April 2026 PDC State of Data Modeling Survey Results Are In!
 Practical Data Modeling·
Practical Data Modeling· I ran a pulse survey on data modeling through the Practical Data community in mid-April 2026. 334 responses came back. There were only six single-select questions, one optional open-text field, anonymous, and no demographic gating beyond role. The entire pulse survey was designed to take about 90 seconds to complete. It’s a pulse survey, after all.
Here’s the numbers keep coming back to. When I asked “what would most improve data modeling at your organization?” - single-select, single-choice - this is what came back:
Practical Data Modeling is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Training and education on modeling best practices - 28.1%
Clearer business requirements upfront - 24.6%
More time allocated for modeling work - 21.6%
Dedicated ownership (a person or team) - 21.0%
Better tooling - 4.8%
Read that again. 95.2% of working data practitioners pointed to training, people, time, requirements, or ownership. One in twenty pointed at tools. I’ll let that sink in for a bit. If you’ve sat through a vendor pitch in the last twelve months, this number should annoy somebody. Probably some vendors. Almost certainly not the practitioners answering the pulse survey.
Who actually owns this?
The next question gets to the mechanism. I asked who owns data modeling decisions on the team. Four in ten respondents (42.5%) said, “Whoever is building the pipeline or data transformation.” Another 7.8% said, “Nobody. Models emerge organically. Roughly half the field works in environments where data modeling has no real owner. Only 19.2% have a dedicated modeler or architect.
Let’s dive into the “Whoever is building the pipeline or data transformation.”
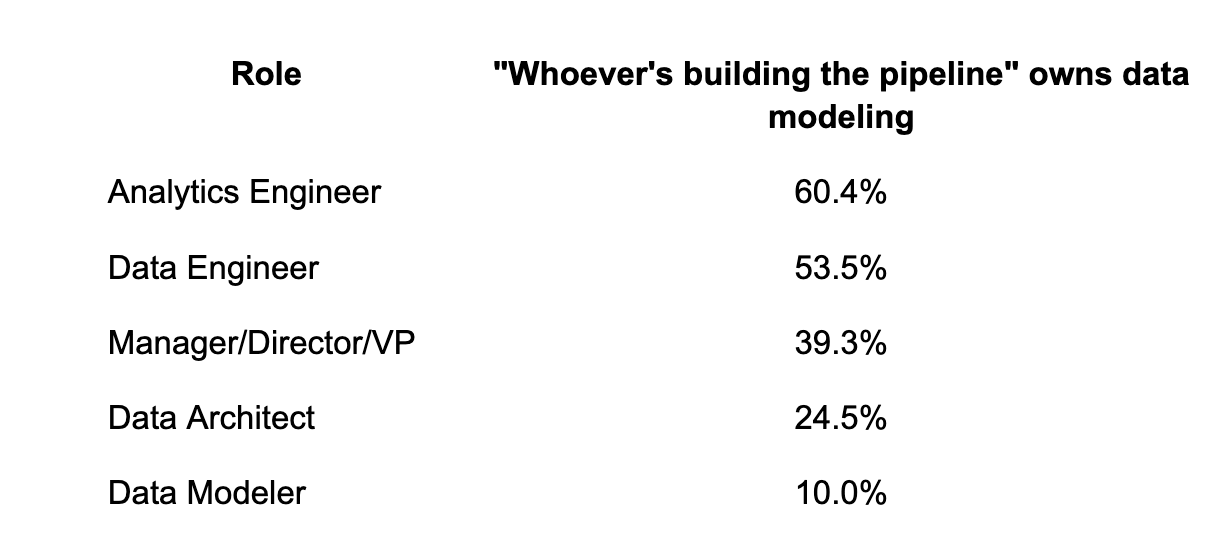
In shops led by Data Engineers and Analytics Engineers - which is most of them - modeling is a side effect of pipeline work. It happens when somebody needs to ship something, by whoever is shipping it. Where Data Architects and Modelers actually sit in the org chart, modeling becomes a discipline. Where they don’t, it doesn’t.
One respondent put it more plainly than I could:
One person can build the architecture. One person can’t make a team use it. The ungoverned path has no bottleneck, so that’s where models get built.
Another, even shorter:
It’s not a modeling problem, it’s an ownership problem.
