39]: With computer use, just give the thing a browser that's logged into what you want to integrate with, and it's going to work immediately. And I see that reduction in friction as being incredibly exciting. Imagine a customer support team where, okay, hey, you got this customer support bot, but you need to go integrate it with all these things. And you don't have any engineers on your customer support team. But if you can just give the thing a browser that's logged into your systems that you need it to have access to, now, suddenly, in one day, you could be up and rolling with a fully integrated customer service bot that could go do all the actions you care about. So I think that's the most exciting thing for me about computer use, is reducing that friction of integrations to almost zero.
As you’ll see, this is very top of mind for Erik as a former Robotics founder who’s company basically used robots to interface with human physical systems like elevators.
Full Video episode
Show Notes
* “Raising the bar on SWE-Bench Verified”
* Human Eval & other benchmarks
* Aider
* Cursor
* E2B
* 1X
* Dust
* Bolt
* TauBench
Timestamps
* [00:00:00] Introductions
* [00:03:39] What is SWE-Bench?
* [00:12:22] SWE-Bench vs HumanEval vs others
* [00:15:21] SWE-Agent architecture and runtime
* [00:21:18] Do you need code indexing?
* [00:24:50] Giving the agent tools
* [00:27:47] Sandboxing for coding agents
* [00:29:16] Why not write tests?
* [00:30:31] Redesigning engineering tools for LLMs
* [00:35:53] Multi-agent systems
* [00:37:52] Why XML so good?
* [00:42:57] Thoughts on agent frameworks
* [00:45:12] How many turns can an agent do?
* [00:47:12] Using multiple model types
* [00:51:40] Computer use and agent use cases
* [00:59:04] State of AI robotics
* [01:04:24] Robotics in manufacturing
* [01:05:01] Hardware challenges in robotics
* [01:09:21] Is self-driving a good business?
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners. And today we're in the new studio with my usual co-host, Shawn from Smol AI.
Swyx [00:00:14]: Hey, and today we're very blessed to have Erik Schluntz from Anthropic with us. Welcome.
Erik [00:00:19]: Hi, thanks very much. I'm Erik Schluntz. I'm a member of technical staff at Anthropic, working on tool use, computer use, and Swebench.
Swyx [00:00:27]: Yeah. Well, how did you get into just the whole AI journey? I think you spent some time at SpaceX as well? Yeah. And robotics. Yeah. There's a lot of overlap between like the robotics people and the AI people, and maybe like there's some interlap or interest between language models for robots right now. Maybe just a little bit of background on how you got to where you are. Yeah, sure.
Erik [00:00:50]: I was at SpaceX a long time ago, but before joining Anthropic, I was the CTO and co-founder of Cobalt Robotics. We built security and inspection robots. These are sort of five foot tall robots that would patrol through an office building or a warehouse looking for anything out of the ordinary. Very friendly, no tasers or anything. We would just sort of call a remote operator if we saw anything. We have about 100 of those out in the world, and had a team of about 100. We actually got acquired about six months ago, but I had left Cobalt about a year ago now, because I was starting to get a lot more excited about AI. I had been writing a lot of my code with things like Copilot, and I was like, wow, this is actually really cool. If you had told me 10 years ago that AI would be writing a lot of my code, I would say, hey, I think that's AGI. And so I kind of realized that we had passed this level, like, wow, this is actually really useful for engineering work. That got me a lot more excited about AI and learning about large language models. So I ended up taking a sabbatical and then doing a lot of reading and research myself and decided, hey, I want to go be at the core of this and joined Anthropic.
Alessio [00:01:53]: And why Anthropic? Did you consider other labs? Did you consider maybe some of the robotics companies?
Erik [00:02:00]: So I think at the time I was a little burnt out of robotics, and so also for the rest of this, any sort of negative things I say about robotics or hardware is coming from a place of burnout, and I reserve my right to change my opinion in a few years. Yeah, I looked around, but ultimately I knew a lot of people that I really trusted and I thought were incredibly smart at Anthropic, and I think that was the big deciding factor to come there. I was like, hey, this team's amazing. They're not just brilliant, but sort of like the most nice and kind people that I know, and so I just felt like I could be a really good culture fit. And ultimately, I do care a lot about AI safety and making sure that I don't want to build something that's used for bad purposes, and I felt like the best chance of that was joining Anthropic.
Alessio [00:02:39]: And from the outside, these labs kind of look like huge organizations that have these obscure
Swyx [00:02:44]: ways to organize.
Alessio [00:02:45]: How did you get, you joined Anthropic, did you already know you were going to work on of the stuff you publish or you kind of join and then you figure out where you land? I think people are always curious to learn more.
Erik [00:02:57]: Yeah, I've been very happy that Anthropic is very bottoms up and sort of very sort of receptive to whatever your interests are. And so I joined sort of being very transparent of like, hey, I'm most excited about code generation and AI that can actually go out and sort of touch the world or sort of help people build things. And, you know, those weren't my initial initial projects. I also came in and said, hey, I want to do the most valuable possible thing for this company and help Anthropic succeed. And, you know, like, let me find the balance of those. So I was working on lots of things at the beginning, you know, function calling, tool use. And then sort of as it became more and more relevant, I was like, oh, hey, like, let's it's time to go work on encoding agents and sort of started looking at SWE-Bench as sort of a really good benchmark for that.
Swyx [00:03:39]: So let's get right into SWE-Bench. That's one of the many claims to fame. I feel like there's just been a series of releases related with Cloud 3.5 Sonnet around about two or three months ago, 3.5 Sonnet came out and it was it was a step ahead in terms of a lot of people immediately fell in love with it for coding. And then last month you released a new updated version of Cloud Sonnet. We're not going to talk about the training for that because that's still confidential. But I think Anthropic's done a really good job, like applying the model to different things. So you took the lead on SWE-Bench, but then also we're going to talk a little bit about computer use later on. So maybe just give us a context about why you looked at SWE-Bench Verified and you actually came up with a whole system for building agents that would maximally use the model well. Yeah.
Erik [00:04:28]: So I'm on a sub team called Product Research. And basically the idea of product research is to really understand what end customers care about and want in the models and then work to try to make that happen. So we're not focused on sort of these more abstract general benchmarks like math problems or MMLU, but we really care about finding the things that are really valuable and making sure the models are great at those. And so because I've been interested in coding agents, I knew that this would be a really valuable thing. And I knew there were a lot of startups and our customers trying to build coding agents with our models. And so I said, hey, this is going to be a really good benchmark to be able to measure that and do well on it. And I wasn't the first person at Anthropic to find SWE-Bench, and there are lots of people that already knew about it and had done some internal efforts on it. It fell to me to sort of both implement the benchmark, which is very tricky, and then also to sort of make sure we had an agent and basically like a reference agent, maybe I'd call it, that could do very well on it. Ultimately, we want to provide how we implemented that reference agent so that people can build their own agents on top of our system and get sort of the most out of it as possible. So with this blog post we released on SWE-Bench, we released the exact tools and the prompt that we gave the model to be able to do well.
Swyx [00:05:46]: For people who don't know, who maybe haven't dived into SWE-Bench, I think the general perception is they're like tasks that a software engineer could do. I feel like that's an inaccurate description because it is basically, one, it's a subset of like 12 repos. It's everything they could find that every issue with like a matching commit that could be tested. So that's not every commit. And then SWE-Bench verified is further manually filtered by OpenAI. Is that an accurate description and anything you'd change about that? Yes.
Erik [00:06:14]: SWE-Bench is, it certainly is a subset of all tasks. It's first of all, it's only Python repos, so already fairly limited there. And it's just 12 of these popular open source repos. And yes, it's only ones where there were tests that passed at the beginning and also new tests that were introduced that test the new feature that's added. So it is, I think, a very limited subset of real engineering tasks. But I think it's also very valuable because even though it's a subset, it is true engineering tasks. And I think a lot of other benchmarks are really kind of these much more artificial setups of even if they're related to coding, they're more like coding interview style questions or puzzles that I think are very different from day-to-day what you end up doing. I don't know how frequently you all get to use recursion in your day-to-day job, but whenever I do, it's like a treat. And I think it's almost comical, and a lot of people joke about this in the industry, is how different interview questions are.
Swyx [00:07:13]: Dynamic programming. Yeah, exactly.
Erik [00:07:15]: Like, you code. From the day-to-day job. But I think one of the most interesting things about SWE-Bench is that all these other benchmarks are usually just isolated puzzles, and you're starting from scratch. Whereas SWE-Bench, you're starting in the context of an entire repository. And so it adds this entirely new dimension to the problem of finding the relevant files. And this is a huge part of real engineering, is it's actually pretty rare that you're starting something totally greenfield. You need to go and figure out where in a codebase you're going to make a change and understand how your work is going to interact with the rest of the systems. And I think SWE-Bench does a really good job of presenting that problem.
Alessio [00:07:51]: Why do we still use human eval? It's like 92%, I think. I don't even know if you can actually get to 100% because some of the data is not actually
Swyx [00:07:59]: solvable.
Alessio [00:08:00]: Do you see benchmarks like that, they should just get sunsetted? Because when you look at the model releases, it's like, oh, it's like 92% instead of like 89%, 90% on human eval versus, you know, SWE-Bench verified is you have 49%, right? Which is like, before 45% was state of the art, but maybe like six months ago it was like 30%, something like that. So is that a benchmark that you think is going to replace human eval, or do you think they're just going to run in parallel?
Erik [00:08:27]: I think there's still need for sort of many different varied evals. Like sometimes you do really care about just sort of greenfield code generation. And so I don't think that everything needs to go to sort of an agentic setup.
Swyx [00:08:39]: It would be very expensive to implement.
Erik [00:08:41]: The other thing I was going to say is that SWE-Bench is certainly hard to implement and expensive to run because each task, you have to parse, you know, a lot of the repo to understand where to put your code. And a lot of times you take many tries of writing code, running it, editing it. It can use a lot of tokens compared to something like human eval. So I think there's definitely a space for these more traditional coding evals that are sort of easy to implement, quick to run, and do get you some signal. Maybe hopefully there's just sort of harder versions of human eval that get created.
Alessio [00:09:14]: How do we get SWE-Bench verified to 92%? Do you think that's something where it's like line of sight to it, or it's like, you know, we need a whole lot of things to go right? Yeah, yeah.