The January State of Data Engineering Survey (n=1,101) flagged “lack of clear ownership” as the #2 data modeling pain point, behind only “pressure to move fast.” The April 2026 survey tells you more about why this is. The ownership question stays unsolved because half the field doesn’t have anyone in the room whose job description includes the word “model.”
Why your models break
I asked the breakdown question as a single-select, forced-choice question. Here’s the distribution:

62.5% of the breakdown reasons reduce to some flavor of “we didn’t have time, then we didn’t have time, then we ran out of time.” This is essentially the same finding the January survey produced when it said 59.3% of practitioners cite “pressure to move fast” as their top modeling pain, just decomposed into the moment of original sin (built under pressure) and the moment of accumulated debt (requirements drifted, nobody refactored).
The refactor data backs this up. Only 31.7% of teams refactor models regularly or weekly. The rest (68.3%) occasionally, rarely, or never refactor. 33.8% specifically said, “Rarely (only when something breaks)”
One respondent captured the cycle in a sentence:
Building on a very bad data model foundation but there is no time to fix it.
Another laid out the irony:
When GTM becomes the top priority, data modeling is often deprioritized as “non-essential.” Ironically, that decision is what ends up hurting GTM timelines and quality the most.
And my favorite framing of the whole survey, which I’ll be stealing:
Give me six hours to chop down a tree and I’ll spend the first four hours sharpening the axe. It’s time well spent to have the model upfront due to faster development due to understanding the relationships and requirements, and less rework needed by having a model.
Modeling is what makes speed possible. The teams skipping the model in the name of speed are the same teams firefighting six months later, which is exactly where the January survey caught them: 26.2% of teams report fighting fires as a significant time sink, and the correlation between ad-hoc modeling and firefighting was the strongest in the dataset.
What actually works (and yes, something does)
The pulse asked whether teams had a formal modeling standard or style guide. Only 18.9% said yes, well-documented and enforced. 32.9% said yes, but loosely followed. 23.7% said no, but we’ve talked about it. 24.6% said no, and it hasn’t come up.
The interesting part is what happens when you cross-tab standards against the breakdown question. Look at how often each group says their models hold up well:

Teams with enforced standards are roughly five times more likely to say their models hold up than teams with loose or no standards. The slight bump among the “no and hasn’t come up” group is probably honest ignorance. I’m guessing those teams haven’t noticed what’s broken yet. The teams actively talking about standards but not enforcing them are aware that their state is bad, and their models prove it.
One respondent described what enforced standards actually look like in practice, and I want to quote it in full because it’s the closest thing to a how-to in the entire response set:
Having clear modelling standards from the start of shifting to the cloud a few years ago, a solid conceptual data model as a planning basis for all new models, concerted knowledge sharing of good modelling practices, and documentation side by side with the code (ie. dbt yml files), and decent review process has meant our marts have been really solid and re-usable for many different purposes. Has saved us a ton of time in the long run and is leading to significant increase in trust from the rest of the business.
Standards. Conceptual model. Docs next to code. Review process. Trust. Nothing in that paragraph requires a new platform. It just requires time and investment in better practices.
AI is here, and not the interesting story anymore
The March pulse survey told us AI tooling has saturated personal practice. Claude was the #1 AI tool at 49%, and 82% of practitioners in the January survey reported using AI daily or more frequently. Individual productivity is a solved problem for anyone who wants to solve it.
The April pulse asks the natural follow-up question: now that we can all write code faster, what’s the bottleneck? The answer is upstream of the keyboard. It’s in the room where someone is supposed to decide what gets built.
The open-text responses split cleanly into two camps on AI and modeling.
Camp one says AI is making the modeling problem worse:
Data modelling was being neglected at the best of times. AI will only accelerate that unfortunately.
Architects and leaders are AI focused, no one has bandwidth to drive standards alignment, and there’s no reward for anything that isn’t AI.
There’s added pressure to move fast with the AI tooling adoption, but lesser thought into clearing up the “what” of the requirement.
Camp two says AI is finally forcing the modeling conversation that should have happened a decade ago:
We are pitching a data model to staff this week, and our biggest selling point is getting a semantic model for AI tooling.