Erik [00:09:23]: And actually, maybe I'll start with SWE-Bench versus SWE-Bench verified, which is I think something I missed earlier. So SWE-Bench is, as we described, this big set of tasks that were scraped.
Swyx [00:09:33]: Like 12,000 or something?
Erik [00:09:34]: Yeah, I think it's 2,000 in the final set. But a lot of those, even though a human did them, they're actually impossible given the information that comes with the task. The most classic example of this is the test looks for a very specific error string. You know, like assert message equals error, something, something, something. And unless you know that's exactly what you're looking for, there's no way the model is going to write that exact same error message, and so the tests are going to fail. So SWE-Bench verified was actually made in partnership with OpenAI, and they hired humans to go review all these tasks and pick out a subset to try to remove any obstacle like this that would make the tasks impossible. So in theory, all of these tasks should be fully doable by the model. And they also had humans grade how difficult they thought the problems would be. Between less than 15 minutes, I think 15 minutes to an hour, an hour to four hours, and greater than four hours. So that's kind of this interesting sort of how big the problem is as well. To get to SWE-Bench verified to 90%, actually, maybe I'll also start off with some of the remaining failures that I see when running our model on SWE-Bench. I'd say the biggest cases are the model sort of operates at the wrong level of abstraction. And what I mean by that is the model puts in maybe a smaller band-aid when really the task is asking for a bigger refactor. And some of those, you know, is the model's fault, but a lot of times if you're just sort of seeing the GitHub issue, it's not exactly clear which way you should do. So even though these tasks are possible, there's still some ambiguity in how the tasks are described. That being said, I think in general, language models frequently will produce a smaller diff when possible, rather than trying to do a big refactor. I think another area, at least the agent we created, didn't have any multimodal abilities, even though our models are very good at vision. So I think that's just a missed opportunity. And if I read through some of the traces, there's some funny things where, especially the tasks on matplotlib, which is a graphing library, the test script will save an image and the model will just say, okay, it looks great, you know, without looking at it. So there's certainly extra juice to squeeze there of just making sure the model really understands all the sides of the input that it's given, including multimodal. But yeah, I think like getting to 92%. So this is something that I have not looked at, but I'm very curious about. I want someone to look at, like, what is the union of all of the different tasks that have been solved by at least one attempt at SWE-Bench Verified. There's a ton of submissions to the benchmark, and so I'd be really curious to see how many of those 500 tasks at least someone has solved. And I think, you know, there's probably a bunch that none of the attempts have ever solved. And I think it'd be interesting to look at those and say, hey, is there some problem with these? Like, are these impossible? Or are they just really hard and only a human could do them?
Swyx [00:12:22]: Yeah, like specifically, is there a category of problems that are still unreachable by any LLM agent? Yeah, yeah. And I think there definitely are.
Erik [00:12:28]: The question is, are those fairly inaccessible or are they just impossible because of the descriptions? But I think certainly some of the tasks, especially the ones that the human graders reviewed as like taking longer than four hours are extremely difficult. I think we got a few of them right, but not very many at all in the benchmark.
Swyx [00:12:49]: And did those take less than four hours?
Erik [00:12:51]: They certainly did less than, yeah, than four hours.
Swyx [00:12:54]: Is there a correlation of length of time with like human estimated time? You know what I mean? Or do we have sort of more of X paradox type situations where it's something super easy for a model, but hard for a human?
Erik [00:13:06]: I actually haven't done the stats on that, but I think that'd be really interesting to see of like how many tokens does it take and how is that correlated with difficulty? What is the likelihood of success with difficulty? I think actually a really interesting thing that I saw, one of my coworkers who was also working on this named Simon, he was focusing just specifically on the very hard problems, the ones that are said to take longer than four hours. And he ended up sort of creating a much more detailed prompt than I used. And he got a higher score on the most difficult subset of problems, but a lower score overall on the whole benchmark. And the prompt that I made, which is sort of much more simple and bare bones, got a higher score on the overall benchmark, but lower score on the really hard problems. And I think some of that is the really detailed prompt made the model sort of overcomplicate a lot of the easy problems, because honestly, a lot of the suite bench problems, they really do just ask for a bandaid where it's like, hey, this crashes if this is none, and really all you need to do is put a check if none. And so sometimes trying to make the model think really deeply, it'll think in circles and overcomplicate something, which certainly human engineers are capable of as well. But I think there's some interesting thing of the best prompt for hard problems might not be the best prompt for easy problems.
Alessio [00:14:19]: How do we fix that? Are you supposed to fix it at the model level? How do I know what prompt I'm supposed to use?
Swyx [00:14:25]: Yeah.
Erik [00:14:26]: And I'll say this was a very small effect size, and so I think this isn't worth obsessing over. I would say that as people are building systems around agents, I think the more you can separate out the different kinds of work the agent needs to do, the better you can tailor a prompt for that task. And I think that also creates a lot of like, for instance, if you were trying to make an agent that could both solve hard programming tasks, and it could just write quick test files for something that someone else had already made, the best way to do those two tasks might be very different prompts. I see a lot of people build systems where they first sort of have a classification, and then route the problem to two different prompts. And that's sort of a very effective thing, because one, it makes the two different prompts much simpler and smaller, and it means you can have someone work on one of the prompts without any risk of affecting the other tasks. So it creates like a nice separation of concerns. Yeah.
Alessio [00:15:21]: And the other model behavior thing you mentioned, they prefer to generate like shorter diffs. Why is that? Like, is there a way? I think that's maybe like the lazy model question that people have is like, why are you not just generating the whole code instead of telling me to implement it?
Swyx [00:15:36]: Are you saving tokens? Yeah, exactly. It's like conspiracy theory. Yeah. Yeah.
Erik [00:15:41]: Yeah. So there's two different things there. One is like the, I'd say maybe like doing the easier solution rather than the hard solution. And I'd say the second one, I think what you're talking about is like the lazy model is like when the model says like dot, dot, dot, code remains the same.
Swyx [00:15:52]: Code goes here. Yeah. I'm like, thanks, dude.
Erik [00:15:55]: But honestly, like that just comes as like people on the internet will do stuff like that. And like, dude, if you're talking to a friend and you ask them like to give you some example code, they would definitely do that. They're not going to reroll the whole thing. And so I think that's just a matter of like, you know, sometimes you actually do just, just want like the relevant changes. And so I think it's, this is something where a lot of times like, you know, the models aren't good at mind reading of like which one you want. So I think that like the more explicit you can be in prompting to say, Hey, you know, give me the entire thing, no, no elisions versus just give me the relevant changes. And that's something, you know, we want to make the models always better at following those kinds of instructions.
Swyx [00:16:32]: I'll drop a couple of references here. We're recording this like a day after Dario, Lex Friedman just dropped his five hour pod with Dario and Amanda and the rest of the crew. And Dario actually made this interesting observation that like, we actually don't want, we complain about models being too chatty in text and then not chatty enough in code. And so like getting that right is kind of a awkward bar because, you know, you, you don't want it to yap in its responses, but then you also want it to be complete in, in code. And then sometimes it's not complete. Sometimes you just want it to diff, which is something that Enthopic has also released with a, you know, like the, the fast edit stuff that you guys did. And then the other thing I wanted to also double back on is the prompting stuff. You said, you said it was a small effect, but it was a noticeable effect in terms of like picking a prompt. I think we'll go into suite agent in a little bit, but I kind of reject the fact that, you know, you need to choose one prompt and like have your whole performance be predicated on that one prompt. I think something that Enthopic has done really well is meta prompting, prompting for a prompt. And so why can't you just develop a meta prompt for, for all the other prompts? And you know, if it's a simple task, make a simple prompt, if it's a hard task, make a hard prompt. Obviously I'm probably hand-waving a little bit, but I will definitely ask people to try the Enthopic Workbench meta prompting system if they haven't tried it yet. I went to the Build Day recently at Enthopic HQ, and it's the closest I've felt to an AGI, like learning how to operate itself that, yeah, it's, it's, it's really magical.
Erik [00:17:57]: Yeah, no, Claude is great at writing prompts for Claude.
Swyx [00:18:00]: Right, so meta prompting. Yeah, yeah.
Erik [00:18:02]: The way I think about this is that humans, even like very smart humans still use sort of checklists and use sort of scaffolding for themselves. Surgeons will still have checklists, even though they're incredible experts. And certainly, you know, a very senior engineer needs less structure than a junior engineer, but there still is some of that structure that you want to keep. And so I always try to anthropomorphize the models and try to think about for a human sort of what is the equivalent. And that's sort of, you know, how I think about these things is how much instruction would you give a human with the same task? And do you, would you need to give them a lot of instruction or a little bit of instruction?
Alessio [00:18:36]: Let's talk about the agent architecture maybe. So first, runtime, you let it run until it thinks it's done or it reaches 200k context window.
Swyx [00:18:45]: How did you come up? What's up with that?
Erik [00:18:47]: Yeah.
Swyx [00:18:48]: Yeah.
Erik [00:18:49]: I mean, this, so I'd say that a lot of previous agent work built sort of these very hard coded and rigid workflows where the model is sort of pushed through certain flows of steps. And I think to some extent, you know, that's needed with smaller models and models that are less smart. But one of the things that we really wanted to explore was like, let's really give Claude the reins here and not force Claude to do anything, but let Claude decide, you know, how it should approach the problem, what steps it should do. And so really, you know, what we did is like the most extreme version of this is just give it some tools that it can call and it's able to keep calling the tools, keep thinking, and then yeah, keep doing that until it thinks it's done. And that's sort of the most, the most minimal agent framework that we came up with. And I think that works very well. I think especially the new Sonnet 3.5 is very, very good at self-correction, has a lot of like grit. Claude will try things that fail and then try, you know, come back and sort of try different approaches. And I think that's something that you didn't see in a lot of previous models. Some of the existing agent frameworks that I looked at, they had whole systems built to try to detect loops and see, oh, is the model doing the same thing, you know, more than three times, then we have to pull it out. And I think like the smarter the models are, the less you need that kind of extra scaffolding. So yeah, just giving the model tools and letting it keep sample and call tools until it thinks it's done was the most minimal framework that we could think of. And so that's what we did.