CIO doesn’t want to wait for modeled data before hooking up Claude to Snowflake so he can make his own dashboards. My team is trying to ramp up on modeling best practices quickly so we can use well modeled data in semantic layers.
Both camps are right. The same forcing function pushing leadership to skip modeling is also the one that’s going to make them regret it. Whoever wins this argument in your org over the next twelve months will determine where you are in three years.
The most experienced respondent in the entire pool (45 years teaching concept modeling) wrote this:
No matter what the Silver Bullet (currently AI) everyone comes around to realising concept modelling is fundamental.
He’s been waiting his whole career for the field to catch up. Some of us are about to learn the lesson he’s been trying to teach since before most of us were born.
What the field actually sounds like
I’m going to give the floor to practitioners for a minute. For the April 2026 survey, 142 of the 334 respondents took the time to write an open-text response. A 42.5% completion rate on an optional field is high, and the responses were often long. People had things to say (the shorter ones shown here).
On the state of modeling as a craft:
It is a lost art. We need to bring it back. “No model, no decision.”
I interview a lot of people all the time. Data modelling is becoming a forgotten craft.
Very few people are taught it and it’s difficult to recruit people with the skills and knowledge. They know the technologies but not the theory.
Education lack is an important factor. Data modeling in the classical sense is under-represented in universities and schools.
On what passes for modeling in the wild:
Kimball is very loosely followed. Data “modeling” is nothing but creating semi-thoughtout fact and dimensions in dbt. And what are business ontologies? Ain’t nobody got time for that!
It is horrible at our company. They think Visio is a data modeling tool. So many existing systems have no data documentation.
My concern is most PBI developers don’t know what a star schema is, and try to DAX their way to plotted values.
On the organizational dynamics:
Data modelling is the worst in big orgs. Lack of knowledge and lack of ownership. Just plugging back bad models to make the Power BI work without data validation. Medallion architecture and AI are thrown as buzzwords. Really contemplating leaving the field altogether, but the money is good.
Our data modeling was originally owned by one person, me. Over time, we hired more both inside the data space and other data-interested leadership roles. We were pressured to pump out tables faster and were intentionally siloed to get rid of the “bottleneck” of data modeling by newer, more ambitious VP-level hires.
As DEs it feels like we’re expected to write the data contract for our upstream providers, who are yet never held accountable for it. Our pipelines are expected to both be flexible and follow a tight spec. Makes me feel too incompetent and helpless to take as much ownership as I would like.
And the line that should probably be the title of a future talk:
It’s the Wild West and when pressured by stakeholders it becomes a hellish Wild West.
So what?
The January survey told us the pain points of data practitioners and leaders. The March pulse told us how saturated AI tooling has become. AI’s here, and not the interesting story anymore. The April pulse closes the loop on data modeling (for now). Practitioners have already diagnosed the problem and told us on the record that they don’t need new tools. They need training, time, requirements, and somebody whose job it is to own this.
If you’re a vendor reading this, the 4.8% number will inform every conversation I have with you over the next six months. If your product is genuinely a process or training accelerant, great. If it’s another platform that promises to solve modeling by abstracting it away with AI agents, without addressing or complementing the core issues that teams face (training, time, ownership, etc), you’re selling against reality.
If you’re a practitioner, the survey is permission to push back. Email it. Walk into the meeting. 334 of your peers replied, and I’m just the messenger.
If you’re a leader, the call is simpler. You have two choices in 2026. You can keep treating data modeling as overhead and watch the AI initiatives bend around the same broken foundation that’s been bending your BI initiatives for a decade. Or you can name an owner, give them air cover, fund the standards work and training, and let your team build something durable.
The fundamentals haven’t changed. They’re not going to. AI made them more important, not less. And the practitioners in your org have been trying to tell you for a year.
We listened. Now it’s your move.
Also, I’m going to kick off a half-year survey soon. Stay tuned.
The April 2026 Practical Data Modeling Pulse Survey collected 334 anonymous responses through the Practical Data community between April 14 and April 27, 2026. It is a self-selected sample, not a matched panel against the January State of Data Engineering Survey (n=1,101) or the March AI Tooling Pulse (n=194).
The full April dataset is here. Podcast follow-up dropping later this week or next.
Practical Data Modeling is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.