Alessio [00:20:18]: So you're not pruning like bad paths from the context. If it tries to do something, it fails. You just burn all these tokens.
Swyx [00:20:25]: Yes.
Erik [00:20:26]: I would say the downside of this is that this is sort of a very token expensive way to do
Swyx [00:20:29]: this. But still, it's very common to prune bad paths because models get stuck. Yeah.
Erik [00:20:35]: But I'd say that, yeah, 3.5 is not getting stuck as much as previous models. And so, yeah, we wanted to at least just try the most minimal thing. Now, I would say that, you know, this is definitely an area of future research, especially if we talk about these problems that are going to take a human more than four hours. Those might be things where we're going to need to go prune bad paths to let the model be able to accomplish this task within 200k tokens. So certainly I think there's like future research to be done in that area, but it's not necessary to do well on these benchmarks.
Swyx [00:21:06]: Another thing I always have questions about on context window things, there's a mini cottage industry of code indexers that have sprung up for large code bases, like the ones in SweetBench. You didn't need them? We didn't.
Erik [00:21:18]: And I think I'd say there's like two reasons for this. One is like SweetBench specific and the other is a more general thing. The more general thing is that I think Sonnet is very good at what we call agentic search. And what this basically means is letting the model decide how to search for something. It gets the results and then it can decide, should it keep searching or is it done? Does it have everything it needs? So if you read through a lot of the traces of the SweetBench, the model is calling tools to view directories, list out things, view files. And it will do a few of those until it feels like it's found the file where the bug is. And then it will start working on that file. And I think like, again, this is all, everything we did was about just giving Claude the full reins. So there's no hard-coded system. There's no search system that you're relying on getting the correct files into context. This just totally lets Claude do it.
Swyx [00:22:11]: Or embedding things into a vector database. Exactly. Oops. No, no.
Erik [00:22:17]: This is very, very token expensive. And so certainly, and it also takes many, many turns. And so certainly if you want to do something in a single turn, you need to do RAG and just push stuff into the first prompt.
Alessio [00:22:28]: And just to make it clear, it's using the Bash tool, basically doing LS, looking at files and then doing CAD for the following context. It can do that.
Erik [00:22:35]: But it's file editing tool also has a command in it called view that can view a directory. It's very similar to LS, but it just sort of has some nice sort of quality of life improvements. So I think it'll only do an LS sort of two directories deep so that the model doesn't get overwhelmed if it does this on a huge file. I would say actually we did more engineering of the tools than the overall prompt. But the one other thing I want to say about this agentic search is that for SWE-Bench specifically, a lot of the tasks are bug reports, which means they have a stack trace in them. And that means right in that first prompt, it tells you where to go. And so I think this is a very easy case for the model to find the right files versus if you're using this as a general coding assistant where there isn't a stack trace or you're asking it to insert a new feature, I think there it's much harder to know which files to look at. And that might be an area where you would need to do more of this exhaustive search where an agentic search would take way too long.
Swyx [00:23:33]: As someone who spent the last few years in the JS world, it'd be interesting to see SWE-Bench JS because these stack traces are useless because of so much virtualization that we do. So they're very, very disconnected with where the code problems are actually appearing.
Erik [00:23:50]: That makes me feel better about my limited front-end experience, as I've always struggled with that problem.
Swyx [00:23:55]: It's not your fault. We've gotten ourselves into a very, very complicated situation. And I'm not sure it's entirely needed. But if you talk to our friends at Vercel, they will say it is.
Erik [00:24:04]: I will say SWE-Bench just released SWE-Bench Multimodal, which I believe is either entirely JavaScript or largely JavaScript. And it's entirely things that have visual components of them.
Swyx [00:24:15]: Are you going to tackle that? We will see.
Erik [00:24:17]: I think it's on the list and there's interest, but no guarantees yet.
Swyx [00:24:20]: Just as a side note, it occurs to me that every model lab, including Enthopic, but the others as well, you should have your own SWE-Bench, whatever your bug tracker tool. This is a general methodology that you can use to track progress, I guess.
Erik [00:24:34]: Yeah, sort of running on our own internal code base.
Swyx [00:24:36]: Yeah, that's a fun idea.
Alessio [00:24:37]: Since you spend so much time on the tool design, so you have this edit tool that can make changes and whatnot. Any learnings from that that you wish the AI IDEs would take in? Is there some special way to look at files, feed them in?
Erik [00:24:50]: I would say the core of that tool is string replace. And so we did a few different experiments with different ways to specify how to edit a file. And string replace, basically, the model has to write out the existing version of the string and then a new version, and that just gets swapped in. We found that to be the most reliable way to do these edits. Other things that we tried were having the model directly write a diff, having the model fully regenerate files. That one is actually the most accurate, but it takes so many tokens, and if you're in a very big file, it's cost prohibitive. There's basically a lot of different ways to represent the same task. And they actually have pretty big differences in terms of model accuracy. I think Eider, they have a really good blog where they explore some of these different methods for editing files, and they post results about them, which I think is interesting. But I think this is a really good example of the broader idea that you need to iterate on tools rather than just a prompt. And I think a lot of people, when they make tools for an LLM, they kind of treat it like they're just writing an API for a computer, and it's sort of very minimal. It's sort of just the bare bones of what you'd need, and honestly, it's so hard for the models to use those. Again, I come back to anthropomorphizing these models. Imagine you're a developer, and you just read this for the very first time, and you're trying to use it. You can do so much better than just sort of the bare API spec of what you'd often see. Include examples in the description. Include really detailed explanations of how things work. And I think that, again, also think about what is the easiest way for the model to represent the change that it wants to make. For file editing, as an example, writing a diff is actually... Let's take the most extreme example. You want the model to literally write a patch file. I think patch files have at the very beginning numbers of how many total lines change. That means before the model has actually written the edit, it needs to decide how many numbers or how many lines are going to change.
Swyx [00:26:52]: Don't quote me on that.
Erik [00:26:54]: I think it's something like that, but I don't know if that's exactly the diff format. But you can certainly have formats that are much easier to express without messing up than others. And I like to think about how much human effort goes into designing human interfaces for things. It's incredible. This is entirely what FrontEnd is about, is creating better interfaces to kind of do the same things. And I think that same amount of attention and effort needs to go into creating agent computer interfaces.
Swyx [00:27:19]: It's a topic we've discussed, ACI or whatever that looks like. I would also shout out that I think you released some of these toolings as part of computer use as well. And people really liked it. It's all open source if people want to check it out. I'm curious if there's an environment element that complements the tools. So how do you... Do you have a sandbox? Is it just Docker? Because that can be slow or resource intensive. Do you have anything else that you would recommend?
Erik [00:27:47]: I don't think I can talk about sort of public details or about private details about how we implement our sandboxing. But obviously, we need to have sort of safe, secure, and fast sandboxes for training for the models to be able to practice writing code and working in an environment.
Swyx [00:28:03]: I'm aware of a few startups working on agent sandboxing. E2B is a close friend of ours that Alessio has led around in, but also I think there's others where they're focusing on snapshotting memory so that it can do time travel for debugging. Computer use where you can control the mouse or keyboard or something like that. Whereas here, I think that the kinds of tools that we offer are very, very limited to coding agent work cases like bash, edit, you know, stuff like that. Yeah.
Erik [00:28:30]: I think the computer use demo that we released is an extension of that. It has the same bash and edit tools, but it also has the computer tool that lets it get screenshots and move the mouse and keyboard. Yeah. So I definitely think there's sort of more general tools there. And again, the tools we released as part of SweetBench were, I'd say they're very specific for like editing files and doing bash, but at the same time, that's actually very general if you think about it. Like anything that you would do on a command line or like editing files, you can do with those tools. And so we do want those tools to feel like any sort of computer terminal work could be done with those same tools rather than making tools that were like very specific for SweetBench like run tests as its own tool, for instance. Yeah.
Swyx [00:29:15]: You had a question about tests.
Alessio [00:29:16]: Yeah, exactly. I saw there's no test writer tool. Is it because it generates the code and then you're running it against SweetBench anyway, so it doesn't really need to write the test or?
Swyx [00:29:26]: Yeah.
Erik [00:29:27]: So this is one of the interesting things about SweetBench is that the tests that the model's output is graded on are hidden from it. That's basically so that the model can't cheat by looking at the tests and writing the exact solution. And I'd say typically the model, the first thing it does is it usually writes a little script to reproduce the error. And again, most SweetBench tasks are like, hey, here's a bug that I found. I run this and I get this error. So the first thing the model does is try to reproduce that. So it's kind of been rerunning that script as a mini test. But yeah, sometimes the model will like accidentally introduce a bug that breaks some other tests and it doesn't know about that.
Alessio [00:30:05]: And should we be redesigning any tools? We kind of talked about this and like having more examples, but I'm thinking even things of like Q as a query parameter in many APIs, it's like easier for the model to like re-query than read the Q. I'm sure it learned the Q by this point, but like, is there anything you've seen like building this where it's like, hey, if I were to redesign some CLI tools, some API tool, I would like change the way structure to make it better for LLMs?
Erik [00:30:31]: I don't think I've thought enough about that off the top of my head, but certainly like just making everything more human friendly, like having like more detailed documentation and examples. I think examples are really good in things like descriptions, like so many, like just using the Linux command line, like how many times I do like dash dash help or look at the man page or something. It's like, just give me one example of like how I actually use this. Like I don't want to go read through a hundred flags. Just give me the most common example. But again, so you know, things that would be useful for a human, I think are also very useful for a model.
Swyx [00:31:03]: Yeah. I mean, there's one thing that you cannot give to code agents that is useful for human is this access to the internet. I wonder how to design that in, because one of the issues that I also had with just the idea of a suite bench is that you can't do follow up questions. You can't like look around for similar implementations. These are all things that I do when I try to fix code and we don't do that. It's not, it wouldn't be fair, like it'd be too easy to cheat, but then also it's kind of not being fair to these agents because they're not operating in a real world situation. Like if I had a real world agent, of course I'm giving it access to the internet because I'm not trying to pass a benchmark. I don't have a question in there more, more just like, I feel like the most obvious tool access to the internet is not being used.
Erik [00:31:47]: I think that that's really important for humans, but honestly the models have so much general knowledge from pre-training that it's, it's like less important for them. I feel like versioning, you know, if you're working on a newer thing that was like, they came after the knowledge cutoff, then yes, I think that's very important. I think actually this, this is like a broader problem that there is a divergence between Sweebench and like what customers will actually care about who are working on a coding agent for real use. And I think one of those there is like internet access and being able to like, how do you pull in outside information? I think another one is like, if you have a real coding agent, you don't want to have it start on a task and like spin its wheels for hours because you gave it a bad prompt. You want it to come back immediately and ask follow up questions and like really make sure it has a very detailed understanding of what to do, then go off for a few hours and do work. So I think that like real tasks are going to be much more interactive with the agent rather than this kind of like one shot system. And right now there's no benchmark that, that measures that. And maybe I think it'd be interesting to have some benchmark that is more interactive. I don't know if you're familiar with TauBench, but it's a, it's a customer service benchmark where there's basically one LLM that's playing the user or the customer that's getting support and another LLM that's playing the support agent and they interact and try to resolve the issue.
Swyx [00:33:08]: Yeah. We talked to the LMSIS guys. Awesome. And they also did MTBench for people listening along. So maybe we need MTSWE-Bench. Sure. Yeah.
Erik [00:33:16]: So maybe, you know, you could have something where like before the SWE-Bench task starts, you have like a few back and forths with kind of like the, the author who can answer follow up questions about what they want the task to do. And of course you'd need to do that where it doesn't cheat and like just get the exact, the exact thing out of the human or out of the sort of user. But I think that would be a really interesting thing to see. If you look at sort of existing agent work, like a Repl.it's coding agent, I think one of the really great UX things they do is like first having the agent create a plan and then having the human approve that plan or give feedback. I think for agents in general, like having a planning step at the beginning, one, just having that plan will improve performance on the downstream task just because it's kind of like a bigger chain of thought, but also it's just such a better UX. It's way easier for a human to iterate on a plan with a model rather than iterating on the full task that sort of has a much slower time through each loop. If the human has approved this implementation plan, I think it makes the end result a lot more sort of auditable and trustable. So I think there's a lot of things sort of outside of SweetBench that will be very important for real agent usage in the world. Yeah.
Swyx [00:34:27]: I will say also, there's a couple of comments on names that you dropped. Copilot also does the plan stage before it writes code. I feel like those approaches have generally been less Twitter successful because it's not prompt to code, it's prompt plan code. You know, so there's a little bit of friction in there, but it's not much. Like it's, it actually, it's, it, you get a lot for what it's worth. I also like the way that Devin does it, where you can sort of edit the plan as it goes along. And then the other thing with Repl.it, we had a, we hosted a sort of dev day pregame with Repl.it and they also commented about multi-agents. So like having two agents kind of bounce off of each other. I think it's a similar approach to what you're talking about with kind of the few shot example, just as in the prompts of clarifying what the agent wants. But typically I think this would be implemented as a tool calling another agent, like a sub-agent I don't know if you explored that, do you like that idea?
Erik [00:35:20]: I haven't explored this enough, but I've definitely heard of people having good success with this. Of almost like basically having a few different sort of personas of agents, even if they're all the same LLM. I think this is one thing with multi-agent that a lot of people will kind of get confused by is they think it has to be different models behind each thing. But really it's sort of usually the same, the same model with different prompts. And yet having one, having them have different personas to kind of bring different sort of thoughts and priorities to the table. I've seen that work very well and sort of create a much more thorough and thought out
Swyx [00:35:53]: response.
Erik [00:35:53]: I think the downside is just that it adds a lot of complexity and it adds a lot of extra tokens. So I think it depends what you care about. If you want a plan that's very thorough and detailed, I think it's great. If you want a really quick, just like write this function, you know, you probably don't want to do that and have like a bunch of different calls before it does this.
Alessio [00:36:11]: And just talking about the prompt, why are XML tags so good in Cloud? I think initially people were like, oh, maybe you're just getting lucky with XML. But I saw obviously you use them in your own agent prompts, so they must work. And why is it so model specific to your family?
Erik [00:36:26]: Yeah, I think that there's, again, I'm not sure how much I can say, but I think there's historical reasons that internally we've preferred XML. I think also the one broader thing I'll say is that if you look at certain kinds of outputs, there is overhead to outputting in JSON. If you're trying to output code in JSON, there's a lot of extra escaping that needs to be done, and that actually hurts model performance across the board. Versus if you're in just a single XML tag, there's none of that sort of escaping that
Swyx [00:36:58]: needs to happen.
Erik [00:36:58]: That being said, I haven't tried having it write HTML and XML, which maybe then you start running into weird escaping things there. I'm not sure. But yeah, I'd say that's some historical reasons, and there's less overhead of escaping.
Swyx [00:37:12]: I use XML in other models as well, and it's just a really nice way to make sure that the thing that ends is tied to the thing that starts. That's the only way to do code fences where you're pretty sure example one start, example one end, that is one cohesive unit.
Alessio [00:37:30]: Because the braces are nondescriptive. Yeah, exactly.
Swyx [00:37:33]: That would be my simple reason. XML is good for everyone, not just Cloud. Cloud was just the first one to popularize it, I think.
Erik [00:37:39]: I do definitely prefer to read XML than read JSON.
Alessio [00:37:43]: Any other details that are maybe underappreciated? I know, for example, you had the absolute paths versus relative. Any other fun nuggets?
Erik [00:37:52]: I think that's a good sort of anecdote to mention about iterating on tools. Like I said, spend time prompt engineering your tools, and don't just write the prompt, but write the tool, and then actually give it to the model and read a bunch of transcripts about how the model tries to use the tool. I think by doing that, you will find areas where the model misunderstands a tool or makes mistakes, and then basically change the tool to make it foolproof. There's this Japanese term, pokayoke, about making tools mistake-proof. You know, the classic idea is you can have a plug that can fit either way, and that's dangerous, or you can make it asymmetric so that it can't fit this way, it has to go like this, and that's a better tool because you can't use it the wrong way. So for this example of absolute paths, one of the things that we saw while testing these tools is, oh, if the model has done CD and moved to a different directory, it would often get confused when trying to use the tool because it's now in a different directory, and so the paths aren't lining up. So we said, oh, well, let's just force the tool to always require an absolute path, and then that's easy for the model to understand. It knows sort of where it is. It knows where the files are. And then once we have it always giving absolute paths, it never messes up even, like, no matter where it is because it just, if you're using an absolute path, it doesn't matter where
Swyx [00:39:13]: you are.
Erik [00:39:13]: So iterations like that, you know, let us make the tool foolproof for the model. I'd say there's other categories of things where we see, oh, if the model, you know, opens vim, like, you know, it's never going to return. And so the tool is stuck.
Swyx [00:39:28]: Did it get stuck? Yeah. Get out of vim. What?
Erik [00:39:31]: Well, because the tool is, like, it just text in, text out. It's not interactive. So it's not like the model doesn't know how to get out of vim. It's that the way that the tool is, like, hooked up to the computer is not interactive. Yes, I mean, there is the meme of no one knows how to get out of vim. You know, basically, we just added instructions in the tool of, like, hey, don't launch commands that don't return.
Swyx [00:39:54]: Yeah, like, don't launch vim.
Erik [00:39:55]: Don't launch whatever. If you do need to do something, you know, put an ampersand after it to launch it in the background. And so, like, just, you know, putting kind of instructions like that just right in the description for the tool really helps the model. And I think, like, that's an underutilized space of prompt engineering, where, like, people might try to do that in the overall prompt, but just put that in the tool itself so the model knows that it's, like, for this tool, this is what's relevant.
Swyx [00:40:20]: You said you worked on the function calling and tool use before you actually started this vBench work, right? Was there any surprises? Because you basically went from creator of that API to user of that API. Any surprises or changes you would make now that you have extensively dog-fooded in a state-of-the-art agent?
Erik [00:40:39]: I want us to make, like, maybe, like, a little bit less verbose SDK. I think some way, like, right now, it just takes, I think we sort of force people to do the best practices of writing out sort of these full JSON schemas, but it would be really nice if you could just pass in a Python function as a tool. I think that could be something nice.
Swyx [00:40:58]: I think that there's a lot of, like, Python- There's helper libraries. ... structure, you know. I don't know if there's anyone else that is specializing for Anthropic. Maybe Jeremy Howard's and Simon Willis's stuff. They all have Cloud-specific stuff that they are working on. Cloudette. Cloudette, exactly. I also wanted to spend a little bit of time with SuiteAgent. It seems like a very general framework. Like, is there a reason you picked it apart from it's the same authors as vBench, or?
Erik [00:41:21]: The main thing we wanted to go with was the same authors as vBench, so it just felt sort of like the safest, most neutral option. And it was, you know, very high quality. It was very easy to modify, to work with. I would say it also actually, their underlying framework is sort of this, it's like, you
Swyx [00:41:39]: know, think, act, observe.
Erik [00:41:40]: That they kind of go through this loop, which is like a little bit more hard-coded than what we wanted to do, but it's still very close. That's still very general. So it felt like a good match as sort of the starting point for our agent. And we had already sort of worked with and talked with the SWE-Bench people directly, so it felt nice to just have, you know, we already know the authors. This will be easy to work with.
Swyx [00:42:00]: I'll share a little bit of like, this all seems disconnected, but once you figure out the people and where they go to school, it all makes sense. So it's all Princeton. Yeah, the SWE-Bench and SuiteAgent.
Erik [00:42:11]: It's a group out of Princeton.
Swyx [00:42:12]: Yeah, and we had Shun Yu on the pod, and he came up with the React paradigm, and that's think, act, observe. That's all React. So they're all friends. Yep, yeah, exactly.
Erik [00:42:22]: And you know, if you actually read our traces of our submission, you can actually see like think, act, observe in our logs. And we just didn't even change the printing code. So it's like doing still function calls under the hood, and the model can do sort of multiple function calls in a row without thinking in between if it wants to. But yeah, so a lot of similarities and a lot of things we inherited from SuiteAgent just as a starting point for the framework.
Alessio [00:42:47]: Any thoughts about other agent frameworks? I think there's, you know, the whole gamut from very simple to like very complex.
Swyx [00:42:53]: Autogen, CooEI, LandGraph. Yeah, yeah.
... [Content truncated due to size limits]